
In my previous post, I introduced Project Nairobi, a distributed analytics platform I’m building on AWS to handle IoT data at scale. This time, I want to dive into the progress I’ve made so far—along with the headaches and roadblocks that came along for the ride.
What’s New: Our Recent Wins
Auto Scaling Group for EC2
A major focus has been setting up an Auto Scaling Group (ASG) for EC2 instances. Having ASG in place lets me spin up or shut down instances as needed without manual intervention. This means I can simulate any number of IoT devices just by adjusting the capacity of the group.IoT Device Simulation on Boot🤖
I’ve also configured these EC2 instances to run Python scripts for simulating IoT devices on boot. The idea is that, as soon as an instance spins up, it automatically starts sending data to the rest of the pipeline. Getting that “plug-and-play” behavior has been really satisfying to see in action.🌊Data Flow: EC2 → Kinesis → Lambda → S3 & DynamoDB
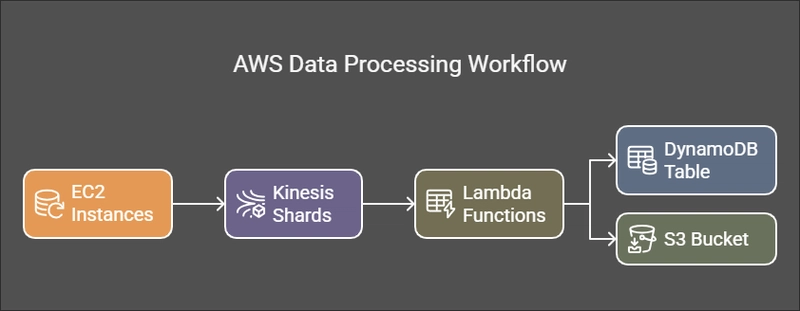
A functional data flow was an essential next step. With the pipeline in place:
EC2 runs the Python scripts that generate or collect telemetry.
The data streams into Amazon Kinesis in near real-time.
A Lambda function processes and transforms this data.
Finally, it lands in a DynamoDB Table for longer-term storage and analytics and a copy of the unprocessed data is sent to an S3 bucket for post-analysis. I haven't set up the DynamoDB table yet, so all data is sent to the S3 Bucket.
It’s a clean flow that captures the essence of a scalable IoT pipeline.
- 🔄️CI/CD Integration Another accomplishment has been setting up a CI/CD pipeline so that pushing new code automatically triggers updates across all instances. Specifically, whenever there’s a pull request to the main branch:
The pipeline reboots all IoT devices (the EC2 instances).
It runs updated code to ensure everything remains consistent and in sync.
Having this quick, reproducible deployment cycle makes it easy to iterate on features without worrying about manual redeployments.
- ✅Polished and Tested Python Code Finally, I spent a good chunk of time refactoring and cleaning up the Python code to ensure that each piece is thoroughly tested. This not only helped improve reliability but also made the codebase much easier to reason about and maintain over time.
🧑🏫Challenges and Lessons Learned
Of course, no progress comes without a few hiccups.
CI/CD Pipeline IAM Role Issues
One of the biggest hurdles was GitHub Actions not being able to assume the necessary IAM role for making requests to my API Gateway. I lost a fair bit of time troubleshooting, and it turned out the role trust policies and permissions weren’t aligned properly. Lesson learned: always verify which entity (GitHub Actions in this case) needs to assume which role, and ensure your trust relationships are explicitly set.Code Errors on EC2 Instances
Despite the automation, running code on the EC2 instances has been an ongoing game of whack-a-mole. Each time I solve one error, another pops up—from missing dependencies to library version conflicts. My takeaway here is to keep an eye on how the base AMI and Python environment get provisioned. Small changes can introduce big problems.Refactor Friction and Module Errors
After making the Python code more modular and test-friendly, I ran into a series of module-related errors. Some modules weren’t being imported correctly, or path issues surfaced only in the production environment. It was a reminder that thorough testing has to include realistic deployment scenarios as well—local tests aren’t always enough.
🤔Next Steps
Fix EC2 Python Script Issues:
The first priority is to stabilize the environment on each EC2 instance. I’ll refine the provisioning scripts, ensure dependencies are properly installed, and tackle the recurring module path errors once and for all.
Experiment with Different Instance Types:
Once the scripts run consistently, I plan to tinker with various EC2 instance types (e.g., t3.medium, m5.large) to strike a good balance between cost and performance. The goal is to simulate loads of varying magnitudes while keeping the budget in check.
Set Up a DynamoDB Table:
Storing stateful data—like metadata about the simulated IoT devices—could be hugely beneficial. I’ll spin up a DynamoDB table to maintain device configurations, health stats, or anything else that’ll help manage and analyze this distributed system more effectively.
Work on Analysis:
With the core pipeline (EC2 → Kinesis → Lambda → S3) in place, it’s time to shift focus to actual analytics. By integrating tools like Athena, QuickSight, or even custom ML pipelines, I can start transforming the raw stream data into actionable insights.
I’m excited for what’s next—especially now that I’ll have a more stable, scalable, and analytics-friendly backbone for Project Nairobi. Stay tuned for more updates as I tackle these to-dos and continue refining this platform into an end-to-end, production-grade solution!
Have any tips, suggestions, or want to share your own experiences wrestling with IAM roles and pipelines? Feel free to drop a comment. I’m always keen to hear how others navigate these complexities. And if you’re new here, be sure to check out my previous posts to see how Project Nairobi got started.
Stay tuned for more progress updates as I continue to refine this platform into a smoothly running, production-grade analytics engine!
😁Thanks for reading, and see you in the next update.

Top comments (0)