
When we are developing software, we have to store data in memory. However, there are many types of data structures, such as arrays, maps, sets, lists, trees, graphs, etc. and choosing the right one for the task can be tricky. So, this series of posts will help you to know the trade-offs, so, you can use the right tool for the job!
On this section, we are going to focus on linear data structures: Arrays, Lists, Sets, Stacks, and Queues.
You can find all these implementations and more in the Github repo:
 amejiarosario
/
dsa.js-data-structures-algorithms-javascript
amejiarosario
/
dsa.js-data-structures-algorithms-javascript
🥞Data Structures and Algorithms explained and implemented in JavaScript + eBook

Data Structures and Algorithms in JavaScript

This is the coding implementations of the DSA.js book and the repo for the NPM package.
In this repository, you can find the implementation of algorithms and data structures in JavaScript. This material can be used as a reference manual for developers, or you can refresh specific topics before an interview. Also, you can find ideas to solve problems more efficiently.
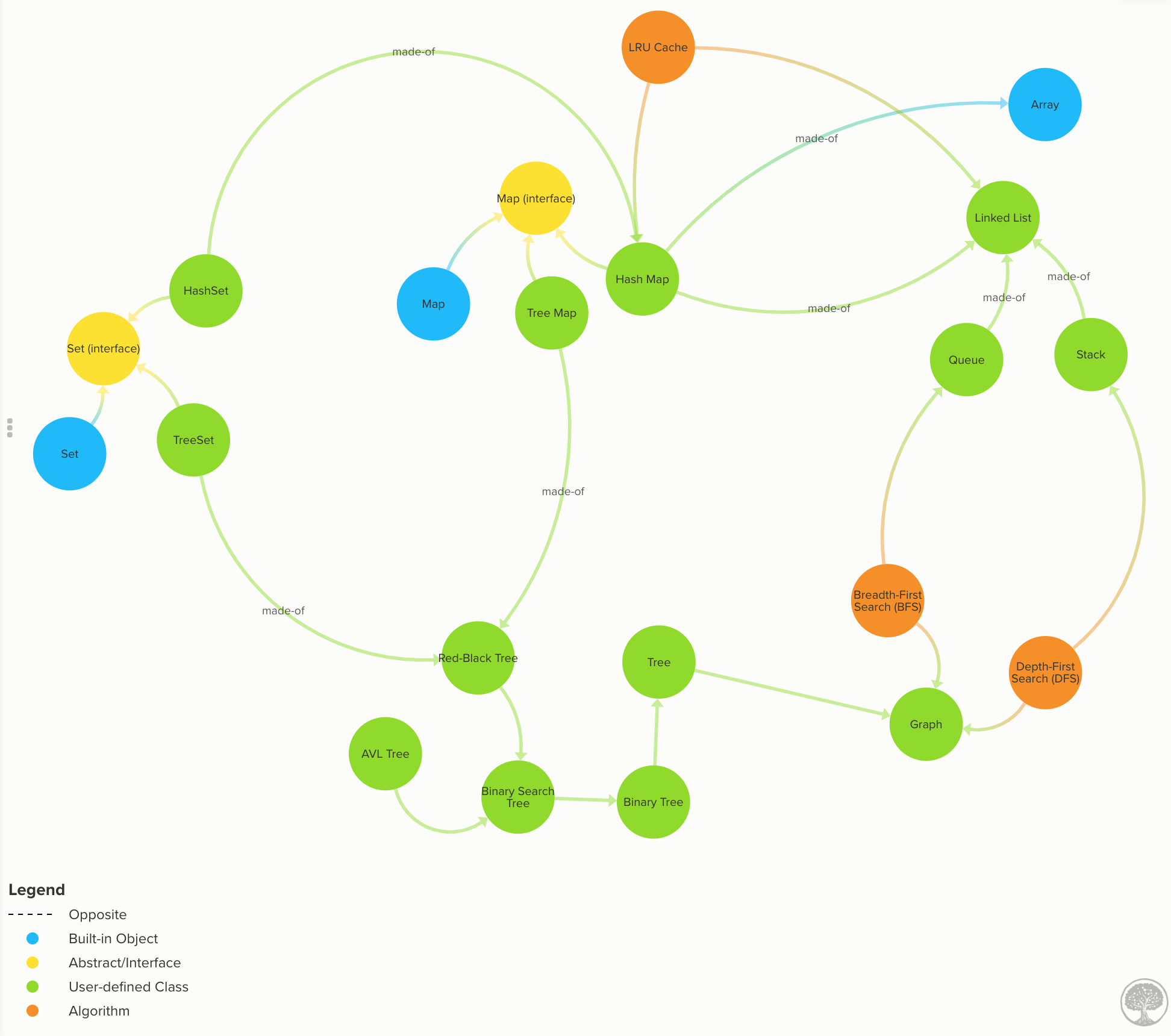
Table of Contents
Installation
You can clone the repo or install the code from NPM:
npm install dsa.js
and then you can import it into your programs or CLI
const { LinkedList, Queue, Stack } = require('dsa.js');
For a list of all available data structures and algorithms, see index.js.
Features
Algorithms are an essential…
Data Structures Big-O Cheatsheet
The following table is a summary of everything that we are going to cover here.
Bookmark it, pin it or share it, so you have it at hand when you need it.
