
Google has announced a new experimental tool – the Gemini Embedding text vectorization model. It has been added to the Gemini-based developer API.
Text vectorization models convert text data, such as words and phrases, into numerical representations – so-called embeddings, which capture the semantic meaning of the text. In particular, embeddings are used in programs for searching and classifying documents, allowing to speed up the task and reduce its cost.
The company has previously released other vectorization models, but this is the first such tool trained on the Gemini family. In its blog, Google reported that the model "inherits Gemini's understanding of language and contextual nuances," which makes it applicable in a wide range of applications. The training focused on general topics, which ensures that the tool works equally well with texts from finance, science, law and other fields.
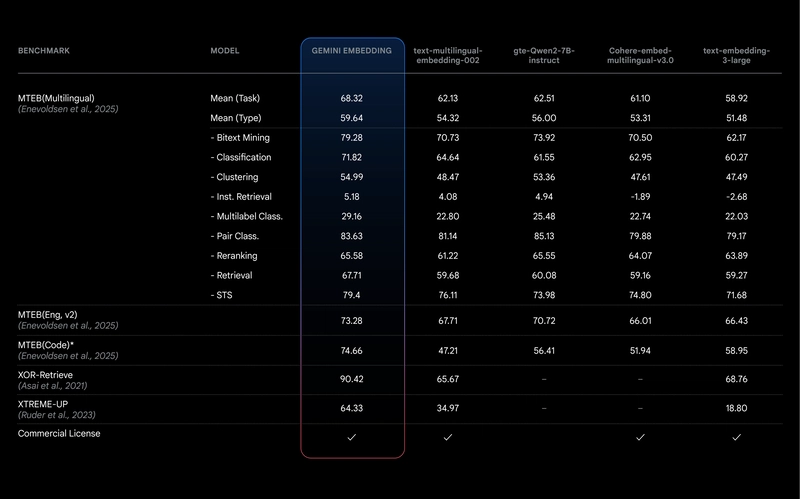
According to the company, Gemini Embedding shows higher performance results in key benchmarks compared to Google's previous text vectorization model, text-embedding-004. In particular, it can process larger pieces of text or code and supports twice as many languages, namely more than a hundred.
Currently, the tool is in an "experimental phase", has limitations (its input token limit is limited to 8 thousand) and is undergoing changes during development. As indicated in the blog, the full version of the model is expected to be released in a few months.
Comparison of the new model with previous analogs by key benchmarks / developers.googleblog.com

Top comments (0)