Learn step by step how to build, train and make predictions on a video classification task with 3 simple tools: Lightning Flash, PyTorch Video, and Kornia.

Video Understanding enables computers to recognize actions, objects, and events in videos. From Retail, Health Care to Agriculture, Video Understanding enables automation of countless industry use cases.

Facebook AI Researchrecently released a new library called PyTorchVideo powered by PyTorch Lightning that simplifies video understanding by providing SOTA pre-trained video models, datasets, and video-specific transformers. All the library’s models are highly optimized for inference and support different datasets and transforms.
Lightning Flash is a collection of tasks for fast prototyping, baselining, and fine-tuning scalable Deep Learning models, built on PyTorch Lightning. It allows you to train and finetune models without being overwhelmed by all the details, and then seamlessly override and experiment with Lightning for full flexibility. Learn more about Flash here.
PyTorchLightning/lightning-flash
In its new coming release, PyTorch Lightning Flash will provide a deep integration with PyTorchVideo and its backbones and transforms can be used alongside Kornia ones to provide a seamless preprocessing, training, and fine-tuning experience of SOTA pre-trained video classification models.
Kornia is a differentiable computer vision library for PyTorch that consists of a set of routines and differentiable modules to solve generic computer vision problems.
In this article you will learn how to train a custom video classification model in 5 simple steps using PyTorch Video, Lightning Flash, and Kornia, using the Kinetics dataset.

Keep reading to train your own model in a flash!
5 Simple Steps for Video Classification
Before we get started all the steps in this tutorial are reproducible and can be run with the free trial of Grid by clicking the Run button below.

The Grid Platform enables you to seamlessly train hundreds machine learning models on the cloud from your laptop without modifying your code in a fully reproducible manner.
Find the full end-to-end code for this tutorial code here and the full reproducible run here on ** Grid **.
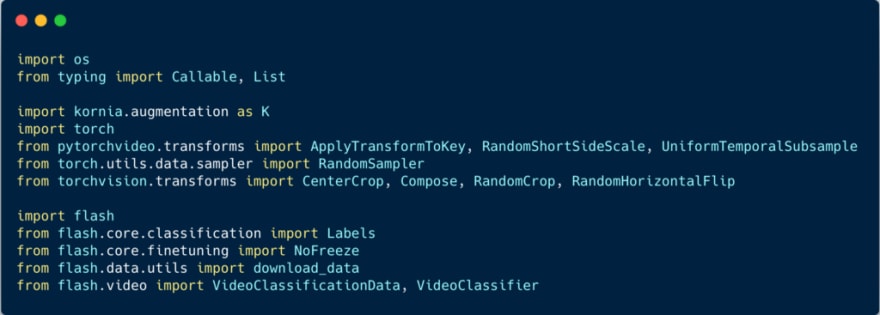
Prerequisite Imports
Step 1- Download The Kinetics Dataset

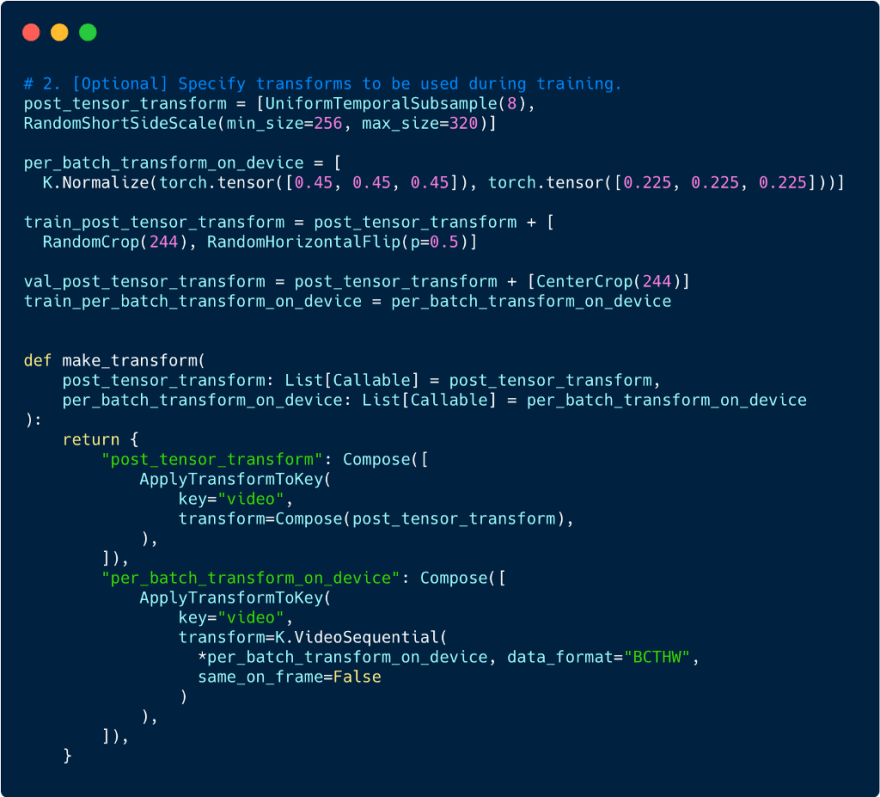
Step 2- Specify Kornia Transforms to Apply to Video