Click on the **name* to go the section or click on the runtime to go the implementation*
* = Amortized runtime
| Name | Insert | Access | Search | Delete | Comments |
|---|---|---|---|---|---|
| Array | O(n) | O(1) | O(n) | O(n) | Insertion to the end is O(1). Details here.
|
| HashMap | O(1) | O(1) | O(1) | O(1) | Rehashing might affect insertion time. Details here. |
| Map (using Binary Search Tree) | O(log(n)) | - | O(log(n)) | O(log(n)) | Implemented using Binary Search Tree |
| Set (using HashMap) | O(1) | - | O(1) | O(1) | Set using a HashMap implementation. Details here. |
| Set (using list) | O(n) | - | O(n) | O(n) | Implemented using Binary Search Tree |
| Set (using Binary Search Tree) | O(log(n)) | - | O(log(n)) | O(log(n)) | Implemented using Binary Search Tree |
| Linked List (singly) | O(n) | - | O(n) | O(n) | Adding/Removing to the start of the list is O(1). Details here. |
| Linked List (doubly) | O(n) | - | O(n) | O(n) | Adding/Deleting from the beginning/end is O(1). But, deleting/adding from the middle is O(n). Details here
|
| Stack (array implementation) | O(1) | - | - | O(1) | Insert/delete is last-in, first-out (LIFO) |
| Queue (naive array impl.) | O(n) | - | - | O(1) | Insert (Array.shift) is O(n) |
| Queue (array implementation) | O(1) | - | - | O(1) | Worst time insert is O(n). However amortized is O(1) |
| Queue (list implementation) | O(1) | - | - | O(1) | Using Doubly Linked List with reference to the last element. |
Note: Binary search trees and trees, in general, will be cover in the next post. Also, graph data structures.
Primitive Data Types
Primitive data types are the most basic elements where all the other data structures are built upon. Some primitives are:
- Integers. E.g.,
1,2,3, ... - Characters. E.g.,
a,b,"1","*" - Booleans. E.g.,
trueorfalse. - Float (floating points) or doubles. E.g.,
3.14159,1483e-2. - Null values. E.g.
null
JavaScript specific primitives:
- undefined
- Symbol
- Number
Note: Objects are not primitive since it's a collection of zero or more primitives and other objects.
Array
Arrays are collections of zero or more elements. Arrays are one of the most used data structure because of its simplicity and fast way of retrieving information.
You can think of an array as a drawer where you can store things on the bins.
Array is like a drawer that stores things on bins

When you want to search for something you can go directly to the bin number. That's a constant time operation (O(1)). However, if you forgot what cabinet had, then you will have to open one by one (O(n)) to verify its content until you find what you are looking for. That same happens with an array.
Depending on the programming language, arrays have some differences. For some dynamic languages like JavaScript and Ruby, an array can contain different data types: numbers, strings, words, objects, and even functions. In typed languages like Java/C/C++, you have to predefine the size of the array and the data type. In JavaScript, it would automatically increase the size of the array when needed.
Arrays built-in operations
Depending on the programming language, the implementation would be slightly different.
For instance, in JavaScript, we can accomplish append to end with push and append to the beginning with unshift. But also, we have pop and shift to remove from an array. Let's describe the runtime of some common operations that we are going to use through this post.
Common JS Array built-in functions
| Function | Runtime | Description |
|---|---|---|
| array.push | O(1) | Insert element to the end of the array |
| array.pop | O(1) | Remove element to the end of the array |
| array.shift | O(n) | Remove element to the beginning of the array |
| array.unshift | O(n) | Insert element(s) to the beginning of the array |
| array.slice | O(n) | Returns a copy of the array from beginning to end. |
| array.splice | O(n) | Changes (add/remove) the array |
Insert element on an array
There are multiple ways to insert elements into an array. You can append new data to end, or you can add it to the beginning of the collection.
Let's start with append to tail:
function insertToTail(array, element) {
array.push(element);
return array;
}
const array = [1, 2, 3];
console.log(insertToTail(array, 4)); // => [ 1, 2, 3, 4 ]
Based on the language specification, push just set the new value at the end of the array. Thus,
The
Array.pushruntime is a O(1)
Let's now try appending to head:
function insertToHead(array, element) {
array.unshift(element);
return array;
}
const array = [1, 2, 3];
console.log(insertToHead(array, 0)); // => [ 0, 1, 2, 3 ]
What do you think is the runtime of the insertToHead function? Looks the same as the previous one except that we are using unshift instead of push. But, there's a catch! unshift algorithm makes room for the new element by moving all existing ones to the next position in the array. So, it will iterate through all the items and move them.
The
Array.unshiftruntime is an O(n)
Access an element in an array
If you know the index for the element that you are looking for, then you can access the element directly like this:
function access(array, index) {
return array[index];
}
const array = [1, 'word', 3.14, {a: 1}];
access(array, 0); // => 1
access(array, 3); // => {a: 1}
As you can see in the code above, accessing an element on an array has a constant time:
Array access runtime is O(1)
Note: You can also change any value at a given index in constant time.
Search an element in an array
If you don't know the index of the data that you want from an array, then you have to iterate through each element on the collection until we find what we are looking for.
function search(array, element) {
for (let index = 0; index < array.length; index++) {
if(element === array[index]) {
return index;
}
}
}
const array = [1, 'word', 3.14, {a: 1}];
console.log(search(array, 'word')); // => 1
console.log(search(array, 3.14)); // => 2
Given the for-loop, we have:
Array search runtime is O(n)
Deleting elements from an array
What do you think is the running time of deleting an element from an array?
