
Written by Nicky Meuleman✏️
The JAMstack refers to the tools used to create a certain type of website, and it has seen a strong rise in popularity. In fact, its popularity has risen to the point that there are now entire conferences devoted to this method of building sites.
What is the JAMstack?
The JAM acronym stands for JavaScript, APIs, and Markup.
JavaScript is the programming language of choice to handle any dynamic programming needs. APIs are the kind your website talks to over the internet to get a wide variety of tasks done, from gathering data to sending an email. Markup usually refers to HTML.
JAMstack is a bad name!?
JAM doesn’t mention many of the important/exciting parts. One of the typical signs of the JAMstack is that there are no servers.
The M arkup is often prerendered during a build step. Before your website is put onto the worldwide web, a process runs that turns your site into a bunch of static files. Those files are then hosted on a CDN and served to the world.
Most of those aren’t hard requirements for your site to be considered a JAMstack site. A site that consist entirely out of fully filled-out HTML pages is very JAMstack-y, but HTML that’s less filled out is still JAMstack.

The JAMstack is a sliding scale.
Taking that to the extreme, Chris Coyier points out that an HTML document that contains <div id="root"></div> and some JavaScript also fits into the JAMstack.
@chriscoyier ❤ static hosting and cloud functions.
Would a <body><script src="react-bundle.js"></script></body> document hosted on a CDN be considered part of JAMstack?00:43 AM - 22 May 2019



@mjackson I’d say “yes”.
Perhaps a little more SSR would be good for all the reasons but meh, not required for a jamstack merit badge.00:52 AM - 22 May 2019

As with many things in life, the answer to the majority of your questions about what makes a JAMstack site is “it depends”. The same criticism is applicable to the term serverless. That term is also… not great.
JAMstack and serverless are often used together, by the way — like peanut butter and jelly. They each stand well on their own but are often used together. More on that below.

