
Need for capacity planning
Kubernetes automates much of the work of managing containers at scale. But containerized applications commonly share pooled resources, so one needs to allocate and manage them properly.
Kubernetes provides options to manage all key resources – compute, memory, and storage – for pods that are scheduled to run on it, but Clusters don’t have indefinite resources. It means applications are commonly sharing pooled resources. The “right” way to allocate these resources will vary across organizations and applications, but the good news is that Kubernetes includes a lot of features for resource management.
The most common 4 limited capacity factors in managing the environment are:
- Utilization
- Requests
- Limits
- Quotas
Utilization
Container pods consume memory and CPU from their underlying nodes. High utilization often leads to performance issues, efficient placement of Pods on nodes enables best usage of the underlying infrastructure
Requests
Requests are guaranteed capacity for a container. If a Pod is scheduled and no node has enough request capacity – it will not be scheduled. Right sizing requests for all individual containers will allow more pods to be placed into the environment safely.
Limits
Limits determine the maximum amount of CPU & memory that can be used by a container at runtime. Nodes can be overcommitted on limits (as opposed to requests). i.e. the sum of the limits can be higher than the nodes resources. If a scheduled pod crosses it's CPU limit, it will be throttled and if it cross the memory limit then the pod is terminated (and restarted) with a OOM error.
Limit management is often a balance, undercommitting leads to resource wastage (where pods cannot be optimally scheduled), overcommitting as above may risk running out of resources.
Quotas
Quotas are a mechanism of rationing resources, generally imposed at a namespace level. Note that it has no direct bearing to the actual utilization on the cluster, or the available capacity for the cluster as a whole.
Utilization problem occurs because the Kubernetes scheduler does not re-evaluate the pod’s resource needs after a pod is scheduled with a given set of requests. As a result, over-allocated resources are not freed or scaled-down. Conversely, if a pod didn’t request sufficient resources, the scheduler won’t increase them to meet the higher demand.
To summarize:
- If you over-allocate resources: you add unnecessary workers, waste unused resources, and increase your monthly bill.
- If you under-allocate resources: resources will get used up quickly, application performance will suffer, and the kubelet may start killing pods until resource utilization drops.
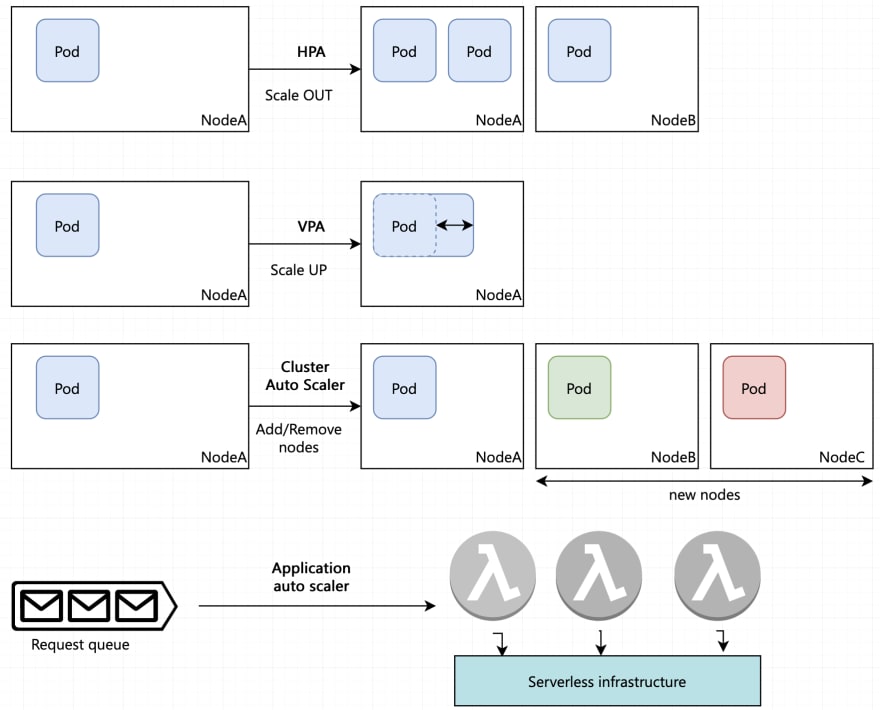
Kubernetes can scale in three dimensions – increasing the number of pods, pod size and nodes in the cluster. It can scale based on server metrics like CPU and memory or custom metrics like the number of requests per second per pod.
How they work HPA and VPA work based on metrics derived out of utilization using prometheus, metrics server and other systems
VPA/Goldilocks
Audience: Developer
For simple Deployments or ReplicaSets (that are not stateful), VPA suggests values of requested pod resources and provides those values as recommendations for future Deployments. Alternatively, we can configure VPA to auto-apply those values to our Deployment objects.
Note: VPA doesn't properly support stateful workloads yet
Detailed info https://www.densify.com/kubernetes-autoscaling/kubernetes-vpa
Goldilocks uses the Recommender in the VPA to make recommendations. The recommendations generated by Goldilocks are based on historical usage of the pod over time, so your decisions are based on more than a single point in time.
