
This is a story of how I unknowingly broke the production and recovered from it quickly. Every developer can vouch for the importance of testing, but sometimes even well-crafted unit, integration & acceptance tests are not enough to ensure the confidence to push new features to the production. A well-tested feature itself can break the integrity of production and today I’m going to share this experience with you all.
As part of a requirement at upmo.com, my task was to show a 3D virtual tour for an office space. The development and testing went smoothly and I was absolutely confident when I pushed my code for the deployment. As soon as the latest code was deployed to production, I got a notification on our incident slack channel that the synthetic monitoring had failed and my first reaction was.. What?! I thought I had tested everything, how did that bring production down?

The notification that I got from Slack was sent by AWS Synthetics, the tool that we used to implement synthetic monitoring. AWS Synthetics service allows us to run automated scripts using Node.js. Our script is written in such a way that it simulates a complete user journey on our web application. When this script runs, it will provide us with feedback in the form of screenshots, performance trend of scripts or network calls, and logs. Simulating this user journey, and capturing screenshots are easy to be done in AWS Synthetics as puppeteer is automatically included.
Since our monitoring is running continuously, one of the common questions that technologists ask is how would we differentiate if a transaction is coming from our synthetic monitoring or real users? The answer to that is, our synthetic monitoring journey will only complete a journey on our synthetic data. In upmo.com, we have created a synthetic building page (father christmas workshop) for this purpose.
After acknowledging the incident, I started my investigation on why the monitoring had failed and checked the screenshots and logs in AWS Synthetics. From the logs of journey performed by synthetic monitoring, I found out that the page which was supposed to include the latest feature was indeed broken. I really want to quickly fix the incident as I want to make sure that real users are not impacted by this. After having a deeper look, I realized that the failure happened because the code I’ve pushed caused a backward compatibility issue on production. I would have thought that this is something that should have been caught by our CI/CD pipeline, but apparently, it’s been failing silently. I can actually see the same errors in our CI logs. If the build would have failed, this feature would not have broken the page itself on production.
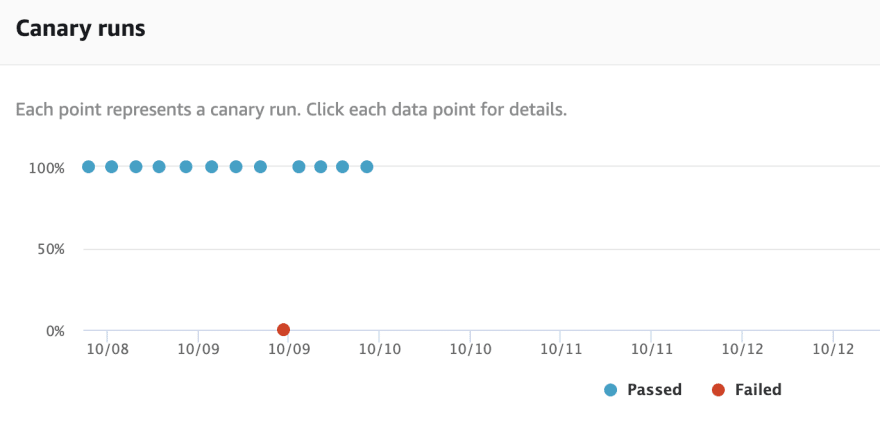
This incident made me realize that sometimes we as developers tend to become more complacent about code and overlook surrounding things. I have found synthetic monitoring as a pattern to be really useful, as it has helped me in making the system more resilient. It helped me discover issues before actual user reports, thus saving the time, energy, and cost. I would really like to encourage everyone to use this pattern on their projects and deploy with confidence to production using synthetic monitoring.
If you’re interested in an easy & transparent way to find & rent office or co-working space across London, check out our startup at upmo.com.
And if you're interested in how we build Upmo, we publish our dev docs transparently at upmo.com/dev.

Top comments (1)
Nice article Aman. It happens with us and every time we learn something from it.