
Pre-trained CNNs are still king when training models for computer vision use cases. However, the emerging popularity of Visual Transformers (ViTs), and subsequent consensus about their unsupervised learning capabilities, gives unexpected space for ViTs to usurp the throne.
Pre-Trained CNNs
Convolutional Neural Networks work by sliding a pattern (formally known as the kernel, but also referred to as a "feature map") across an image (Slide 1). This sliding strategy is effective because it acts as a natural form of translation invariance: once a CNN can recognize something in one part of the image, it will recognize it in any part of the image [1]. However, this approach leads to a kind of fragility: feature maps are often overfit to a particular texture or object size.
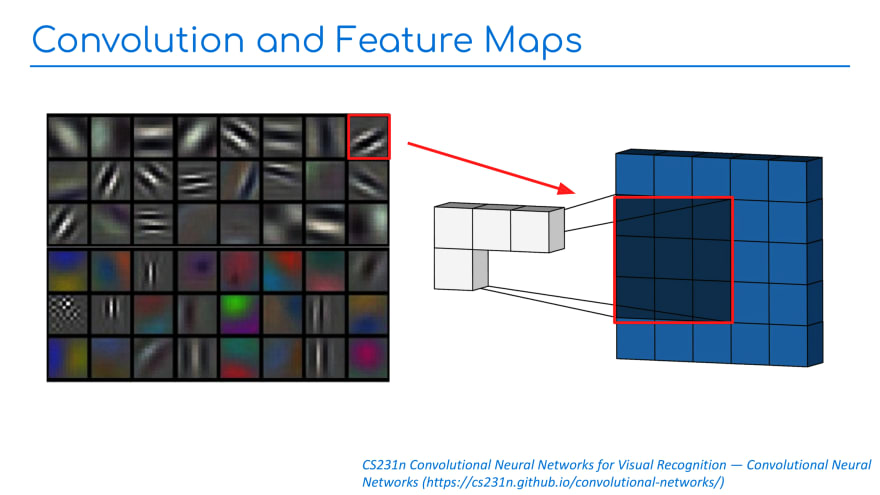
Building up feature maps requires a ton of data, and CNNs are usually pre-trained on a large generic dataset like COCO or ImageNet-the latter boasting over one million images and around 1,000 categories. Further, a pre-trained CNN can be fine-tuned to new tasks by cutting out the model head and retraining with a new, often much smaller, dataset (Slide 2).

Transformers
Transformers have been popular in natural language processing (NLP) for quite some time. They work through a concept known as "self-attention," which pays certain input parts more attention than others [3]. In NLP, this allows for specific words within a sentence to be identified as more important. There are different types of attention and plenty of nuance for the experts to argue over, but the words "attention" and "focus" are good mental models of how these networks learn.
Self-Supervised ViT
Self-supervised training is a little different in that it does not require labels-you don't need to tell the model that the object in an image belongs to the category "cat," for example. Instead, a self-supervised training technique might involve cropping an image, feeding it through multiple networks, and then getting them all to agree on which features in the image are essential (Slide 3). This type of learning technique, called DINO [3], successfully trained visual transformers (transformers for visual tasks, e.g., images). The ViTs trained with DINO ended up surprisingly effective for classification tasks, reaching 80% top-1 accuracy on ImageNet. Inspecting the self-attention maps of these ViTs also shows that they can very precisely segment out objects in an image (Slide 4).


Now, the bold prediction: self-supervised ViTs will eventually replace pre-trained CNNs as the go-to feature encoders for computer vision tasks. There are still unanswered questions, such as whether ViTs will generalize outside the training distribution better than CNNs. But one thing is sure: not requiring labels during training will enable using much larger datasets. Consider the difference in capacity between ImageNet and a self-supervised ViT trained on the entire internet of images…
Conclusion
Thanks for reading our latest paper exploration. If you love computer vision, check out zpy [4], our open-source synthetic data development toolkit. It's everything you need to generate and iterate on synthetic training data for computer vision. Your feedback, commits, and feature requests are invaluable as we continue to build a more robust set of tools for generating synthetic data. Meanwhile, if you could use support with a particularly tricky problem, please reach out.
References
[1] CS231n Convolutional Neural Networks for Visual Recognition - Convolutional Neural Networks (https://cs231n.github.io/convolutional-networks/)
[2] Transformer: A Novel Neural Network Architecture for Language Understanding (https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html)
[3] Emerging Properties in Self-Supervised Vision Transformers (https://arxiv.org/pdf/2104.14294.pdf ).
[4] zpy (github.com/ZumoLabs/zpy)

Top comments (0)