Goldilocks shows two types of recommendations in the dashboard. These recommendations are based on Kubernetes Quality of Service (QoS) classes. Using Goldilocks, we generate two different QoS classes of recommendation from the historical data:
- For Guaranteed, we take the target field from the recommendation and set that as both the request and limit for that container. This guarantees that the resources requested by the container will be available to it when it gets scheduled, and generally produces the most stable Kubernetes clusters.
- For Burstable, we set the request as the lowerBound and the limit as the upperBound from the VPA object. The scheduler uses the request to place the pod on a node, but it allows the pod to use more resources up to the limit before it’s killed or throttled. This can be helpful for handling spiky workloads, but overuse can result in over-provisioning a node.
Detailed info https://www.civo.com/learn/fairwinds-goldilocks-kubernetes-resource-recommendation-tool
HPA
Audience: Developer
HPA scales the application pods horizontally by running more copies of the same pod (assuming that the hosted application supports horizontal scaling via replication).
Note: Idempotency and scalability in-terms of statelessness of the pod to be scaled is important when using a HPA
Detailed info https://www.kubecost.com/kubernetes-autoscaling/kubernetes-hpa/
Cluster autoscaler
Audience: Operator
The cluster autoscaler increases the size of the cluster when there are pods that are not able to be scheduled due to resource shortages. It can be configured to not scale up or down past a certain number of machines.
Note: Cluster autoscaler needs to be supported by the kubernetes flavor being used and is generally not a part of vanilla kubernetes.
Detailed info https://medium.com/kubecost/understanding-kubernetes-cluster-autoscaling-675099a1db92
Scaling applications/serverless workloads
Audience: Operator or Infrastructure provider
In serverless computing, scaling happens as per the application itself. For instance, Lambda can auto-scale exponentially up to burst traffic. After that, linearly up to concurrent limits. These limits apply to all functions in a region, so care needs to be taken that the maximum concurrent instances in applications falls below the limits. The concurrency limit encourages fine grained function with small execution times.
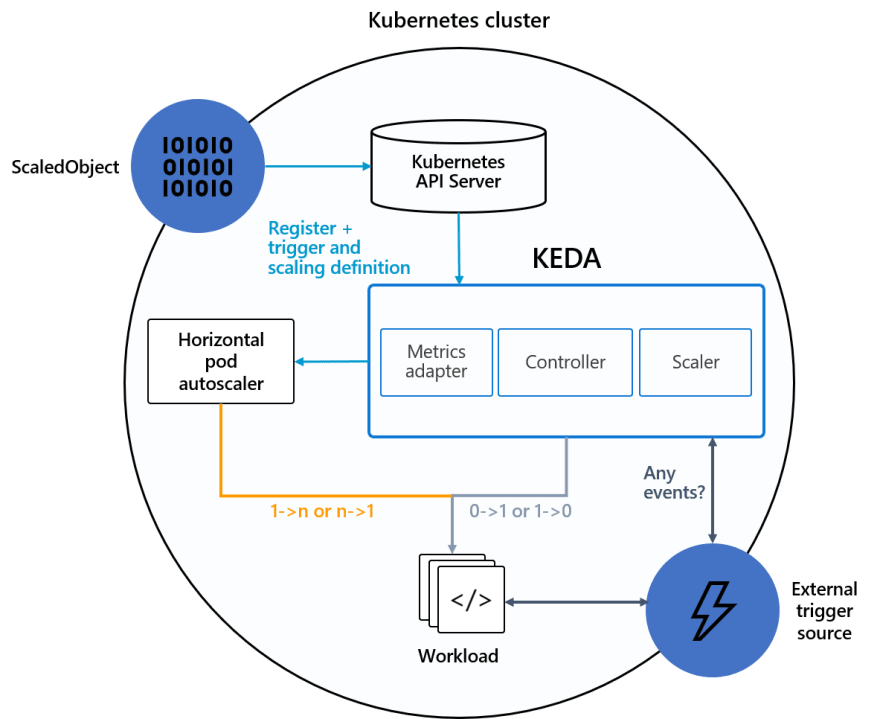
KEDA
KEDA provides a way to scale event-driven applications based on demand observed from event brokers. KEDA expands the capability of the native Kubernetes Horizontal Pod Autoscaler and is an open source CNCF incubating project.
How KEDA works
When scaling event-driven microservices, the number of messages on a consumer’s input queue is essentially the number of events that need to be processed. Message count, or queue backlog, is an excellent indicator for demand on a given microservice in that:
- If an input queue for a microservice is backed up with lots of messages, we know that demand is high and the microservice should be scaled out.
- If the message count is low (below a defined threshold), then demand is low and the microservice should be scaled down.
Case study https://solace.com/blog/scaling-microservices-with-kubernetes-keda-and-solace/
Useful links
https://blog.turbonomic.com/kubernetes-resource-management-best-practices
https://cast.ai/blog/guide-to-kubernetes-autoscaling-for-cloud-cost-optimization/

Top comments (0)