
In this article, I'd like to cover some basic steps on how to get an Elasticsearch node up and running and how to connect, index, and search data in Elasticsearch from a Java application using the Spring Data Elasticsearch library.
I also describe some common tasks e.g How to index a field so that we can do search and order on the same field. How to build the query to search and filter on multiple fields.
Create a new Springboot Project
Whenever I need a new Springboot project, I go to start.spring.io to generate it. Here's my setup:

After choosing the desired project name, and dependencies, click Generate, then extract the downloaded zip file. In this example, the project directory is spring-data-elasticsearch-example
Ensure Elasticsearch is up and running
To get started, I need to have Elasticsearch running so that my application can connect.
One simple option is to start a single Elasticsearch node with docker-compose
Since I already have docker and docker-compose installed on my mac (Docker Desktop). I create a elasticsearch.yml file and start the Elasticsearch container with docker-compose:
Create elasticsearch.yml in src/main/docker
cd spring-data-elasticsearch-example
mkdir -p src/main/docker && touch src/main/docker/elasticsearch.yml
With the following content:
version: '2'
services:
my-elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.9.2
container_name: my-elasticsearch
# volumes:
# - ~/data/my-elasticsearch/:/usr/share/elasticsearch/data/
ports:
- 9200:9200
environment:
- 'ES_JAVA_OPTS=-Xms1024m -Xmx1024m'
- 'discovery.type=single-node'
Then start Elasticsearch container
docker-compose -f src/main/docker/elasticsearch.yml up -d
Elasticsearch is now up and running at http://localhost:9200/
More information can be found on the Elasticsearch documentation
Index data in ElasticSearch
Given that I have the following sample Entities: Book and Author. I would like to index all the Books and authors in an index called 'books'.
Create entities and define how we want to index
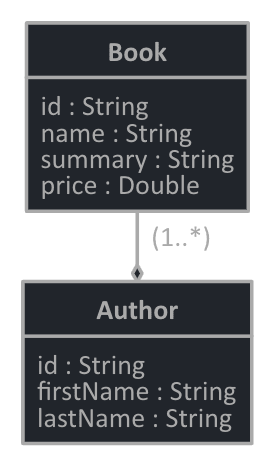
@Getter
@Setter
@Accessors(chain = true)
@EqualsAndHashCode
@ToString
@Document(indexName="books")
public class Book {
@Id
private String id;
@MultiField(
mainField = @Field(type = FieldType.Text, fielddata = true),
otherFields = {
@InnerField(suffix = "raw", type = FieldType.Keyword)
}
)
private String name;
@Field(type = FieldType.Text)
private String summary;
@Field(type = FieldType.Double)
private Double price;
@Field(type = FieldType.Object)
private List<Author> authors;
}
In Book entity, I use different annotations like @Document, @id, @Field, @MultiField to instruct Elasticsearch how I want that Entity, and Properties to be indexed.
-
@Document(indexName="books")indicates that I want to store the books in an index calledbooks. By default, the index mapping will be created I start the Java application. The @Document annotation has many attributes. More details can be found in the official documentation- shards: the number of shards for the index.
- replicas: the number of replicas for the index.
- createIndex: Configuration whether to create an index on repository bootstrapping. The default value is true.
@Id: used for identity purpose, this helps query the book by id or update an existing book in Elasticsearch.@Field: used for specifying the kind of data the field contains, such as strings or boolean values, and its intended use. The list of data types can be found in mapping-types documentation.
Additionally, analyzer, searchAnalyzer, and normalizer can be customized. In Elasticsearch, the standard analyzer is the default analyzer.
Here're how Book's properties are indexed using the above annotations:
summaryhas the Text type, and thepricehas the Double type.nameis indexed to both Text and Keyword fields using@MultiFieldannotation. The mainTextfield is analyzed for full-text search meanwhile the@InnerFieldrawisKeywordwhich will be left as-is in Elasticsearch and can be used for sorting (or filtering in case of Author's name below). Sincerawis an inner field, we can access it asname.raw.authorsis indexed as a nested JSON object.
The Author entity
@Getter
@Setter
@Accessors(chain = true)
@EqualsAndHashCode
@ToString
public class Author {
@Id
private String id;
@MultiField(
mainField = @Field(type = FieldType.Text, fielddata = true),
otherFields = {
@InnerField(suffix = "raw", type = FieldType.Keyword)
}
)
private String name;
}
The Author entity can contain other nested objects e.g Contacts but for this blog post, I keep it simple as is.
Similar to Book's name, Author's name is also indexed as Text (mainField) and Keyword (innerField raw) so that we can search on author.name field, and Filter and Sort on author.name.raw field.
