
If you thinking of using Azure Cosmos DB for your applications, you’ll need to understand how partitioning works to ensure that you don’t suffer from performance issues such as throttling. By having an effective partitioning strategy, we can ensure that our Cosmos databases can meet the performance requirements of that our applications demand. But how does partitioning work in Cosmos DB?
In order to scale containers within a database that meets the performance requirements that our applications needs, Cosmos DB uses partitioning. Items in our containers are divided into logical partitions which are based on partition keys that we associate with each item in a container.
Say if we have a story container that holds individual news stories and we have a partition key for news category and there are 10 unique values for a news categories, there will be 10 logical partitions created for story container.
Along with a partition key, each item in a container has a item ID with is unique within a logical partition. The item index is this value combined with the partition key.
As you can probably guess from our introduction, choosing a partition key is vital to our application’s performance. So let’s have a look at some strategies that we can employ to ensure that we pick an effective partition key:
- As I mentioned in my previous blog post about throughput in Cosmos DB, requests to the same partition key can’t exceed the amount of throughput we have provisioned to the container or database. If we do, we’ll get some throttling. This is the same for partition keys. If we pick a partition key that has few distinct values, or if one value appears more frequently than others, this will result in ‘hot partitions’. This is where one partition will hog the amount of throughput required for Cosmos transactions at the expense of other partition values.
- To avoid ‘hot partitions’ we need to pick a partition key that has a wide range of values that spread evenly across logical partitions. This ensures that throughput and storage are spread evenly across our logical partitions.
- Picking a partition key that has a wide range of values helps us balance our workloads over time. The Azure documentation states that the partition key that we choose should be trade-off for efficient queries and transactions against the overall goal of distributing items across partitions.
- A good partition key would be a property that we frequently use as a filter in our Cosmos DB query.
- Choosing the right partition key allows us to effectively control the number of logical partitions, distribution of our data, throughput and workload.
Managing logical partitions
If you’re wondering how we need to place our logical partitions in our Cosmos DB accounts, you shouldn’t. Cosmos DB does this automatically to ensure performance on the container. As our application demands more throughput and storage, Cosmos moves logical partitions to spread the load across more servers.
This is achieved through the use of hash-based partitioning to spread logical partitions over physical ones. The partition key value of an item is hashed and that determines the physical partition. Cosmos will then allocate the key spaces of hashes evenly across physical partitions. Queries that access data within a single logical partition will be more cost-effective than queries that access multiple partitions.
What’s the difference between Logical and Physical partitions
Logical partitions are partitions that consist of a set of items that have the same partition key. So using our News Story container example, say if all our items have a “Category” property, we can use that as the partition key. Say if we have values for “Sport”, “Tech” and “Financial” categories, these group of items will form their own distinct logical partitions. If we need to delete the underlying data from a partition, we don’t need to delete the partition ourselves.
When we add data to our containers, the throughput and data are partitioned horizontally across a set of logical partitions based on the partition key that we have set on that container.
Physical partitions are partitions that our logical partitions map to. This sits within a replica set and each replica set hosts an instance of the Cosmos DB Engine. This ensures that the data stored within each physical partition is durable, consistent and highly available.
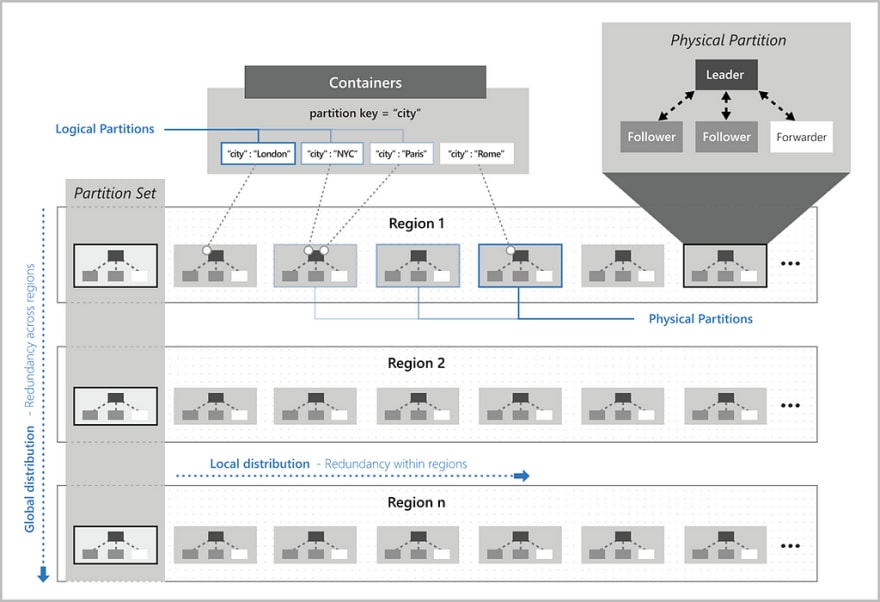
Physical partitions support the max amount of storage and request units. Each replica inherits the partition’s quota for storage and all replicas work together to support the throughput provisioned on the physical partition.
