How to bring workflow to Apache Kafka and why

In the last year I had a lot of contact with the community around Kafka and Confluent (the company behind Apache Kafka) — a community that is really awesome. For example, at Kafka Summit New York City earlier this year, I was impressed how many big banks attended, that currently modernize their architecture. And they are not only talking about it, they are doing it. Some have Kafka in production already, at the heart of their company. They are not necessarily early adopters at heart, but they understood the signs that they must move now — or their outdated IT will be an existential threat. I had great conversations, leaving all the “big vendor bullshit” aside — so it seems that golf course selling is finally on the decline in favor of searching proper answers for the IT architecture of the future.
And this is actually exactly what I see also happening with our customers. Probably that’s why Kafka and Confluent feel so much like soul mates to me. “Make Meaning” from Guy Kawasaki comes to my mind. We both make meaning and thus have a lot of impact in shaping the architectures of the future.

Sitting in NYC again today, I wanted to take that opportunity to write a blog post about why and how Zeebe can play so well together with Kafka. I will briefly introduce the products and explain joint use cases. I show which problems the products solve. And I will hint to technical implementations.
What’s Zeebe
Zeebe is a source-available, cloud-native workflow engine, mostly used for microservices orchestration. A great introduction can be found in What is Zeebe.
If you think workflow automation is just about human tasks and to-do lists (= boring), that’s a wrong impression. It is at the core of fully automated business processes, like order fulfillment, application management or claim management. For example our customer 24 Hour Fitness uses workflows for everything: from signing new contracts to even opening the door for you with your access card. I wrote about the variety of use cases in 5 Workflow Automation Use Cases You Might Not Have Considered.
Zeebe is based on cloud-native paradigms (see How we built a highly scalable distributed state machine), making it horizontally scalable and resilient.
Camunda is the open source vendor behind Zeebe providing an enterprise edition of Zeebe as well as a managed cloud offering.
What’s Kafka
Confluent is the open source vendor providing the Confluent Platform, containing Apache Kafka at the core. Apache Kafka is a highly scalable, resilient and persistent event bus. It might be used for high-throughput messaging, event-driven-architectures, as event-store or to back event-streaming architectures. You can find a good intro in the Kafka docs.
Why combing Zeebe and Kafka
The products are not competing but complementary. And since both tools share basic scalability characteristics , they can both work in high-throughout or low-latency scenarios, making it a match made in heaven. And just to avoid any confusion: Even if Zeebe leverages a lot of distributed systems concepts in a very comparable way to Kafka, it is not based on Kafka, and Zeebe can be (and often is) used on its own. But because the products are complimentary, customers choose to combine them. Let’s explore possible combination scenarios.
Microservice Orchestration