Well, let's think about the different cases:
- You can delete from the end of the array which might be constant time. O(1)
- However, you can also remove from the beginning or middle of the collection. In that case, you would have to move all the following elements to close the gap. O(n)
Talk is cheap, let's do the code!
function remove(array, element) {
const index = search(array, element);
array.splice(index, 1);
return array;
}
const array1 = [0, 1, 2, 3];
console.log(remove(array1, 1)); // => [ 0, 2, 3 ]
So we are using our search function to find the elements' index O(n). Then we use the JS built-in splice function which has a running time of O(n). So, we are going to iterate through the list twice, but instead of saying O(2n), for big o notation it's still O(n). Remember from our first post that constants don't matter as much.
We take the worst case scenario:
Deleting an item from an array is O(n).
Array operations time complexity
We can sum up the arrays time complexity as follows:
Array Time Complexities
| Operation | Worst |
|---|---|
Access (Array.[]) |
O(1) |
Insert head (Array.unshift) |
O(n) |
Insert tail (Array.push) |
O(1) |
| Search (for value) | O(n) |
Delete (Array.splice) |
O(n) |
HashMaps
HashMaps has many names like HashTable, HashMap, Map, Dictionary, Associative Arrays and so on. The concept is the same while the implementation might change slightly.
Hashtable is a data structure that maps keys to values
Going back to the drawer analogy, bins have a label rather than a number.
HashMap is like a drawer that stores things on bins and labels them

In this example, if you are looking for the DSA.js book, you don't have to open the bin 1, 2, and 3 to see what's inside. You go directly to the container labeled as "books". That's a huge gain! Search time goes from O(n) to O(1).
In arrays, the data is referenced using a numeric index (relatively to the position). However, HashMaps uses labels that could be a string, number, object or anything. Internally, the HashMap uses an Array, and it maps the labels to array indexes using a hash function.
There are at least two ways to implement a Map:
-
Array: Using a hash function to map a key to the array index value. A.k.a
HashMap. Worst:O(n), Average:O(1) -
Binary Search Tree: using a self-balancing binary search tree to look up for values (more on this later). A.k.a
TreeMap. Worst:O(log n), Average:O(log n).
We are going to cover Trees & Binary Search Trees, so don't worry about it for now. The most common implementation of Maps is using an array and hash function. So, that's the one we are going to focus on.
HashMap implemented with an array
 indexes")
As you can see in the image, each key gets translated into a hash code. Since the array size is limited (e.g., 10), we have to loop through the available buckets using modulus function. In the buckets, we store the key/value pair, and if there's more than one, we use a collection to hold them.
Now, What do you think about covering each of the HashMap components in details? Let's start with the hash function.
HashMap vs. Array
Why go through the trouble of converting the key into an index and not using an array directly you might ask. Well, the main difference is that the Array's index doesn't have any relationship with the data. You have to know where your data is.
Let's say you want to count how many times words are used in a text. How would you implement that?
- You can use two arrays (let's call it
AandB). One for storing the word and another for storing how many times they have seen (frequency). - You can use a HashMap. They
keyis the word, and thevalueis the frequency of the word.
What is the runtime of approach #1 using two arrays? If we say, the number of words in the text is n. Then we have to search if the word in the array A and then increment the value on array B matching that index. For every word on n we have to test if it's already on array A. This double loop leave use with a runtime of O(n2).
What is the runtime of approach #2 using a HashMap? Well, we iterate through each word on the text once and increment the value if there is something there or set it to 1 if that word is seen for the first time. The runtime would be O(n) which is much more performant than approach #1.
Differences between HashMap and Array
- Search on an array is O(n) while on a HashMap is O(1)
- Arrays can have duplicate values, while HashMap cannot have duplicated keys (but they can have duplicate values.)
- The array has a key (index) that is always a number from 0 to max value, while in a HashMap you have control of the key and it can be whatever you want: number, string, or symbol.
Hash Function
The first step to implement a HashMap is to have a hash function. This function will map every key to its value.
The perfect hash function is the one that for every key it assigns a unique index.
Ideal hashing algorithms allow constant time access/lookup. However, it's hard to achieve a perfect hashing function in practice. You might have the case where two different keys yields on the same index. This is called collision.
Collisions in HashMaps are unavoidable when using an array-like underlying data structure. At some point, data can't fit in a HashMap will reuse data slots. One way to deal with collisions is to store multiple values in the same bucket using a linked list or another array (more on this later). When we try to access the key's value and found various values, we iterate over the values O(n). However, in most implementations, the hash adjusts the size dynamically to avoid too many collisions. So, we can say that the amortized lookup time is O(1). We are going to explain what we mean by amortized runtime later on this post with an example.
Naïve HashMap implementation
A simple (and bad) hash function would be this one:
class NaiveHashMap {
constructor(initialCapacity = 2) {
this.buckets = new Array(initialCapacity);
}
set(key, value) {
const index = this.getIndex(key);
this.buckets[index] = value;
}
get(key) {
const index = this.getIndex(key);
return this.buckets[index];
}
hash(key) {
return key.toString().length;
}
getIndex(key) {
const indexHash = this.hash(key);
const index = indexHash % this.buckets.length;
return index;
}
}
We are using buckets rather than drawer/bins, but you get the idea :)
We have an initial capacity of 2 (buckets). But, we want to store any number of elements on them. We use modulus % to loop through the number of available buckets.
Take a look at our hash function. We are going to talk about it in a bit. First, let's use our new HashMap!
