In Part 1 of our text classification series, we explored the DIY approach to emotion detection by fine-tuning DistilBERT. While that approach gives you maximum control, sometimes you need a solution that's both powerful and quick to implement. That's where Cohere's Classification API comes in.
In this tutorial, by using the Cohere Classify we'll build a production-ready sentiment analysis system in a fraction of the time it would take to train a custom model. By the end, you'll have a sentiment classifier that can instantly categorize text as positive, negative, or neutral—all without managing infrastructure or optimizing hyperparameters.
The Magic of API-Powered Sentiment Analysis
Before diving into code, let's understand why Cohere's Classification API is such a compelling option:
- No ML Expertise Required: You don't need to understand tokenization, embeddings, or model architectures
- Minimal Data Preparation: Just provide labeled examples in a simple format
- Production-Ready Performance: Access state-of-the-art language models without the training overhead
- Scalable Infrastructure: Handle thousands of classification requests without worrying about deployment
Let's start!
Step 1: Getting Started with Cohere
First, you'll need to sign up for a Cohere account and get your API key:
- Go to cohere.com and create an account
- Navigate to your dashboard and find your API key
- Install the Cohere Python client:
pip install cohere
echo COHERE_API_KEY = "<API_KEY>"
replace <API_KEY> with your actual key.
import cohere
import pandas as pd
import numpy as np
import os
from dotenv import load_dotenv
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm
load_dotenv()
co = cohere.Client(os.getenv("COHERE_API_KEY"))
Step 2: Preparing Your Sentiment Training Data
For this tutorial, we'll be using the same data as in Part 1, which consists of short text snippets, each labeled with one of the six emotions.
# Convert training data
data_pth = "data/train.txt"
df = pd.read_csv(data_pth, sep=";", header=None, names=['text', 'label'])
df.to_csv("data/transformed.csv", index=False)
# Create a dataset in Cohere
single_label_dataset = co.datasets.create(
name="single-label-dataset",
data=open("data/transformed.csv", "rb"),
type="single-label-classification-finetune-input"
)
print(co.wait(single_label_dataset).dataset.validation_status)
Once uploaded, Cohere validates our dataset for compatibility with its fine-tuning process. This helps catch any formatting issues before we invest time in model training.
Step 3: Fine-Tuning a Classification Model
After Cohere approves our dataset (indicated by the "validated" status), we can use it to fine-tune a model. While I've skipped showing the exact fine-tuning code (it was done previously), we can check on our fine-tuned models: finetuned_models = co.finetuning.list_finetuned_models()
From the output, we can see we have a model with ID 'c62448a1-530a-45bb-8ca4-9e4950f39ac0' that's ready for use. The model uses Cohere's English base classification model with a "task-few-shot" (STRATEGY_TFEW) approach, which is particularly efficient for specialized classification tasks.
Step 4: Testing Our Model with Sample Inputs
Let's see how our model performs on a couple of examples:
MODEL_ID = 'c62448a1-530a-45bb-8ca4-9e4950f39ac0'
response = co.classify(
inputs=[
"i didnt feel humiliated",
"i can go from feeling so hopeless to so damned hopeful just from being around someone who cares and is awake"
],
model = MODEL_ID + "-ft"
)
print(response)
Both examples are classified as expressing "sadness" with extraordinarily high confidence (over 99.9%). The response also includes confidence scores for all other emotion categories, showing how certain the model is about its prediction. What's fascinating here is the model's ability to detect emotional nuance that goes beyond simple keyword matching. The second example talks about feeling "hopeful," but the model correctly identifies the overall emotional tone as sadness.
Step 5: Evaluating Model Performance
To truly understand how well our model performs, we need to test it on our proper test dataset:
# Load test data
data_pth = "data/test.txt"
df = pd.read_csv(data_pth, sep=";", header=None, names=['text', 'label'])
# Evaluate in batches
batch_size = 90
all_results = []
num_batches = int(np.ceil(len(df) / batch_size))
for i in tqdm(range(num_batches)):
start_idx = i * batch_size
end_idx = min((i + 1) * batch_size, len(df))
batch_texts = df.text[start_idx:end_idx].tolist()
batch_labels = df.label[start_idx:end_idx].tolist()
response = co.classify(
inputs=batch_texts,
model = MODEL_ID + "-ft"
)
batch_results = [
{
'text': item.input,
'prediction': item.prediction,
'confidence': item.confidence,
'true_label': batch_labels[j]
}
for j, item in enumerate(response.classifications)
]
all_results.extend(batch_results)
df_output = pd.DataFrame(all_results)
# Calculate accuracy
accuracy = (df_output['prediction'] == df_output['true_label']).mean()
print(f"Overall accuracy: {accuracy:.4f}")
Our model achieves an impressive 93.20% accuracy on the test set! Let's look at some sample predictions:
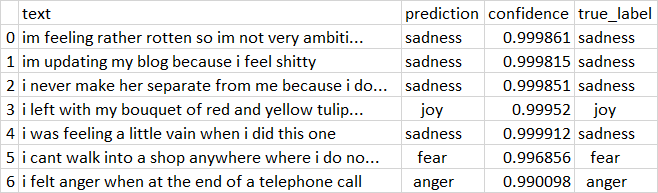
The model correctly identifies a wide range of emotional expressions with extremely high confidence. From explicit statements ("i feel shitty") to more nuanced expressions ("i left with my bouquet... feeling slightly more optimistic"), the classifier demonstrates remarkable accuracy.
Step 6: Exploring edge Cases
response = co.classify(
inputs=["I give you a first look at what data analysis with Positron will look like"],
model = MODEL_ID + "-ft"
)
Interestingly, this is classified as "joy" with 96.55% confidence, though it seems like a fairly neutral statement. This highlights an important point about emotion classification - sometimes what seems neutral to us may contain subtle markers of emotion that the model picks up. Alternatively, this could be a misclassification, reminding us that even high-performing models have their limitations.
Any which way this concludes this portion of the tutorial and here are ways you expand this even further:
- Fine-tune on domain-specific data for your particular use case
- Add intensity measurements (how strongly is the emotion expressed?)
- Implement multi-label classification to capture mixed emotions
- Create visualization dashboards to track emotional trends over time
Next, we'd see how to deploy this classifier model and use on a user interface anyone can use to classify a single sentence or upload a text file with a number of sentences!
Remember the ability to detect emotions in text at scale opens new possibilities for understanding human expression in the digital age. Whether you're analyzing customer feedback, social media conversation, or support interactions, emotional insights can guide your decision-making toward more empathetic and effective engagement strategies.
Ready to try it yourself? Head to Cohere's documentation also see this project's (repository)[https://github.com/AkanimohOD19A/classifier-cohere] to get started with your own text classification models.

Top comments (0)