
When it comes to tech jargon, one thing seems to always hold true: everyone has a different opinion about what certain words mean. I realize this fact every once in awhile; most recently, I came across it while trying to learn a new distributed systems concept.
The term “partition” is used a lot in distributed system courses and books, but there are also a slew of other terms that get lumped into this category as well. Until recently, I thought I knew what the term meant in the context of a distributed system, but as it turns out, there was more to the story — and the word — than I ever realized! As I did more research, I realized that the term is used to talk about two very different concepts, both of which end up being crucial to understanding how to deal with and architect a distributed system.
As Richard Feynman once wisely said, “names don’t constitute knowledge”. Just because people in the industry throw around a term doesn’t mean that they all necessarily know what it means, or how it can chance depending on the context! So let’s try and clear up some of this confusion and gain some real knowledge on this topic.
Parsing the meaning of partitioning
Before we get too deep into partitioning within a system, let’s first make sure we’re on the same page about what the word even means! When we talk about partitioning something, we are dividing it up, breaking it up into parts and separating it.

At its core, that’s all that partitioning really is: taking the whole of something and turning it into smaller pieces of itself. So far, not too complicated, right? But what does this same term mean in the context of a distributed system? Well, we can infer that the distributed system must, in some way, be the “whole” thing that we are separating, dividing up, and breaking into smaller pieces of itself.
But this simple act can actually take two different forms, depending on the kind of partition we are creating. As we already know, a distributed system is made up of nodes; so, if we are dividing up the system into parts, perhaps we are dividing up the nodes? But there’s another interpretation of “partition” here, too. Rather than dividing up the nodes, perhaps we are dividing the system into smaller groups of nodes such that we are breaking up one large system into smaller subsystems. If we think about it, both of these approaches are two valid forms of partitioning.
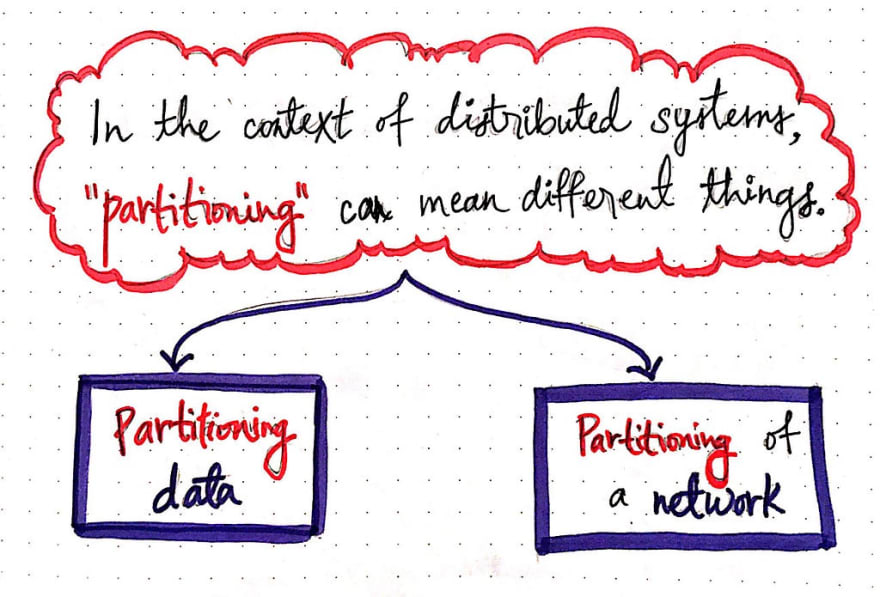
As it turns out, this is where things can get confusing. When dealing with a distributed system, “partitioning” can mean different things. First, it could imply the partitioning of data in the system, or dividing up the nodes into smaller pieces of themselves. But, it could also mean partitioning the system itself by partitioning the network that the system communicates through. This would mean breaking up the way that the nodes in the system talk to each other and separating them into smaller subsystems or subnetworks.
The interesting thing about these two forms of partitioning in a system is that one is intentional, while the other is more of a side effect that we need to deal with. But more on that soon. It’s important to understand the difference between the two because the same term can sometimes be used to refer to either! So let’s dig into these two forms of partitioning and understanding the reasons behind why each happen.
Separating data
The idea of partitioning the nodes in a system might seem odd at first, but we’ve we’ve actually seen something sort of adjacent to this before. Remember when we learned about redundancy and the replication of nodes? That concept also might have seemed weird initially — why would anyone want to repeat themselves?! — but as we started to unpack it further, we saw that there were some clear benefits to it.
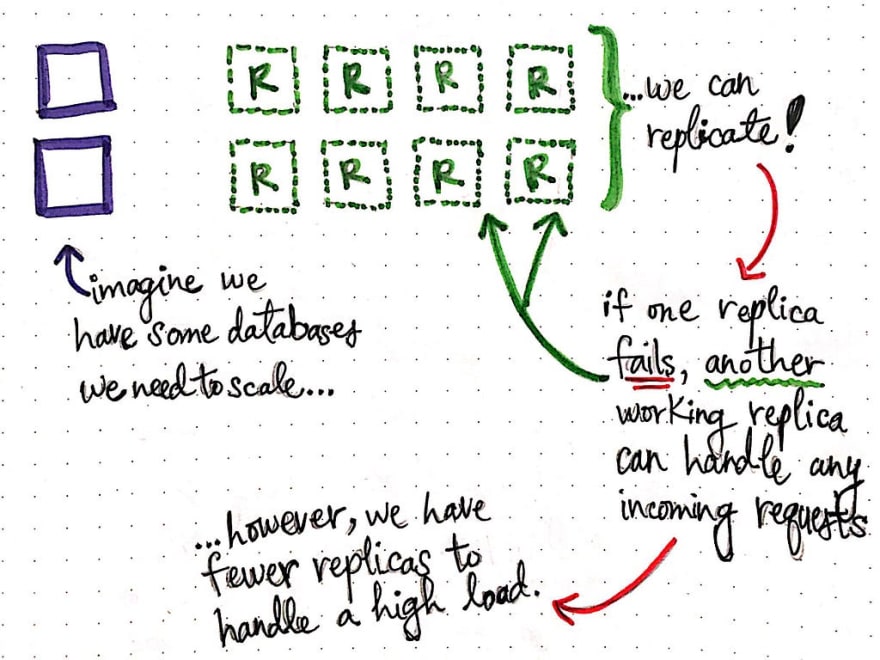
As we have already learned, when we need to make some of our nodes more reliable or when we need to scale some part of our system (like a database), we can replicate our nodes to create more copies of the same data that are in sync with the original node. That way, if one replica fails, another working replica can handle incoming requests for some data. Overall, replication allows for a system that is more transparent, reliable, and much easier to scale.
There are some caveats with replication, however. We already know that keeping replicas consistent is a major challenge. But what happens if our replicas suddenly need to deal with a high load of incoming requests? It is possible that a few replicas could fail, and any user that is depending on the replica would potentially not be able to access any of the data at that replica (at least until another replica was able to come and take its place).
This presents a new challenge with replication: while most of users can access all of our data through working replicas, for a portion of users, all of our data could be completely unavailable if the replica that those users are accessing happens to fail.
But what if we had a very large data set? One that would make us think twice before replicating it? This is where we might want to employ a different strategy…like partitioning our data!