// Usage:
const assert = require('assert');
const hashMap = new NaiveHashMap();
hashMap.set('cat', 2);
hashMap.set('rat', 7);
hashMap.set('dog', 1);
hashMap.set('art', 8);
console.log(hashMap.buckets);
/*
bucket #0: <1 empty item>,
bucket #1: 8
*/
assert.equal(hashMap.get('art'), 8); // this one is ok
assert.equal(hashMap.get('cat'), 8); // got overwritten by art 😱
assert.equal(hashMap.get('rat'), 8); // got overwritten by art 😱
assert.equal(hashMap.get('dog'), 8); // got overwritten by art 😱
This Map allows us to set a key and a value and then get the value using a key. The key part is the hash function. Let's see multiple implementations to see how it affects the performance of the Map.
Can you tell what's wrong with NaiveHashMap before looking to the answer below?
What is wrong with NaiveHashMap is that...
1) Hash function generates many duplicates. E.g.
hash('cat') // 3
hash('dog') // 3
This will cause a lot of collisions.
2) Collisions are not handled at all. Both cat and dog will overwrite each other on the position 3 of the array (bucket#1).
3) Size of the array even if we get a better hash function we will get duplicates because the array has a size of 3 which less than the number of elements that we want to fit. We want to have an initial capacity that is well beyond what we need to fit.
Improving Hash Function
The primary purpose of a HashMap is to reduce the search/access time of an Array from
O(n)toO(1).
For that we need:
- A proper hash function that produces as few collisions as possible.
- An array big enough to hold all the required values.
Let's give it another shot to our hash function. Instead of using the length of the string, let's sum each character ascii code.
hash(key) {
let hashValue = 0;
const stringKey = key.toString();
for (let index = 0; index < stringKey.length; index++) {
const charCode = stringKey.charCodeAt(index);
hashValue += charCode;
}
return hashValue;
}
Let's try again:
hash('cat') // 312 (c=99 + a=97 + t=116)
hash('dog') // 314 (d=100 + o=111 + g=103)
This one is better! Because words with the same length has different code.
Howeeeeeeeeever, there's still an issue! Because rat and art are both 327, collision! 💥
We can fix that by offsetting the sum with the position:
hash(key) {
let hashValue = 0;
const stringKey = `${key}`;
for (let index = 0; index < stringKey.length; index++) {
const charCode = stringKey.charCodeAt(index);
hashValue += charCode << (index * 8);
}
return hashValue;
}
Now let's try again, this time with hex numbers so we can see the offset.
// r = 114 or 0x72; a = 97 or 0x61; t = 116 or 0x74
hash('rat'); // 7,627,122 (r: 114 * 1 + a: 97 * 256 + t: 116 * 65,536) or in hex: 0x726174 (r: 0x72 + a: 0x6100 + t: 0x740000)
hash('art'); // 7,631,457 or 0x617274
What about different types?
hash(1); // 49
hash('1'); // 49
hash('1,2,3'); // 741485668
hash([1,2,3]); // 741485668
hash('undefined') // 3402815551
hash(undefined) // 3402815551
Houston, we still have a problem!! Different values types shouldn't return the same hash code!
How can we solve that?
One way is taking into account the key type into the hash function.
hash(key) {
let hashValue = 0;
const stringTypeKey = `${key}${typeof key}`;
for (let index = 0; index < stringTypeKey.length; index++) {
const charCode = stringTypeKey.charCodeAt(index);
hashValue += charCode << (index * 8);
}
return hashValue;
}
Let's test that again:
console.log(hash(1)); // 1843909523
console.log(hash('1')); // 1927012762
console.log(hash('1,2,3')); // 2668498381
console.log(hash([1,2,3])); // 2533949129
console.log(hash('undefined')); // 5329828264
console.log(hash(undefined)); // 6940203017
Yay!!! 🎉 we have a much better hash function!
We also can change the initial capacity of the array to minimize collisions. Let's put all of that together in the next section.
Decent HashMap Implementation
Using our optimized hash function we can now do much better.
We could still have collisions so let's implement something to handle them
Let's make the following improvements to our HashMap implementation:
- Hash function that checks types and character orders to minimize collisions.
- Handle collisions by appending values to a list. We also added a counter to keep track of them.
class DecentHashMap {
constructor(initialCapacity = 2) {
this.buckets = new Array(initialCapacity);
this.collisions = 0;
}
set(key, value) {
const bucketIndex = this.getIndex(key);
if(this.buckets[bucketIndex]) {
this.buckets[bucketIndex].push({key, value});
if(this.buckets[bucketIndex].length > 1) { this.collisions++; }
} else {
this.buckets[bucketIndex] = [{key, value}];
}
return this;
}
get(key) {
const bucketIndex = this.getIndex(key);
for (let arrayIndex = 0; arrayIndex < this.buckets[bucketIndex].length; arrayIndex++) {
const entry = this.buckets[bucketIndex][arrayIndex];
if(entry.key === key) {
return entry.value
}
}
}
hash(key) {
let hashValue = 0;
const stringTypeKey = `${key}${typeof key}`;
for (let index = 0; index < stringTypeKey.length; index++) {
const charCode = stringTypeKey.charCodeAt(index);
hashValue += charCode << (index * 8);
}
return hashValue;
}
getIndex(key) {
const indexHash = this.hash(key);
const index = indexHash % this.buckets.length;
return index;
}
}
Let's use it and see how it perform:
// Usage:
const assert = require('assert');
const hashMap = new DecentHashMap();
hashMap.set('cat', 2);
hashMap.set('rat', 7);
hashMap.set('dog', 1);
hashMap.set('art', 8);
console.log('collisions: ', hashMap.collisions); // 2
console.log(hashMap.buckets);
/*
bucket #0: [ { key: 'cat', value: 2 }, { key: 'art', value: 8 } ]
bucket #1: [ { key: 'rat', value: 7 }, { key: 'dog', value: 1 } ]
*/
assert.equal(hashMap.get('art'), 8); // this one is ok
assert.equal(hashMap.get('cat'), 2); // Good. Didn't got overwritten by art
assert.equal(hashMap.get('rat'), 7); // Good. Didn't got overwritten by art
assert.equal(hashMap.get('dog'), 1); // Good. Didn't got overwritten by art
This DecentHashMap gets the job done, but, there are still some issues. We are using a decent hash function that doesn't produce duplicate values, and that's great. However, we have two values in bucket#0 and two more in bucket#1. How is that possible?