You have a microservices architecture , where Kafka is used as message or event bus , this being the communication backbone of your environment. In this scenario, you have to implement end-to-end business processes on top of that architecture, typically requiring the interaction of multiple microservices. In this scenario you will use Zeebe for orchestration. So for example an order fulfillment service could leverage Zeebe to execute the order workflow, which sends commands via Kafka or wait for events in Kafka.
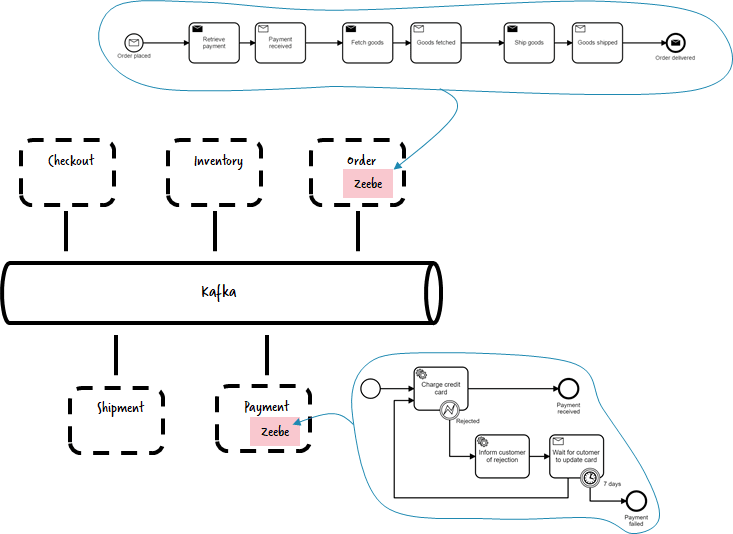
In this scenario Kafka solves the problem of communicating safely between microservices, and Zeebe solves the problem that you need stateful workflow patterns within certain microservices, like for example waiting for events for a longer period of time, having proper timeouts and escalations in place. I talked about this in Complex event flows in distributed systems and wrote about it in Why service collaboration needs choreography AND orchestration. You can either run multiple, de-centralized Zeebe instances, or you run multiple different workflows on one central Zeebe. Both is possible and valid — as always it depends. I wrote about this decision in The Microservices Workflow Automation Cheat Sheet.
Act on Insights of your Streams
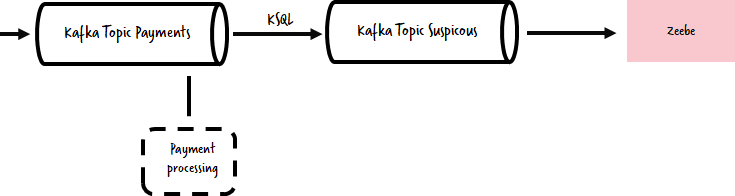
You might also have a streaming architecture with Kafka as centerpiece. Let’s assume you get payment events and check for suspicious transactions. Then you might kick off a workflow instance in Zeebe every time something is suspicious for further inspection. For this simple use case you could for example use the Kafka Connector for Zeebe.
Another interesting real-life use case example is in the area of vehicle maintenance. Assume that you have a huge amount of sensors that constantly send measurements (oil pressure is 80 psi) via Kafka. Now you have some clever logic generating insights based on these measures (oil pressure is critically high). All these insights are also sent via Kafka. But now you want to act on this information, e.g. to alert an operations person to organize some maintenance. In order to do so you have to get from the world of stateless event streams into the world of stateful workflows, from a world of a massive amount of information (the measures might be send every second) to a world with lower numbers, especially as you want to start a workflow only once per insight.
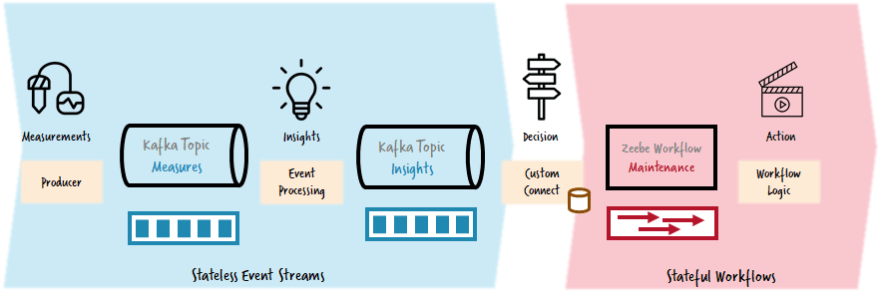
In the customer project this was done by a small connector, that read all records from Kafka, collected them over a short period of time in memory and aggregated the events to discover one action to do, like starting a maintenance workflow instance. The component can also discover if the oil pressure actually went back to normal, which is then reported to the running workflow instance.
In order to aggregate the insights, the project used a correlation identifier defined by the business requirements, so for example the vehicle id + sensor id + defect name. This made it easy to sort out duplicates. I plan to write a more in-depth article about this translation component, so follow me to make sure not to miss it.
Publish Zeebe Events via Kafka
Another interesting combination has a completely different angle: Zeebe writes a lot of audit information around workflows being executed. Many customers want to have this data published to their own data lake to allow powerful business reports like for example how long it takes to fulfill orders depending on the customer’s country, or if certain SLA’s are met. The architecture of Zeebe makes it easy to send some (or all) events to wherever you want, and Kafka makes it easy to transport even a big amount of events reliably to the destination.