In some situations where a dataset is so large that it cannot all fit on a single node, we can opt to partition our data.
Partitioning data across nodes means that our data is distributed across our nodes; no single node can contain all of our data. Conversely, if we wanted to retrieve all of the data, we’d need to go to every single node to get it.
Depending on what a dataset looks like and what pieces of data are related to one another, it may make sense to lump certain types of data together onto a single node. For example, in a system that shows posts and the related comments on a page, it might make logical sense to always put the data for a post and all of its comments together on the same node, so that our users wouldn’t need to make two requests to fetch two kinds of data in two different nodes.
There are lots of strategies for determining what data should live on which node. Two terms that we might come across to describe this idea are sharding and fragmentation. Both terms are used interchangeably to describe the idea of partitioning a dataset across many different nodes (we won’t go into detail about the actual implementations of these techniques in this post).

The important thing to note here is that whenever we see the terms “sharding” or “fragmentation”, the context is usually a partitioned database (since databases are generally where our datasets will live!). Oftentimes, databases live on multiple servers and are distributed, themselves (pretty neat, right?). So, when we encounter a situation where a database is fragmented and split it into shards, what we are really dealing with is one big dataset that has been split into shards , or smaller sets/fragments, and have been distributed across nodes.
A single database node contains just one portion of a larger dataset. When more data gets added or if the dataset changes significantly, it might need to be re-partitioned into new shards across all the nodes.

So how does this fit in with our mental model of replication?
Well, to start, there is one major similarity to note here: both partitioning and replication improve the performance and reliability of our system. This is simply due to the fact that having more nodes — whether they are replicas that contain all the same data, or whether they are partitions that contains some of the data — mean that the load on a single node reduces! When we add more replicas OR partitions, we effectively spread out the incoming requests for data, which helps our system scale and makes it much more performant and available to our end users.
But what about the differences between these two strategies? Replication guarantees that our end user can always read our whole dataset, because all of the data lives on each replica. On the other hand, partitioning guarantees that some of the data will be retrievable, but there is no guarantee that our end user can always retrieve the data they need if one of the partitions fails!
Another difference between replication and partitioning are the things that make them difficult! Replication is hard because it’s tricky to maintain consistency between our replicas. Partitioning is hard for two reasons: first, if our dataset changes and we need to suddenly re-partition it…well, this is no easy task. Deciding how to divide up data takes time and effort, and we definitely don’t want to be re-partitioning it all the time! Second, depending on how it is implemented, it can sometimes be ineffective. For example, if we some highly-used data that is partitioned into one node, we actually end up in a worse situation than before we partitioned the data. Why is that?
Well, imagine that all of our end users suddenly request that highly-used data at once, and the node can’t handle the high load? Or what if that one database node with the highly-used data fails? Now our end users can’t access this important partition! So it’s up to us to consider all of these potential downsides when determining the tradeoffs of these two strategies. To avoid some of the heartache that’s associated with making these decisions, many production-level distributed systems will use replication when possible, and opt for partitions only when necessary.
Dividing a network
Now that we know the ins and outs of what it means to partition data, we have one last thing to unpack: the idea behind partitioning the network. Don’t feel too intimidated, though, this isn’t a completely new topic for us. In fact, I’ll let you in on a little secret, though — we’ve already seen the effects of a partitioned network!
We’ve learned about the many different failure modes in this series, and as it turns out, network partitioning is actually just one form of failure in a distributed system. It occurs when a network is split up into fragments, and subsequently creates sub-networks within itself. The important bit to call out here is that it is a network fault (also called a network split ) that breaks the usual communication between nodes in the network.