Configure the High Level REST Client
The next step is configuring the connection to my running Elasticserach and creating the repository so that I can index and search for books.
@Configuration
@EnableElasticsearchRepositories(
basePackages = "dev.vuongdang.springdataelasticsearchexample.repository"
)
public class ElasticSearchConfig extends AbstractElasticsearchConfiguration {
@Override
@Bean
public RestHighLevelClient elasticsearchClient() {
final ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("localhost:9200")
.build();
return RestClients.create(clientConfiguration).rest();
}
}
It is required to configure the ClientConfiguration, however, the higher-level abstractions Elasticsearch Repositories are normally used in the application.
@EnableElasticsearchRepositories activates the Repository support for all repositories interfaces defined in the dev.vuongdang.springdataelasticsearchexample.repository package. Thanks to Spring Data Elasticsearch, I can define the interface, and the implementation will be handled automatically.
The ClienConfiguration above can be set options for SSL, connect and socket timeouts, headers, and other parameters. For example:
ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("localhost:9200")
.useSsl()
.withConnectTimeout(Duration.ofSeconds(5))
.withSocketTimeout(Duration.ofSeconds(3))
.withBasicAuth(username, password);
The above ClientConfiguration connects to localhost:9200. In case you use app.bonsai.io the configuration may look like this:
final ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("sass-testing-1537538524.eu-central-1.bonsaisearch.net:443")
.usingSsl()
.withBasicAuth("<username>", "<password>")
.build();
Create the Repository
/**
* Define the repository interface. The implementation is done by Spring Data Elasticsearch
*/
public interface BookSearchRepository extends ElasticsearchRepository<Book, String> {
List<Book> findByAuthorsNameContaining(String name);
}
Let's create a Test to illustrate how to use the Repository. I created 3 books, and then ensure these operations run properly: save, find by Id, and find by author's name.
@SpringBootTest
class BookServiceTest {
@Autowired
private BookService bookService;
@Autowired
private BookSearchRepository bookSearchRepository;
@Autowired
private ElasticsearchOperations elasticsearchOperations;
public static final String BOOK_ID_1 = "1";
public static final String BOOK_ID_2 = "2";
public static final String BOOK_ID_3 = "3";
private Book book1;
private Book book2;
private Book book3;
@BeforeEach
public void beforeEach() {
// Delete and recreate index
IndexOperations indexOperations = elasticsearchOperations.indexOps(Book.class);
indexOperations.delete();
indexOperations.create();
indexOperations.putMapping(indexOperations.createMapping());
// add 2 books to elasticsearch
Author markTwain = new Author().setId("1").setName("Mark Twain");
book1 = bookSearchRepository
.save(new Book().setId(BOOK_ID_1).setName("The Mysterious Stranger")
.setAuthors(singletonList(markTwain))
.setSummary("This is a fiction book"));
book2 = bookSearchRepository
.save(new Book().setId(BOOK_ID_2).setName("The Innocents Abroad")
.setAuthors(singletonList(markTwain))
.setSummary("This is a special book")
);
book3 = bookSearchRepository
.save(new Book().setId(BOOK_ID_3).setName("The Other Side of the Sky").setAuthors(
Arrays.asList(new Author().setId("2").setName("Amie Kaufman"),
new Author().setId("3").setName("Meagan Spooner"))));
}
/**
* Read books by id and ensure data are saved properly
*/
@Test
void findById() {
assertEquals(book1, bookSearchRepository.findById(BOOK_ID_1).orElse(null));
assertEquals(book2, bookSearchRepository.findById(BOOK_ID_2).orElse(null));
assertEquals(book3, bookSearchRepository.findById(BOOK_ID_3).orElse(null));
}
@Test
public void query() {
List<Book> books = bookSearchRepository.findByAuthorsNameContaining("Mark");
assertEquals(2, books.size());
assertEquals(book1, books.get(0));
assertEquals(book2, books.get(1));
}
}
In the beforeEach method, I recreate the index and insert 3 books to ensure that every test I have fresh new data.
You can go to localhost:9200/books/_search to see all the indexed books.
Or go to localhost:9200/books/_mapping to see the detailed mapping of each field.
Search and Filter
In BookSearchRepository, I can name a method and it will be resolved to Elasticsearch JSON query automatically. Another way is to define the JSON query using @Query annotation. For example:
@Query("{\"match\": {\"name\": {\"query\": \"?0\"}}}")
Page<Book> findByName(String name, Pageable pageable);
These are awesome for simple queries, but in practice, we usually provide the end user with a search field, some filters, and sorting. To achieve this I prefer using the built-in query builder because of its flexibility.