As videos are memory-heavy objects, data sampling and data augmentation play a key role in the video model training procedure and need to be carefully crafted to reach SOTA results.
Flash optimizes this process as transforms can be provided with simple dictionary mapping between hooks and the transforms. Flash hooks are simple functions that can be overridden to extend Flash’s functionality.
In the code below, we use the post_tensor_transform hook to uniformly select 8 frames from a sampled video clip and resize them to 224 pixels. This is done in parallel within each of the PyTorch DataLoader workers.
We also use the per_batch_transform_on_device hook to enable Kornia normalization to be applied directly to a batch already moved to GPU or TPU .
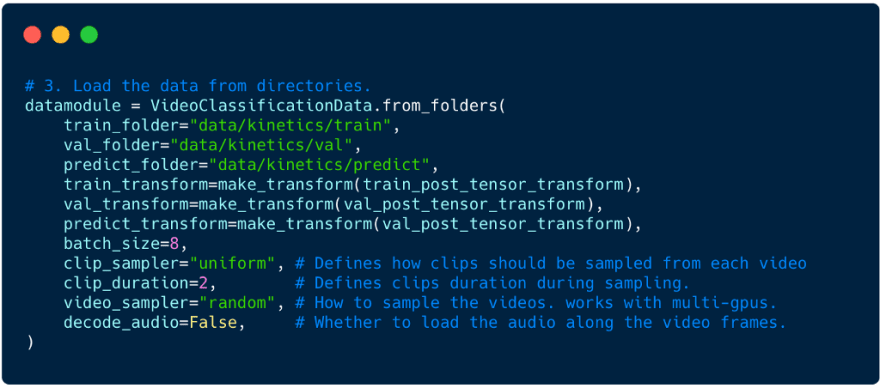
Step 3- Load the Data
Lightning DataModules are shareable, reusable objects that encapsulate all data-related code. Flash enables you to quickly load videos and labels from various formats such as config files or folders into DataModules.
In this example, we use the Flash from_folders helper function to generate a DataModule. To use the from_folders functions videos should be organized into folders for each class as follows:
dir_path//
Step 4- Instantiate the VideoClassifier with a pre-trained Model Backbone .
Training a SOTA video classifier from scratch on Kinetics can take around 2 days on 64 GPUS. Thankfully, the Flash Backbones Registry API makes it easy to integrate individual models as well as entire model hubs with Flash.
By default, the PyTorchVideo Model Hub is pre-registered within the Video Classifier Task Backbone Registry.
You can list any of the available backbones and get more details as follows:

Once you pick a backbone, you can initialize it with just one line of code:

Note: Serializers are optional components that can be passed to Flash Classifiers that enable you to configure how to format the output of the Task Predictions asLogits, Probabilities , or Labels. Read more here.
Step 5- FineTune Model
Once we have a DataModule and VideoClassifier, we can configure the Flash Trainer. Out of the box, the Flash Trainer supports all the Lightning Trainer flags and tricks you know and love including distributed training, checkpointing, logging, mixed precision, SWA, quantization, early stopping, and more.
In addition to enabling you to train models from scratch the Flash Trainer provides quick access to a host of strategies for fine-tuning pre-trained models on new data.

In this example, we use the NoFreeze Strategy in which the backbone will be entirely trainable from the start. You can even define your own custom FineTuning Strategies .
Conclusion
With these 5 simple steps you can now train your own Video Classification model on any Video Dataset. Once a model is trained, it can easily be saved and reused later for making predictions.
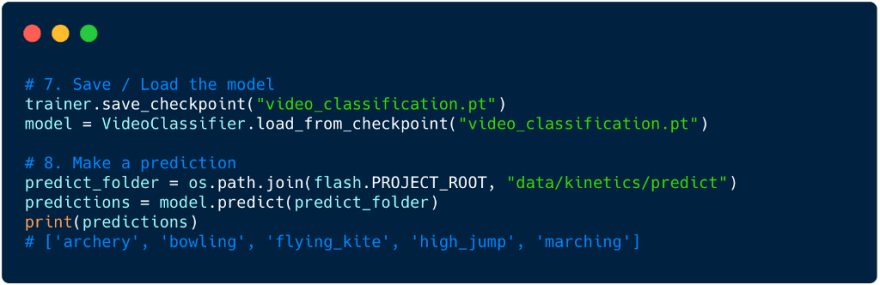
One major advantage of using PyTorch Video backbones is that they are optimized for mobile. With Lightning, models can be saved and exported as classic PyTorch Checkpoints or optimized for inference on the edge with ONNX and or TorchScript.
Find the end-to-end tutorial code ** here **.
We thank Tullie Murrell from the PyTorchVideo team for the support and feedback leading to this integration in Flash.
Next Steps
Now that you have train your first model it’s time to experiment. Flash Tasks provide full access to all the Lightning hooks that can be overridden as you iterate towards the state of the art.
Check out the following links to learn more:
About the Authors
Aaron (Ari) Bornstein is an AI researcher with a passion for history, engaging with new technologies and computational medicine. As Head of Developer Advocacy at Grid.ai, he collaborates with the Machine Learning Community, to solve real-world problems with game-changing technologies that are then documented, open-sourced, and shared with the rest of the world.
Thomas Chaton is PyTorch Lightning Research Engineering Manager. Previously, Senior Research Engineer at Fujitsu AI and Comcast-Sky Labs, Thomas is also the creator of TorchPoints3D.

Top comments (0)