Amazon Aurora is a MySQL and PostgreSQL-compatible relational database designed for the cloud. AWS claims that with some workloads Aurora can deliver up to 5x the throughput of MySQL and up to 3x the throughput of PostgreSQL without requiring any application changes. Aurora can do this because its storage subsystem was specifically designed to run on AWS’ fast distributed storage; in other words, Aurora was designed with cloud resources in mind, while those other “non-cloud only” databases are simply running on cloud resources. This design approach allows for automatic storage growth as needed, up to a cluster volume maximum size of 128 tebibytes (TiB) and offers 99.99% availability by replicating six copies of your data across three Availability Zones and backing up your data continuously to Amazon S3. It transparently recovers from physical storage failures; instance failover typically takes less than 30 seconds.
Note: A tebibyte (TiB) is a unit of measure used to describe computing capacity. The prefix tebi comes from the power-of-2 (binary) system for measuring data capacity. That system is based on powers of two. A terabyte (the unit normally seen on disk drives and RAM) is a power-of-10 multiplier, a “simpler” way of looking at the value. Thus, one terabyte = 1012 bytes, or 1,000,000,000,000 bytes as opposed to one tebibyte, which equals 240 bytes, or 1,099,511,627,776 bytes
Also, because of this customized design, Aurora can automate and standardize database replication and clustering. The last uniquely Aurora feature is the ability to use push-button migration tools to convert any already-existing RDS for MySQL and RDS for PostgreSQL applications to use RDS for Aurora instead. The argument for this ease in migration, and for Amazon Aurora in general, is that even though Aurora may be 20% more expensive than MySQL, Amazon claims that Aurora is 5x faster than MySQL, has 3x the throughput of standard PostgreSQL, and is able to scale to much larger datasets.
Creating an Amazon Aurora database in RDS
Let’s next look at creating a new Aurora database. First, log into the console, go to RDS, select Create database. On the Create Database screen, select Standard create and then Aurora. This should bring up some Aurora-specific sections as shown in Figure 1.
 Figure 1. Selecting edition and capacity type when building an Aurora database
Figure 1. Selecting edition and capacity type when building an Aurora database
The first selection, Edition, asks you to determine whether you wish a MySQL or PostgreSQL compatible edition.
MySQL compatible edition
The default selection when creating an Aurora database is MySQL, as shown above in Figure 1. By making this choice, values will be optimized for MySQL and default filters will be so set for the options within the Available versions dropdown. The next area, Capacity type, provides two choices: Provisioned and Serverless. Selecting a provisioned capacity type will require you to select the number and instance classes that you will need to manage your workload as well as determine your preferred Availability & durability settings as shown in Figure 2.
 Figure 2. Settings for creating a provisioned database
Figure 2. Settings for creating a provisioned database
Selecting the serverless capacity type, on the other hand, simply requires you to select a minimum and maximum value for capacity units as shown in Figure 3. A capacity unit is comparable to a specific compute and memory configuration. Based on the minimum capacity unit setting, Aurora creates scaling rules for thresholds for CPU utilization, connections, and available memory. Aurora then reduces the resources for the DB cluster when its workload is below these thresholds, all the way down to the minimum capacity unit.
 Figure 3. Capacity settings when creating a serverless database
Figure 3. Capacity settings when creating a serverless database
You also have the ability to configure additional aspects around scaling using the Additional scaling configuration options. The first value is Autoscaling timeout and action. Aurora looks for a scaling point before changing capacity during the autoscaling process. A scaling point is a point in time when no transactions or long-running queries are in process. By default, if Aurora can't find a scaling point within the specified timeout period, it will stop looking and keep the current capacity. You will need to choose the Force the capacity change option to make the change even without a scaling point. Choosing this option can affect any in-process transactions and queries. The last selection is whether you want the database to Scale the capacity to 0 ACUs when cluster is idle. The name of the option pretty much tells the story; when that item is selected then your database will basically shut off when not being used. It will then scale back up as requests are generated. There will be a performance impact on that first call, however, you will also not be charged any processing fees.
The rest of the configuration sections on this page are the same as they have been for the previous RDS database engines that we have just gone through.
PostgreSQL compatible edition
Selecting to create a PostgreSQL-compatible Aurora database will give you very similar options as you would get when selecting MySQL. You have the option to select either a Provisioned or Serverless capacity type, however, when selecting the serverless capacity type you will see that the default values are higher. While the 1 ACU setting is not available, the ability to scale to 0 capacity units when the cluster is idle is still supported.
There is one additional option that is available when creating a provisioned system, Babelfish settings. Aurora’s approach towards building compatibility with the largest OSS relational database systems has proven to be successful for those using those systems. AWS took the first step into building compatibility with commercial software by releasing Babelfish for Aurora PostgreSQL. As briefly touched on earlier, Babelfish for Aurora PostgreSQL is a new capability that enables Aurora to understand commands from applications written for Microsoft SQL Server as shown in Figure 4.
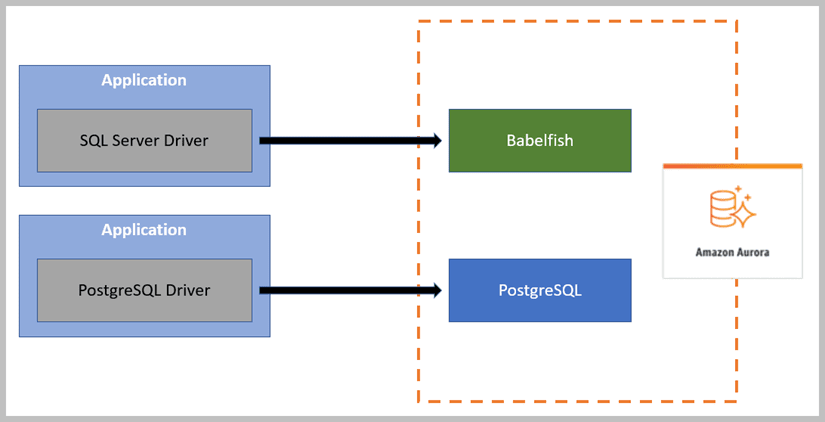 Figure 4. Accessing Amazon Aurora through Babelfish
Figure 4. Accessing Amazon Aurora through Babelfish
With Babelfish, Aurora PostgreSQL now “understands” T-SQL and supports the SQL Server communications protocol, so your .NET apps that were originally written for SQL Server will work with Aurora – hopefully with minimal code changes. Babelfish is a built-in capability of Amazon Aurora and has no additional cost, although it does require that you be using a version greater than PostgreSQL 13.4, which at the time of this writing was not available on Serverless and is why this option is unable to be selected from that mode.
Amazon Aurora and .NET
As briefly touched on earlier, the primary outcome of your making a choice between PostgreSQL and MySQL is that the choice determines how you will interact with the database. This means that using the MySQL-compatible version of Aurora requires the use of the MySql.EntityFrameworkCore NuGet packages, while connecting to the PostgreSQL-compatible edition requires the Npgsql and Npgsql.EntityFrameworkCore.PostgreSQL packages, just like they were used earlier in those posts in this series. If you are considering using Babelfish with the PostgreSQL-compatible, then you would use the standard SQL Server NuGet packages as we worked with in the last few posts.
This means that moving from MySQL on-premises to MySQL-compatible Aurora Serverless would require no code changes to systems accessing the database; the only change you would have to manage would be the connection string so that you can ensure that you are talking to the database. Same for PostgreSQL and even SQL Server. This approach for compatibility has made it much easier to move from well-known database systems to Amazon’s cloud-native database, Aurora.

Top comments (0)