Since we are using a limited bucket size of 2, we use modulus % to loop through the number of available buckets. So, even if the hash code is different, all values will fit on the size of the array: bucket#0 or bucket#1.
hash('cat') => 3789411390; bucketIndex => 3789411390 % 2 = 0
hash('art') => 3789415740; bucketIndex => 3789415740 % 2 = 0
hash('dog') => 3788563007; bucketIndex => 3788563007 % 2 = 1
hash('rat') => 3789411405; bucketIndex => 3789411405 % 2 = 1
So naturally we have increased the initial capacity but by how much? Let's see how the initial size affects the hash map performance.
If we have an initial capacity of 1. All the values will go into one bucket (bucket#0), and it won't be any better than searching a value in a simple array O(n).
Let's say that we start with an initial capacity set to 10:
const hashMapSize10 = new DecentHashMap(10);
hashMapSize10.set('cat', 2);
hashMapSize10.set('rat', 7);
hashMapSize10.set('dog', 1);
hashMapSize10.set('art', 8);
console.log('collisions: ', hashMapSize10.collisions); // 1
console.log('hashMapSize10\n', hashMapSize10.buckets);
/*
bucket#0: [ { key: 'cat', value: 2 }, { key: 'art', value: 8 } ],
<4 empty items>,
bucket#5: [ { key: 'rat', value: 7 } ],
<1 empty item>,
bucket#7: [ { key: 'dog', value: 1 } ],
<2 empty items>
*/
Another way to see this
As you can see, we reduced the number of collisions (from 2 to 1) by increasing the initial capacity of the hash map.
Let's try with a bigger capacity 💯:
const hashMapSize100 = new DecentHashMap(100);
hashMapSize100.set('cat', 2);
hashMapSize100.set('rat', 7);
hashMapSize100.set('dog', 1);
hashMapSize100.set('art', 8);
console.log('collisions: ', hashMapSize100.collisions); // 0
console.log('hashMapSize100\n', hashMapSize100.buckets);
/*
<5 empty items>,
bucket#5: [ { key: 'rat', value: 7 } ],
<1 empty item>,
bucket#7: [ { key: 'dog', value: 1 } ],
<32 empty items>,
bucket#41: [ { key: 'art', value: 8 } ],
<49 empty items>,
bucket#90: [ { key: 'cat', value: 2 } ],
<9 empty items>
*/
Yay! 🎊 no collision!
Having a bigger bucket size is excellent to avoid collisions, but it consumes too much memory, and probably most of the buckets will be unused.
Wouldn't it be great, if we can have a HashMap that automatically increases its size as needed? Well, that's called rehash, and we are going to do it next!
Optimal HashMap Implementation
If we have a big enough bucket we won't have collisions thus the search time would be O(1). However, how do we know how big a hash map capacity should big? 100? 1,000? A million?
Having allocated massive amounts of memory is impractical. So, what we can do is to have the hash map automatically resize itself based on a load factor. This operation is called Rehash.
The load factor is the measurement of how full is a hash map. We can get the load factor by dividing the number of items by the bucket size.
This will be our latest and greatest hash map implementation:
Optimized Hash Map Implementation
github.com/amejiarosario/dsa.js/blob/master/src/data-structures/maps/hash-maps/hash-map.js
Pay special attention to the rehash method. That's where the magic happens. We create a new HashMap with doubled capacity.
So, testing our new implementation from above ^
const assert = require('assert');
const hashMap = new HashMap();
assert.equal(hashMap.getLoadFactor(), 0);
hashMap.set('songs', 2);
hashMap.set('pets', 7);
hashMap.set('tests', 1);
hashMap.set('art', 8);
assert.equal(hashMap.getLoadFactor(), 4/16);
hashMap.set('Pineapple', 'Pen Pineapple Apple Pen');
hashMap.set('Despacito', 'Luis Fonsi');
hashMap.set('Bailando', 'Enrique Iglesias');
hashMap.set('Dura', 'Daddy Yankee');
hashMap.set('Lean On', 'Major Lazer');
hashMap.set('Hello', 'Adele');
hashMap.set('All About That Bass', 'Meghan Trainor');
hashMap.set('This Is What You Came For', 'Calvin Harris ');
assert.equal(hashMap.collisions, 2);
assert.equal(hashMap.getLoadFactor(), 0.75);
assert.equal(hashMap.buckets.length, 16);
hashMap.set('Wake Me Up', 'Avicii'); // <--- Trigger REHASH
assert.equal(hashMap.collisions, 0);
assert.equal(hashMap.getLoadFactor(), 0.40625);
assert.equal(hashMap.buckets.length, 32);
Take notice that after we add the 12th item, the load factor gets beyond 0.75, so a rehash is triggered and doubles the capacity (from 16 to 32). Also, you can see how the number of collisions improves from 2 to 0!
This implementation is good enough to help us to figure out the runtime of common operations like insert/search/delete/edit.
To sum up, the performance of a HashMap will be given by:
- The hash function that every key produces for different output.
- Size of the bucket to hold data.