Implementation approaches to combine Zeebe and Kafka
Now let’s quickly look at the three main contact points of Apache Kafka with Zeebe to better understand how we can implement the use cases above:
- Ingest messages (or events) from Kafka into Zeebe
- Publish messages (or events) onto Kafka from Zeebe
- Use Kafka as backbone for Zeebe history events
Ingest messages (or events) from Kafka into Zeebe
You can subscribe to messages or events on Kafka and either start a new workflow instance or correlate it to an existing, currently waiting workflow instance.
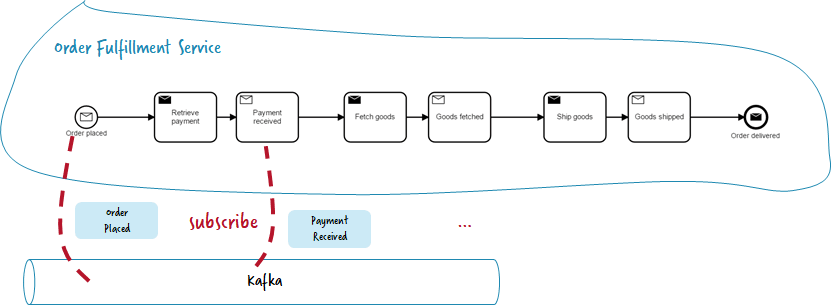
Technically this means
- Write some code, e.g. in Java, to subscribe to Kafka and use the Zeebe client. One example using Spring Boot and Spring Cloud can be found here. Of course you can also use the plain Kafka and Zeebe API.
- Use Kafka Connect and the Kafka connector for Zeebe, see this example on GitHub.
Publish messages (or events) onto Kafka from Zeebe
You can create Kafka records whenever a workflow instance reaches a certain activity.
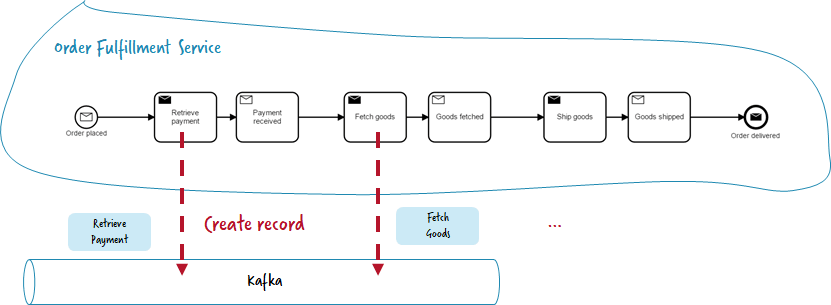
Technically this means
- Write some Zeebe workers, e.g. in Java, that create records in Kafka. One example using Spring Boot and Spring Cloud can be found here. Of course you can also use the plain Kafka and Zeebe API.
- Use Kafka Connect and the Kafka connector for Zeebe, see this example on GitHub.
Use Kafka as backbone for Zeebe history events
A less common example of the combination of both tools is to publish all history events of the the workflow engine via Kafka. This allows other components, like data lakes or reporting tools, to gather that information easily, for example which workflows got started or ended, which activities where executed or how much time was spend on it.
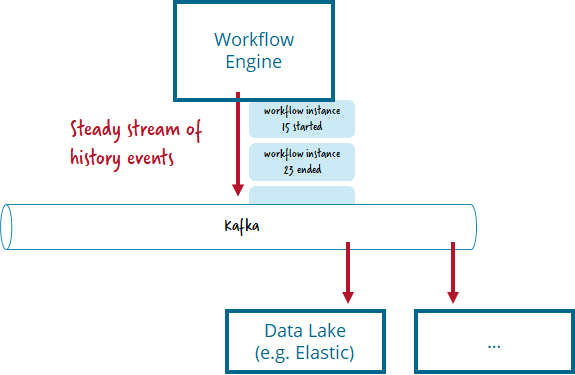
Technically this means to use a Zeebe exporter. The existing Zeebe Kafka Exporter might be exactly what you need — or a starting point to implement custom requirements.
If your Data Lake is using Elastic, you could also consider to use the Elasticsearch Exporter directly. While this of course increases coupling, it might be a good trade-off, depending on your overall architecture.
Summary
As you could see, there are good use cases to combine Kafka and Zeebe, and technically it is easy to do. We see more and more of our users really doing that in real-life, backing hypothesis we had. Finally the Kafka connector for Zeebe, which is soon to be supported, proofs the interest in such a combination.
To add a small, but important disclaimer after being so enthusiastic: Of course you do not always have to introduce Kafka when starting with Zeebe. Especially if you do a small project or probably just start your journey into new architectures it might be much better to start small, which means not to include all the latest and greatest technology right away. Unless you use the existing cloud service, you will need to invest a reasonable amount of effort to setup and operate Kafka. In the beginning it might be sufficient to know that the combination will be no problem some steps down the road.
So I want to conclude this post with special thanks to the confluent folks, who I regularly meet at different occasions which always leads to interesting discussions and insides…

 Neil Avery@avery_neil
Neil Avery@avery_neil nice to catch up with @berndruecker at #serverlesslondon17:03 PM - 07 Nov 2019
nice to catch up with @berndruecker at #serverlesslondon17:03 PM - 07 Nov 2019
0
6
Bernd Ruecker is co-founder and chief technologist of Camunda. He likes speaking about himself in the third-person. He is passionate about developer friendly workflow automation technology. Connect via LinkedIn or follow him on Twitter. As always, he loves getting your feedback. Comment below or send him an email.

Top comments (0)