Physical partitions are the internal implementation of the system, meaning we can’t control the size, placement or count of them. We also can’t control the mapping between logical and physical partitions.
What’s a synthetic partition key and when can it help?
If you have an idea of what your items that you’re going to store within a container will look like and your ideal partition key is unlikely to have many distinct values, we can create synthetic partition keys to help us ensure that our containers don’t suffer from hot partitioning using a couple of strategies.
We could combine multiple properties of our item to make a single Partition Key property called a synthetic key. Let’s imagine that a News Item document in our News Story container looks like this:
Here’s we have properties for both NewsCategory and PublishDate. To create our synthetic partition key, we just concatenate these two values together to create our partition key:
We could apply a random suffix to our item to create a synthetic partition key. This option would be a good option to pick if we needed to write in parallel tasks across partitions.
Taking our News Item document as an example. we could choose a random number and append it to our NewsCategory property. Because our number is random, writes are spread evenly across multiple partitions benefiting from better parallelism. In the below example, we’ll create a partition key with a random suffix for our News Document. In this example, we’ll pick a random number between 1 and 1000. In production scenarios, you may want this to be more complex if you need it to be:
Finally, we could pre-calculate a suffix to append to our partition key property. Random suffixes help write operations, but can make read operations on specific items difficult. Using a pre-calculated suffix will make it easier to search since we will have some idea about what’s being calculated opposed to a random one.
Writes are evenly spread across partition key values and partitions, and we can read a particular item easier than you would with a random suffix. Using our News Story document as an example, we could use a version number for our document along with the date and apply that as our partition key as follows:
Wrapping up
Hopefully after reading this you have a better understanding of how partitioning works in Cosmos DB and the importance of choosing the right partition key for our collections to ensure reliable performance for our applications.
If I had to emphasize some key points that you should take away from this, it would be:
- Pick a partition key that has many distinct values to avoid ‘hot partitions’ from emerging in your containers.
- If the property you need to create your partition key doesn’t have or can’t have many distinct values, then look into creating a synthetic partition key to ensure that you don’t suffer from performance issues.

Top comments (4)
Will,
I’m experimenting with choosing the right partition key for my Cosmos DB graph database.
Every node has a unique id value (a deterministic SHA256 hash), and I chose to use that value as partition key as well.
This results in maximum cardinality, and it seems to provide a very good spread across the partitions.
I can’t find any articles discussing or recommending this approach though, so can I get your opinion?
Cheers,
-Nils
Hi Nils,
I think that approach misses out on a key intent of partition keys - logical grouping. I.e. if items tend to be fetched together, they ideally reside in the same partition. My source is this 15 min video which acted as my entry into Cosmos partition keys: youtube.com/watch?v=5YNJpGwj_Zs
Thx Joel :-)
Hi Will, Nice article, but I am interested in getting your take on a problem we have.
While choosing a partition key with sufficient cardinality ensures the documents can be distributed evenly to all available partitions, it only ensures the same for RU's if you can assume that all documents are equally likely to be accessed. In our case, we have use cases where we need to keep all the data online for a long time (years), but the probability of someone requesting any given document decreases over time. What we need is not just to have ALL the documents evenly distributed, but to make sure all of the MOST RECENT documents are evenly distributed. It is not enough that we have roughly the same number of documents in every partition. If the documents in many of the partitions are older and infrequently accessed while most of the most recent documents tended to congregate in one or a few partitions, we start seeing throttling. The only way we have to counter this today is to increase the RU's on the collection. Since the RU's are divided across all the partitions (including the ones not seeing much traffic), we end up wasting resources (and money). To get an extra 100 RU's on the partition that is throttling we have to increases the collection RU's by 100 * number of partitions, even further over-provisioning those partitions that are not seeing much activity. For large collections with many partitions, this is a lot of money.
We could imagine some solutions that might have worked had Cosmos DB used range partitioning on the partition key. We could leverage the time aspects inherent in the partition key (e.g. the one-up nature of an order id) itself to help balance the distribution. But with hash partitioning, we have been unable to come up with any strategy that gives us confidence these hot partitions won't suddenly appear because any time information inherent in the partition key is effectively erased by the hash operation (hash values of consecutive values are not necessarily consecutive).
This problem is not purely theoretical. We have observed this multiple times. The data looks pretty evenly distributed (volume-wise) across all partitions, but one or a few partitions are being throttled while many others sit almost idle.
Have you encountered such cases? Were you able to solve for them? Any thoughts on solutions? I am inclined to believe there is none ... but not ready to give up yet.
Thanks.
Bill Bailey