We nailed both 🔨. We have a decent hash function that produces different output for different data. Two distinct data will never return the same code. Also, we have a rehash function that automatically grows the capacity as needed. That's great!
Insert element on a HashMap runtime
Inserting an element on a HashMap requires two things: a key and a value. We could use our DecentHashMap data structure that we develop or use the built-in as follows:
function insert(object, key, value) {
object[key] = value;
return object;
}
const object = {};
console.log(insert(hash, 'word', 1)); // => { word: 1 }
In modern JavaScript, you can use Maps.
function insertMap(map, key, value) {
map.set(key, value);
return map;
}
const map = new Map();
console.log(insertMap(map, 'word', 1)); // Map { 'word' => 1 }
Note: We are going to use the Map rather than regular Object, since the Map's key could be anything while on Object's key can only be string or number. Also, Maps keeps the order of insertion.
Behind the scenes, the Map.set just insert elements into an array (take a look at DecentHashMap.set). So, similar to Array.push we have that:
Insert an element in HashMap runtime is O(1). If rehash is needed, then it will take O(n)
Our implementation with rehash functionality will keep collisions to the minimum. The rehash operation takes O(n) but it doesn't happen all the time only when is needed.
Search/Access an element on a HashMap runtime
This is the HashMap.get function that we use to get the value associated with a key. Let's evaluate the implementation from DecentHashMap.get):
get(key) {
const hashIndex = this.getIndex(key);
const values = this.array[hashIndex];
for (let index = 0; index < values.length; index++) {
const entry = values[index];
if(entry.key === key) {
return entry.value
}
}
}
If there's no collision, then values will only have one value and the access time would be O(1). But, we know there will be collisions. If the initial capacity is too small and the hash function is terrible like NaiveHashMap.hash then most of the elements will end up in a few buckets O(n).
HashMap access operation has a runtime of
O(1)on average and worst-case ofO(n).
Advanced Note: Another idea to reduce the time to get elements from O(n) to O(log n) is to use a binary search tree instead of an array. Actually, Java's HashMap implementation switches from an array to a tree when a bucket has more than 8 elements.
Edit/Delete element on a HashMap runtime
Editing (HashMap.set) and deleting (HashMap.delete) key/value pairs have an amortized runtime of O(1). In the case of many collisions, we could face an O(n) as a worst case. However, with our rehash operation, we can mitigate that risk.
HashMap edits and delete operations has a runtime of
O(1)on average and worst-case ofO(n).
HashMap operations time complexity
We can sum up the arrays time complexity as follows:
HashMap Time Complexities
| Operation | Worst | Amortized | Comments |
|---|---|---|---|
Access/Search (HashMap.get) |
O(n) |
O(1) |
O(n) is an extreme case when there are too many collisions |
Insert/Edit (HashMap.set) |
O(n) |
O(1) |
O(n) only happens with rehash when the Hash is 0.75 full |
Delete (HashMap.delete) |
O(n) |
O(1) |
O(n) is an extreme case when there are too many collisions |
Sets
Sets are very similar to arrays. The difference is that they don't allow duplicates.
How can we implement a Set (array without duplicates)? Well, we could use an array and check if an element is there before inserting a new one. But the running time of checking if an item is already there is O(n). Can we do better than that? We develop the Map that has an amortized run time of O(1)!
Set Implementation
We could use the JavaScript built-in Set. However, if we implement it by ourselves, it's more logic to deduct the runtimes. We are going to use the optimized HashMap with rehash functionality.
const HashMap = require('../hash-maps/hash-map');
class MySet {
constructor() {
this.hashMap = new HashMap();
}
add(value) {
this.hashMap.set(value);
}
has(value) {
return this.hashMap.has(value);
}
get size() {
return this.hashMap.size;
}
delete(value) {
return this.hashMap.delete(value);
}
entries() {
return this.hashMap.keys.reduce((acc, key) => {
if(key !== undefined) {
acc.push(key.content);
}
return acc
}, []);
}
}
We used HashMap.set to add the set elements without duplicates. We use the key as the value, and since hash maps keys are unique we are all set.
Checking if an element is already there can be done using the hashMap.has which has an amortized runtime of O(1). The most operations would be an amortized constant time except for getting the entries which is O(n).
Note: The JS built-in Set.has has a runtime of O(n), since it uses a regular list of elements and checks each one at a time. You can see the Set.has algorithm here
Here some examples how to use it:
const assert = require('assert');
// const set = new Set(); // Using the built-in
const set = new MySet(); // Using our own implementation
set.add('one');
set.add('uno');
set.add('one'); // should NOT add this one twice
assert.equal(set.has('one'), true);
assert.equal(set.has('dos'), false);
assert.equal(set.size, 2);
// assert.deepEqual(Array.from(set), ['one', 'uno']);
assert.equal(set.delete('one'), true);
assert.equal(set.delete('one'), false);
assert.equal(set.has('one'), false);
assert.equal(set.size, 1);
You should be able to use MySet and the built-in Set interchangeably for these examples.
Set Operations runtime
From our Set implementation using a HashMap we can sum up the time complexity as follows (very similar to the HashMap):
Set Time Complexities
| Operation | Worst | Amortized | Comments |
|---|---|---|---|
Access/Search (Set.has) |
O(n) |
O(1) |
O(n) is an extreme case when there are too many collisions |
Insert/Edit (Set.add) |
O(n) |
O(1) |
O(n) only happens with rehash when the Hash is 0.75 full |
Delete (Set.delete) |
O(n) |
O(1) |
O(n) is an extreme case when there are too many collisions |
Linked Lists
Linked List is a data structure where every element is connected to the next one.