However, this doesn’t mean that all the nodes in the network cannot communicate; the only ones that can’t communicate to one another are the ones surrounding the split. This means that if a network split occurs between two nodes, those two nodes can’t talk to one another, but they can continue to talk to other nodes that are not impacted by the split.
When the node connection is interrupted by a network fault, it creates subnetworks that are “partitions” of the larger network — an unintentional division of the network, if you will.

For example, in the drawing shown here, a network failure has caused a network partition (also called a fragmentation ). The point of the fragmentation forces our network to be divided into two subnetworks , which we’ve named A and B. The nodes of subnetwork A can keep talking to one another, and the nodes of subnetwork B can keep processing data and sending information between themselves. However, any of the nodes between subnetworks A and B have been fragmented, which means that they can’t talk to one another! This means that subnetwork A cannot talk to or even know the state of subnetwork B (and vice versa).
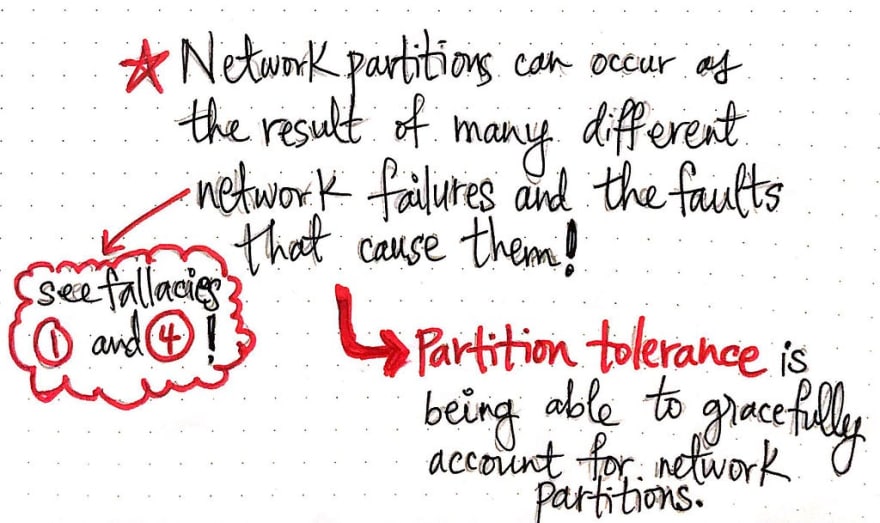
Now, if this situation sounds bad, you’re right — it is! We don’t want our network to randomly break and cause parts of our system to be isolated from one another. Clearly, a partitioned network is something to avoid. However, do you remember back when we learned about the 8 Fallacies of Distributed Computing? If we think back to fallacy #1 (“The network is reliable.”) and Fallacy #4 (“The network is secure.”) then we’ll come face to face with the hard truth: network partitions are unavoidable.
So what can we do? Well, we can design our systems to try to handle them gracefully when they (inevitably) happen! This is similar to the conclusion that we came to when we were learning about fault tolerance, and how we are forced to consider faults and try to design our systems to handle them. Similarly, when it comes to network partitions, we need to plan for partition tolerance , which is they way that we consider the potential network faults that might pop up, as well as the failures that they might cause! A partition tolerant system is one that has attempted to account for network partitions, since we’ll all run into them eventually.
Although data partitions might be an avoidable problem to solve since we may not decided that we even need to partition our data, network partitions are something that we just cannot avoid. In fact, they’ll come up again later when start learning about some interesting…theorems. But that’s a story for another post! 😉
Resources
Partitioning and partition tolerance comes up quite often when learning more advanced distributed system topics, so it’s important to have a strong understanding of the fundamentals. Conveniently, there are some really great resources to help with this task. I’ve listed some of my favorites below, some of which get into even more advanced aspects of partitioning; check them out if you’re eager to learn more!
- Distributed systems cheat sheet, Dmitry Fedosov
- Partitioning: The Magic Recipe For Distributed Systems, Pranay Kumar Chaudhary
- Distributed systems for fun and profit, Mikito Takada
- Why are Distributed Systems so hard? A network partition survival guide, Denise Yu
- Replication vs Partitioning, Georgia Tech
- Jepsen: On the perils of network partitions, Kyle Kingsbury

Top comments (1)
Very interesting and good resources as well. Thanks.