Let's create a BookService to illustrate how to use query builder to form a complex query for searching on multi fields, filtering and sorting
@Service
public class BookService {
@Getter
@Setter
@Accessors(chain = true)
@ToString
public static class BookSearchInput {
private String searchText;
private BookFilter filter;
}
@Getter
@Setter
@Accessors(chain = true)
@ToString
public static class BookFilter {
private String authorName;
}
@Autowired
private ElasticsearchOperations operations;
public SearchPage<Book> searchBooks(BookSearchInput searchInput, Pageable pageable) {
// query
QueryBuilder queryBuilder;
if(searchInput == null || isEmpty(searchInput.getSearchText())) {
// search text is empty, match all results
queryBuilder = QueryBuilders.matchAllQuery();
} else {
// search text is available, match the search text in name, summary, and authors.name
queryBuilder = QueryBuilders.multiMatchQuery(searchInput.getSearchText())
.field("name", 3)
.field("summary")
.field("authors.name")
.fuzziness(Fuzziness.ONE) //fuzziness means the edit distance: the number of one-character changes that need to be made to one string to make it the same as another string
.prefixLength(2);//The prefix_length parameter is used to improve performance. In this case, we require that the first three characters should match exactly, which reduces the number of possible combinations.;
}
// filter by author name
BoolQueryBuilder filterBuilder = boolQuery();
if(searchInput.getFilter() != null && isNotEmpty(searchInput.getFilter().getAuthorName())){
filterBuilder.must(termQuery("authors.name.raw", searchInput.getFilter().getAuthorName()));
}
NativeSearchQuery query = new NativeSearchQueryBuilder().withQuery(queryBuilder)
.withFilter(filterBuilder)
.withPageable(pageable)
.build();
SearchHits<Book> hits = operations.search(query, Book.class);
return SearchHitSupport.searchPageFor(hits, query.getPageable());
}
}
To test this BookService#searchBook, I add one more test method to BookServiceTest above
@Test
void searchBook() {
// Define page request: return the first 10 results. Sort by book's name ASC
Pageable pageable = PageRequest.of(0, 10, Direction.ASC, "name.raw");
// Case 1: search all books: should return 3 books
assertEquals(3, bookService.searchBooks(new BookSearchInput(), pageable)
.getTotalElements());
// Case 2: filter books by author Mark Twain: Should return [book2, book1]
SearchPage<Book> booksByAuthor = bookService.searchBooks(
new BookSearchInput().setFilter(new BookFilter().setAuthorName("Mark Twain")),
pageable); // sort by book name asc
assertEquals(2, booksByAuthor.getTotalElements());
Iterator<SearchHit<Book>> iterator = booksByAuthor.iterator();
assertEquals(book2, iterator.next().getContent()); // The Innocents Abroad
assertEquals(book1, iterator.next().getContent()); // The Mysterious Stranger
// Case 3: search by text 'special': Should return book 2 because it has summary containing 'special'
// one typo in the search text: (specila) is accepted thanks to `fuziness`
SearchPage<Book> specialBook = bookService
.searchBooks(new BookSearchInput().setSearchText("specila"), pageable);// book 2
assertEquals(1, specialBook.getTotalElements());
assertEquals(book2, specialBook.getContent().iterator().next().getContent()); // The Innocents Abroad
}
Please notice in Case 3 above, the search text has one typo it is specila instead of special. But it works as expected because I set .fuzziness(Fuzziness.ONE) in the query builder.
Logging
I find it useful to log the JSON query on the development environment to ensure that we produce proper queries. This log can be enabled in the application.properties
logging.level.org.springframework.data.elasticsearch.client.WIRE=trace
Now when I run the searchBook test method, I can see the Elasticsearch query in the log file as below:
{
"from": 0,
"size": 10,
"query": {
"multi_match": {
"query": "special",
"fields": [
"authors.name^1.0",
"name^3.0",
"summary^1.0"
],
"type": "best_fields",
"operator": "OR",
"slop": 0,
"fuzziness": "1",
"prefix_length": 2,
"max_expansions": 50,
"zero_terms_query": "NONE",
"auto_generate_synonyms_phrase_query": true,
"fuzzy_transpositions": true,
"boost": 1.0
}
},
"post_filter": {
"bool": {
"adjust_pure_negative": true,
"boost": 1.0
}
},
"version": true,
"sort": [
{
"name.raw": {
"order": "asc"
}
}
]
}
Conclusion
In this blog post, I cover the following topics:
- Get ElasticSearch up and running
- Configure a Springboot project to work with Elasticsearch
- Index a POJO object
- Create index and mapping in Elasticsaerch
- Search, Filter and Sort using Spring Data Elasticsearch
The example source code can be found here in Github

Top comments (0)