The linked list is the first data structure that we are going to implement without using an array. Instead, we are going to use a node which holds a value and points to the next element.
class Node {
constructor(value) {
this.value = value;
this.next = null;
}
}
When we have a chain of nodes where each one points to the next one, then we a Singly Linked list.
Singly Linked Lists
For a singly linked list, we only have to worry about every element having a reference to the next one.
We start by constructing the root or head element.
class LinkedList {
constructor() {
this.root = null;
}
// ...
}
There are four basic operations that we can do in every Linked List:
-
addLast: appends an element to the end of the list (tail) -
removeLast: deletes element to the end of the list -
addFirst: Adds an element to the beginning of the list (head) -
removeFirst: Removes an element from the start of the list (head/root)
Adding/Removing an element at the end of a linked list
There are two primary cases:
- If the list first (root/head) doesn't have any element yet, we make this node the head of the list.
- Contrary, if the list already has items, then we have to iterate until finding the last one and appending our new node to the end.
addLast(value) { // similar Array.push
const node = new Node(value);
if(this.root) {
let currentNode = this.root;
while(currentNode && currentNode.next) {
currentNode = currentNode.next;
}
currentNode.next = node;
} else {
this.root = node;
}
}
What's the runtime of this code? If it is the first element, then adding to the root is O(1). However, finding the last item is O(n).
Now, removing an element from the end of the list has similar code. We have to find the current before last and make its next reference null.
removeLast() {
let current = this.root;
let target;
if(current && current.next) {
while(current && current.next && current.next.next) {
current = current.next;
}
target = current.next;
current.next = null;
} else {
this.root = null;
target = current;
}
if(target) {
return target.value;
}
}
The runtime again is O(n) because we have to iterate until the second-last element and remove the reference to the last (line 10).
Adding/Removing an element from the beginning of a linked list
Adding an element to the head of the list is like this:
addFirst(value) {
const node = new Node(value);
node.next = this.first;
this.first = node;
}
Adding and removing elements from the beginning is a constant time because we hold a reference to the first element:
addFirst(value) {
const node = new Node(value);
node.next = this.first;
this.first = node;
}
As expected, the runtime for removing/adding to the first element from a linked List is always constant O(1)
Removing an element anywhere from a linked list
Removing an element anywhere in the list leverage the removeLast and removeFirst. However, if the removal is in the middle, then we assign the previous node to the next one. That removes any reference from the current node; this is removed from the list:
remove(index = 0) {
if(index === 0) {
return this.removeFirst();
}
for (let current = this.first, i = 0; current; i++, current = current.next) {
if(i === index) {
if(!current.next) { // if it doesn't have next it means that it is the last
return this.removeLast();
}
current.previous = current.next;
this.size--;
return current.value;
}
}
}
Note that index is a zero-based index: 0 will be the first element, 1 second and so on.
Removing an element anywhere within the list is O(n).
Searching for an element in a linked list
Searching an element on the linked list is very somewhat similar to remove:
contains(value) {
for (let current = this.first, index = 0; current; index++, current = current.next) {
if(current.value === value) {
return index;
}
}
}
This function finds the first element with the given value.
The runtime for searching an element in a linked list is O(n)
Singly Linked Lists time complexity
Singly Linked List time complexity per function is as follows.
| Operation | Runtime | Comment |
|---|---|---|
addFirst |
O(1) | Insert element to the beginning of the list |
addLast |
O(n) | Insert element to the end of the list |
add |
O(n) | Insert element anywhere in the list. |
removeFirst |
O(1) | Remove element to the beginning of the list |
removeLast |
O(n) | Remove element to the end of the list |
remove |
O(n) | Remove any element from the list |
contains |
O(n) | Search for an element from the list |
Notice that every time we are adding/removing from the last position the operation takes O(n)...
But we could reduce the
addLast/removeLastfrom O(n) to a flat O(1) if we keep a reference of the last element!
We are going to add the last reference in the next section!
Doubly Linked Lists
When we have a chain of nodes where each one points to the next one we a Singly Linked list. When we have a linked list where each node leads to the next and the previous element we a Doubly Linked List

Doubly linked list nodes have double references (next and previous). We are also going to keep track of the list first and the last element.
class Node {
constructor(value) {
this.value = value;
this.next = null;
this.previous = null;
}
}
class LinkedList {
constructor() {
this.first = null; // head/root element
this.last = null; // last element of the list
this.size = 0; // total number of elements in the list
}
// ...
}
Adding and Removing from the start of a list
Adding and removing from the start of the list is simple since we have this.first reference:
addFirst(value) {
const node = new Node(value);
node.next = this.first;
if(this.first) {
this.first.previous = node;
} else {
this.last = node;
}
this.first = node; // update head
this.size++;
return node;
}
Notice, that we have to be very careful and update the previous, size and last.
removeFirst() {
const first = this.first;
if(first) {
this.first = first.next;
if(this.first) {
this.first.previous = null;
}
this.size--;
return first.value;
} else {
this.last = null;
}
}
What's the runtime?
