
Today I Learned — 03/05/2022
Falhas
Quando trabalhamos com sistemas distribuídos por rede é uma questão de tempo até que tenhamos uma falha. A falha pode ser transitória onde podemos simplesmente tentar repetir a chamada até que ela funcione mas para isso precisamos dar um tempo para que o servidor volte ao normal. Portanto não devemos continuar fazendo chamadas para o servidor nesse caso pois isso pode até contribuir para que o servidor não consiga voltar já que sempre que ele tentar reiniciar será bombardeado com requests que estavam esperando ser processados e acaba sendo derrubado novamente.
Problema
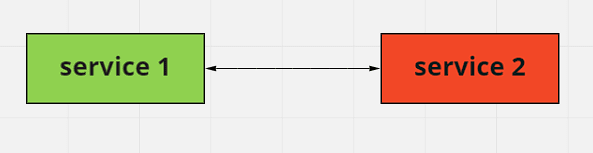
Caso o service 2 caia e todas as chamadas feitas pelo service 1
ficarem penduradas nele esperando uma resposta o que vai acontecer é que o service 1 vai cair junto, e por consequência todos os services que dependem do service 1 vão cair e por ai vai. Isso é chamado de Cascanding Failures
Solução: Circuit Breaker

Vamos configurar um total de chamadas que falham para abrir o circuito. Ex: 20, quando tivermos 20 falhas o circuito vai abrir e nem vai mais fazer as chamadas até determinado tempo, por exemplo 10 segundos, então depois de 20 chamadas para o service 2 falharem o 1 vai ficar 10 segundos sem fazer nenhuma chamada para o serviço. Qualquer nova comunicação com o service 2 falhará imediatamente, depois dos 10 segundos determinados ele vai deixar uma chamada passar para o serviço que estava fora, se ela retornar sucesso o circuito é fechado novamente e tudo volta ao normal, caso falhe o circuito continua aberto e aumentamos o tempo de espera para o novo teste, no nosso caso podemos considerar por exemplo 20 segundos para a próxima tentativa.
Esse pattern soluciona o problema do service 1 que não vai mais ficar esperando chamadas que vão falhar e soluciona também para o service 2 que não vai ser bombardeado com requests enquanto tenta voltar
Múltiplos clients
Problema
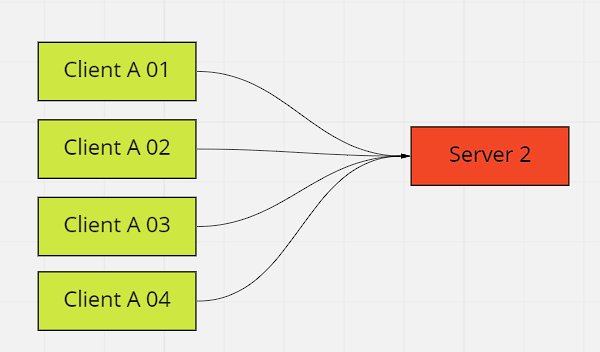
Tá mas e se tivermos mais de um client consumindo um servidor e esse servidor cair, vamos supor por exemplo que o client A 01 detecta que o servidor caiu e abre o circuito como o client A 02 iria descobrir que o servidor caiu? somente depois dele tentar fazer 20 chamadas e descobrir por conta própria que o servidor caiu. O que seria um problema, que fica maior para quantos mais clients possuímos consumindo o mesmo sistema
Solução: Cache compartilhado

Podemos utilizar um banco tipo Redis para que os clients sempre chequem antes de fazer a chamada se o circuito está aberto e então quando o primeiro client detectar que deve abrir o circuito, ele salva essa informação no redis, e então todos passam a saber que o circuito está aberto e eles não devem nem tentar continuar com a request. Nesse caso precisamos configurar o tempo de expiração no redis para ser como o tempo escalável da primeira solução, 10 segundos depois 20 segundos e vai seguindo.
Referencias: Patterns para comunicação resiliente: utilizando circuit breakers - https://app.rocketseat.com.br/experts-club/lesson/3-patterns-para-comunicacao-resiliente-utilizando-circuit-breakers

Top comments (2)
Nice article. I’d also take a look on this docs.aws.amazon.com/general/latest...
Thank you! I will try to read ASAP