
Speed matters. A slow backend frustrates users, increases server costs, and holds back scalability. That’s where caching comes in. It can make response times lightning-fast, reduce database load, and help your system handle more traffic with ease.
But caching isn’t a magic fix. The right strategy can make your application blazing fast, while the wrong one can cause stale data, wasted memory, or even more complexity.
What is Caching and Why Does It Matter?
Caching stores frequently used data in fast-access memory instead of repeatedly fetching it from a slow backend, like a database or external API. Done right, caching can:
Make responses nearly instant—cached data loads in microseconds.
Reduce database load—less strain on your primary data store.
Lower latency—faster experiences for users.
Improve scalability—handle more traffic with the same resources.
Without caching, every request forces the system to do extra work, slowing everything down. But picking the wrong caching method can lead to stale data, wasted resources, or unnecessary complexity.
Here are six strategies that actually work.
1. Cache Aside (Lazy Loading) - The Most Common Approach
How it works:
The application checks the cache before querying the database.
If the data exists in the cache, it's returned immediately.
If not, it's fetched from the database, stored in the cache, and returned.
Best for:
Frequently accessed data like user profiles, product details, or settings.
Applications where occasional cache misses aren't a big deal.
Pros:
→ Reduces database load by reusing cached data.
→ Simple to implement with Redis or Memcached.
→ Automatically updates when cache expires.
Cons:
→ Cache misses cause slower responses.
→Data can become stale without an expiration strategy.
Example in Node.js (Redis + Express):
const redis = require("redis");
const client = redis.createClient();
const db = require("./database");
app.get("/user/:id", async (req, res) => {
const userId = req.params.id;
client.get(userId, async (err, cachedData) => {
if (cachedData) {
return res.json(JSON.parse(cachedData));
}
const user = await db.getUserById(userId);
client.setex(userId, 3600, JSON.stringify(user));
res.json(user);
});
});
Cache Aside works well for most applications but needs proper cache eviction policies to prevent stale data.
2. Write-Through Caching - Ensuring Consistency
How it works:
Every write operation updates the cache and the database simultaneously.
Reads always come from the cache, ensuring consistency.
Best for:
Data that needs to stay fresh (e.g., session info, configuration settings).
Use cases where every write operation should be reflected in the cache instantly.
Pros:
→ Guarantees the latest data is always cached.
→ Faster reads since all data is preloaded in the cache.
Cons:
→ Writes are slower because they update two places.
→ Unused cache entries take up memory.
Example:
app.post("/update-user", async (req, res) => {
const { id, name } = req.body;
await db.updateUser(id, name);
client.set(id, JSON.stringify({ id, name }));
res.json({ success: true });
});
Write-Through Caching works best when fresh data is a priority, but it can create unnecessary writes when cache storage isn’t being fully utilized.
3. Read-Through Caching - Automating Cache Population
How it works:
The caching system automatically retrieves missing data from the database and stores it.
The application interacts with the cache only, never directly with the database.
Best for:
Applications that use managed caching services like AWS ElastiCache.
Situations where cache misses should be handled automatically.
Pros:
→ Simplifies code since the cache handles data retrieval.
→ Ensures cache is always populated with relevant data.
Cons:
→ Less control over cache behavior.
→ Requires a dedicated caching system like Redis Cluster.
Read-Through Caching makes life easier for developers but depends on a strong caching layer to handle misses efficiently.
4. Write-Behind (Write-Back) Caching - High-Performance Writes
How it works:
Data is written only to the cache first.
The database updates asynchronously in the background.
Best for:
High-write scenarios like logging, analytics, and event tracking.
Pros:
→ Super-fast writes reduce database load.
→ Efficient for bulk processing.
Cons:
→ Risk of data loss if the cache fails before syncing to the database.
→Requires careful failover mechanisms.
Write-Behind caching works well in high-performance systems, but data durability must be considered.
5. Distributed Caching - Handling Large-Scale Traffic
How it works:
Data is stored across multiple cache servers instead of a single node.
Requests are routed to different cache nodes based on a hashing algorithm.
Best for:
High-traffic applications like Facebook, Netflix, or Amazon.
Microservices architectures where multiple services share cached data.
Pros:
→ Scales horizontally to handle large workloads.
→ Prevents cache server overload.
Cons:
→ More complex cache management.
→ Synchronizing data across multiple nodes can be tricky.
Distributed caching is essential for large-scale apps but requires strong cache eviction and consistency strategies.
6. Content Delivery Network (CDN) Caching - Making Static Content Blazing Fast
How it works:
Static files (CSS, JS, images, API responses) are stored in edge servers around the world.
Requests get served from the closest edge location instead of the origin server.
Best for:
Websites with global traffic.
APIs that serve static or rarely changing data.
Pros:
→ Reduces server load dramatically.
→ Speeds up load times for users worldwide.
Cons:
→ Cached content can become outdated without proper cache invalidation.
Use Cloudflare, AWS CloudFront, or Fastly for static caching to boost speed without stressing backend servers.
Which Caching Strategy Should You Use?
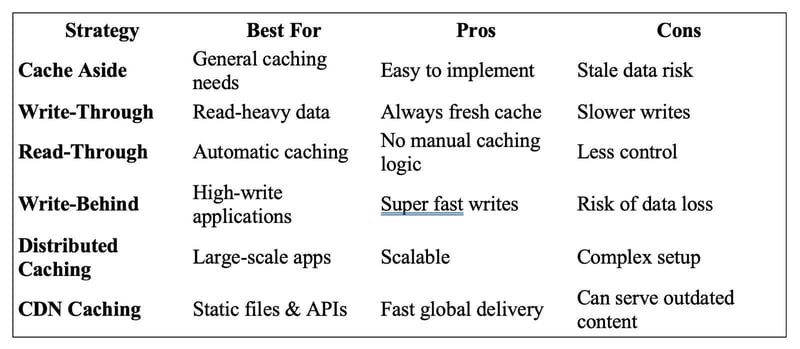
Most applications combine multiple caching strategies for the best performance. Choose wisely, and your backend will feel effortless even under heavy load.
You may also like:
- 10 Common Mistakes with Synchronous Code in Node.js
- Why 85% of Developers Use Express.js Wrongly
- Implementing Zero-Downtime Deployments in Node.js
- 10 Common Memory Management Mistakes in Node.js
- 5 Key Differences Between ^ and ~ in package.json
- Scaling Node.js for Robust Multi-Tenant Architectures
- 6 Common Mistakes in Domain-Driven Design (DDD) with Express.js
- 10 Performance Enhancements in Node.js Using V8
- Can Node.js Handle Millions of Users?
- Express.js Secrets That Senior Developers Don’t Share Read more blogs from Here
Share your experiences in the comments, and let’s discuss how to tackle them!
Follow me on Linkedin

Top comments (0)