Before I list some advantages and disadvantages, I’d like to qualify all of them with an “it depends” statement. Because the JAMstack is so flexible, many of them may be more or less severe for your specific use case.
Upsides
Performance
Your website is turned into a bunch of static files. Once the browser receives those files, they turn into a website. Browsers are good at this; it’s what they do.
Those files are typically hosted on a CDN. That means they are distributed all over the world, ready to go. If you are in Belgium and visit a site made by someone in the US, no requests and responses need to travel across the Atlantic ocean.
Chances are, those files are available much closer to you. The combination on files that are ready to go, coupled with the proximity of those files, leads to better performance.
Security
The JAMstack often doesn’t use a traditional server, so you don’t need to worry about the security of something that doesn’t exist. The use of APIs instead means most of the security concerns lay with the creators of the APIs you consume.
(Lack of) cost
Hosting is cheap (or even free) if you use the type of JAMstack that prerenders as much as possible, and does the rest of the work on your visitor’s machine.
Scalability
Closely tied to the previous point. If hosting boils down to getting a collection of files to visitors, scaling becomes a much simpler issue. Usually, as the developer, you don’t even have to care about this: you upload those files to a CDN and sit back while your website about corgis blows up overnight.
Developer experience
Because the JAMstack is so flexible, that comes with a lot of freedom to choose the tools you want to use. At the end of the ride, a website is made out of JavaScript, CSS, HTML, and media. How you get there is up to you.
Much more…
SEO is often very good as a result of the static nature of many JAMstack sites.
Downsides
It’s not all (corgi) puppies and rainbows. If there is such a high emphasis on static files, doesn’t that, by definition, prevent dynamic content/dynamic behavior?
Well, not necessarily. One type of those files are JavaScript files. The A PIs in the JAM are a fine way to add a bit of dynamism into the mix. The degree to which you add that dynamism to the statically hosted assets is up to you.
Many static site generators (SSGs) handle the dynamic behavior part for you by using popular frameworks. You get to write in the framework you prefer, and the static generator handles turning your framework code into filled out static files.
On top of that, by using JavaScript, once you open those files in a browser, a process called hydration happens, and presto: it’s like it isn’t a static site at all, but a fully fledged framework site.
Gatsby for React and Gridsome for Vue are two of the most popular SSGs backed by a framework. Recently, Scully joined the party as SSG for Angular. Shawn Wang is working on one for Svelte, cleverly named SSG.
The generation of the static files has to be repeated when you make a change to the source files. The long build times caused by regenerating those files for an entire site excludes that type of static generation for many large sites.
Imagine if the entirety of amazon.com had to be rebuilt after correcting a spelling error in a single product description somewhere. Incremental builds is one way of reducing that pain. It’s still very much in the early stages or not available for many SSGs.
Overcoming the downsides
This is where serverless shines. Since there is no traditional server, many holes exist that can be plugged by the addition of some serverless functions.
A serverless function is not hosted in a single location. They complement the JAM. They pump up the JAM.
🎵 Serverless functions don’t want a place to stay. 🎵
🎵 They get their booty on the floor tonight and make my day. 🎵
🎵 Make my day, make my, make my, make, make my day. 🎵
The data debacle (alliterations are fun)
A specific pain point I’d like to highlight concerns data. Consider these two options:
- You use entirely pregenerated data
- You fetch data when someone visits your site during client time
For the first one, the data is right there, ready to go, but it might be stale/outdated by the time anyone views it.
For the second one, the data will be up to date, but during the time it is being fetched your users have to look at a spinner. If you put in some extra effort, they might have to look at a skeleton state instead.
Neither outcome is ideal. If your data is entirely static, however, the first option is obviously the best choice; if you are dealing with (almost) entirely dynamic data, the second one is better.
Do both
If only a part of the data changes often and the rest stays static, asking for it during both build and client time may be a suitable solution.
When someone visits your website, the data gathered during build time is already there. This results in a smooth and snappy experience where users aren’t looking at a circle on their screen, but actual, useful data.
A part of that data might be stale by the time the user sees it (and this may be represented, for example, by a number being grayed out). That’s why that same data is being requested again when you visit the website. As soon as the updated data arrives, it may swap with the (possibly stale) data gathered during build time.
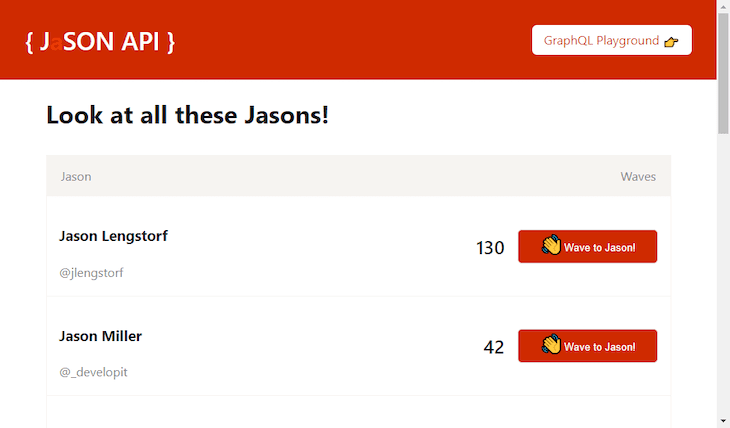
An example: The JaSON API
The JaSON API is a joke site I used to explore some exciting JAMstack technologies. It’s a Gatsby site that uses the technique described above to fetch data. That data comes from a serverless GraphQL endpoint.
It lists some people named Jason, optionally displays their Twitter handle, and shows the amount of times visitors to the site clicked a button to “wave” to them. The first two parts of that data rarely change (if at all) and are ideal candidates for static generation. The amount of waves, however, changes often and should be fetched when a user visits the site.
A React component is responsible for showing the list of Jasons when given an array of data.
<JasonList jasons={jasonArray} />
To get the jasonArray during build time, the data is gathered from the GraphQL endpoint. Using gatsby-source-graphql, that query looks like this:
export const GATSBY_QUERY = graphql`
{
JasonAPI {
allJasons {
id
name
twitter
likes
}
}
}
`;
Exactly the same data is requested as soon as someone visits the homepage. Using Apollo GraphQL, that query looks like this:
const APOLLO_QUERY = gql`
{
allJasons {
id
name
twitter
likes
}
}
`;
Notice the resulting data from these queries is exactly the same. The two queries request the same data, and the only difference is when that data is requested.
But be careful: the data gathered at client time differs from the data gathered at build time, but only a little. Otherwise, the experience of swapping the (possibly stale) build data for the up-to-date client-time data might change from smooth and snappy to jarring and flashy.
In the example, the data returned from the GraphQL endpoint always returns in the same order, and the only thing that changed is the amount of likes. Because React is smart, it will only update the parts of the DOM that changed.
This is the entire Gatsby page component, where the data gathered by the GATSBY_QUERY during build is available on the data prop. The gathering of the data specified by the APOLLO_QUERY at client time is handled by useQuery from @apollo/react-hooks.
const IndexPage = props => {
const allBuildTimeJasons = props.data.JasonAPI.allJasons;
const { loading, data: apolloData } = useQuery(APOLLO_QUERY);
const allClientTimeJasons = apolloData.allJasons;
return (
<div>
<h1>Look at all these Jasons!</h1>
{loading ? (
<JasonList grayOutWaveCount jasons={allBuildTimeJasons} />
) : (
<JasonList jasons={allClientTimeJasons} />
)}
</div>
);
};

RE:JAMstack
I call this the RE:JAMstack, for R eal-time E nhanced JAMstack.
This is a misnomer! Kind of like how every square is a rectangle, but not every rectangle is a square. The pattern doesn’t mean the term JAMstack is no longer applicable.
Also, I wanted to annoy anyone screaming, “But that’s still JAMstack!” and am happy to take any opportunity to name a “new” stack — that seems to be a hot trend.
 Grant@grantglidewell
Grant@grantglidewell Please stop naming stacks. Thank you16:50 PM - 24 Nov 2019
Please stop naming stacks. Thank you16:50 PM - 24 Nov 2019
Plug: LogRocket, a DVR for web apps

LogRocket is a frontend logging tool that lets you replay problems as if they happened in your own browser. Instead of guessing why errors happen, or asking users for screenshots and log dumps, LogRocket lets you replay the session to quickly understand what went wrong. It works perfectly with any app, regardless of framework, and has plugins to log additional context from Redux, Vuex, and @ngrx/store.
In addition to logging Redux actions and state, LogRocket records console logs, JavaScript errors, stacktraces, network requests/responses with headers + bodies, browser metadata, and custom logs. It also instruments the DOM to record the HTML and CSS on the page, recreating pixel-perfect videos of even the most complex single-page apps.
Try it for free.
The post Introducing the RE:JAMstack appeared first on LogRocket Blog.

Top comments (0)