Adding and removing elements from a (singly/doubly) LinkedList has a constant runtime O(1)
Adding and removing from the end of a list
Adding and removing from the end of the list is a little tricky. If you checked in the Singly Linked List, both operations took O(n) since we had to loop through the list to find the last element. Now, we have the last reference:
addLast(value) {
const node = new Node(value);
if(this.first) {
let currentNode = this.first;
node.previous = this.last;
this.last.next = node;
this.last = node;
} else {
this.first = node;
this.last = node;
}
this.size++;
return node;
}
Again, we have to be careful about updating the references and handling special cases such as when there's only one element.
removeLast() {
let current = this.first;
let target;
if(current && current.next) {
current = this.last.previous;
this.last = current;
target = current.next;
current.next = null;
} else {
this.first = null;
this.last = null;
target = current;
}
if(target) {
this.size--;
return target.value;
}
}
Using a doubly linked list, we no longer have to iterate through the whole list to get the 2nd last elements. We can use directly this.last.previous and is O(1).
Did you remember that for the Queue we had to use two arrays? Now, we can change that implementation an use a doubly linked list instead that has an O(1) for insert at the start and deleting at the end.
Adding an element anywhere from a linked list
Adding an element on anywhere on the list leverages our addFirst and addLast functions as you can see below:
add(value, index = 0) {
if(index === 0) {
return this.addFirst(value);
}
for (let current = this.first, i = 0; i <= this.size; i++, current = (current && current.next)) {
if(i === index) {
if(i === this.size) { // if it doesn't have next it means that it is the last
return this.addLast(value);
}
const newNode = new Node(value);
newNode.previous = current.previous;
newNode.next = current;
current.previous.next = newNode;
if(current.next) { current.next.previous = newNode; }
this.size++;
return newNode;
}
}
}
If we have an insertion in the middle of the array, then we have to update the next and previous reference of the surrounding elements.
Adding an element anywhere within the list is O(n).
Doubly Linked Lists time complexity
Doubly Linked List time complexity per function is as follows:
| Operation | Runtime | Comment |
|---|---|---|
addFirst |
O(1) | Insert element to the beginning of the list. |
addLast |
O(1) | Insert element to the end of the list. |
add |
O(n) | Insert element anywhere in the list. |
removeFirst |
O(1) | Remove element to the beginning of the list. |
removeLast |
O(1) | Remove element to the end of the list. |
remove |
O(n) | Remove any element from the list |
contains |
O(n) | Search for any element from the list |
Doubly linked lists are a significant improvement compared to the singly linked list! We improved from O(n) to O(1) by:
- Adding a reference to the previous element.
- Holding a reference to the last item in the list.
Removing first/last can be done in constant-time; however, eliminating in the middle of the array is still O(n).
Stacks
Stacks is a data structure where the last entered data is the first to come out. Also know as Last-in, First-out (LIFO).

Let's implement a stack from scratch!
class Stack {
constructor() {
this.input = [];
}
push(element) {
this.input.push(element);
return this;
}
pop() {
return this.input.pop();
}
}
As you can see is easy since we are using the built-in Array.push and Array.pop. Both have a runtime of O(1).
Let's see some examples of its usage:
const stack = new Stack();
stack.push('a');
stack.push('b');
stack.push('c');
stack.pop(); // c
stack.pop(); // b
stack.pop(); // a
The first in (a) as the last to get out. We can also implement stack using a linked list instead of an array. The runtime will be the same.
That's all!
Queues
Queues are a data structure where the first data to get in is also the first to go out. A.k.a First-in, First-out (FIFO).
It's like a line of people at the movies, the first to come in is the first to come out.

We could implement a Queue using an array, very similar to how we implemented the Stack.
Queue implemented with Array(s)
A naive implementation would be this one using Array.push and Array.shift:
class Queue {
constructor() {
this.input = [];
}
add(element) {
this.input.push(element);
}
remove() {
return this.input.shift();
}
}
What's the time complexity of Queue.add and Queue.remove?
-
Queue.addusesarray.pushwhich has a constant runtime. Win! -
Queue.removeusesarray.shiftwhich has a linear runtime. Can we do better thanO(n)?
Think a way you can implement a Queue only using Array.push and Array.pop.
class Queue {
constructor() {
this.input = [];
this.output = [];
}
add(element) {
this.input.push(element);
}
remove() {
if(!this.output.length) {
while(this.input.length) {
this.output.push(this.input.pop());
}
}
return this.output.pop();
}
}
Now we are using two arrays rather than one.
const queue = new Queue();
queue.add('a');
queue.add('b');
queue.remove() // a
queue.add('c');
queue.remove() // b
queue.remove() // c
When we remove something for the first time, the output array is empty. So, we insert the content of input backward like ['b', 'a']. Then we pop elements from the output array. As you can see, using this trick we get the output in the same order of insertion (FIFO).
What's the runtime?
If the output has already some elements, then the remove operation is constant O(1). When the output arrays need to get refilled, it takes O(n) to do so. After the refilled, every operation would be constant again. The amortized time is O(1).
We can achieve a Queue with a pure constant if we use a LinkedList. Let's see what it is in the next section!
Queue implemented with a Doubly Linked List
We can achieve the best performance for a queue using a linked list rather than an array.
const LinkedList = require('../linked-lists/linked-list');
class Queue {
constructor() {
this.input = new LinkedList();
}
add(element) {
this.input.addFirst(element);
}
remove() {
return this.input.removeLast();
}
get size() {
return this.input.size;
}
}
Using a doubly linked list with the last element reference we achieve an add of O(1). That's the importance of using the right tool for the right job 💪
Summary
We explored most of the linear data structures. We saw that depending on how we implement the data structures there are different runtimes. Go to the top which has a table with all the examples we explored here.

Top comments (1)
Greta read for someone that needs a introduction this stuff like me. noticed that in (part 3 -> Singly Linked Lists ->Adding/Removing an element from the beginning of a linked list)
you use addFirst function for removing and adding to first so i cheked your webbsite and notice that you use a diffrent one there.