
Despite being all around us, safety-critical software isn't on the average developer's radar. But recent failures of safety-critical software systems have brought one of these companies and their software development practices to the attention of the public. I am, of course, referring to Boeing's two 737 Max crashes, the subsequent grounding of all 737 Max aircraft, and its failed Starliner test flight.
How could such a distinguished company get it so wrong? Weren't the safety standards and certification process for safety-critical systems supposed to prevent this kind of thing from happening? Where was the FAA when the Max was being certified? These questions raised my curiosity to the point that I decided to discover what this specialized field of software development is all about.
In this post I'm going to share what I learned about safety-critical software development and how a little knowledge of it might be useful to "normal" programmers like you and me.
1. What is a safety-critical system?
Safety-critical systems are those systems whose failure could result in loss of life, significant property damage, or damage to the environment.
Aircraft, cars, weapons systems, medical devices, and nuclear power plants are the traditional examples of safety-critical software systems.
But there are other kinds of safety-critical systems:
- code libraries, compilers, simulators, test rigs, requirements traceability tools, and other tools used to manage and build the kinds of systems we traditionally think of as safety-critical systems are safety-critical themselves
- software that provides data used to make decisions in safety-critical systems is likely safety-critical. For example, an app that calculates how much fuel to load onto a commercial jet is safety critical because an incorrect result from that app may lead to a life threatening situation
- other software running on the same system as safety-critical software may also be classified as safety-critical if it might adversely affect the safety functions of the safety-critical system (by blocking I/O, interrupts, or CPU, using up RAM, overwriting memory, etc.)
2. What do safety-critical software projects look like?
Safety-critical software development is a very specialized, expensive, methodical, slow, process-driven field of software development.
Safety-critical software systems are often embedded, distributed systems
Typically, the software monitors its environments with various kinds of sensors and manipulates that environment by controlling actuators such as valves, hydraulics, solenoids, motors, etc. with or without the assistance of human operators.
These systems are usually embedded because they often have timing deadlines that can't be missed. Plus, the creators of these systems are responsible every aspect of the hardware, software, and electronics in the system, whether they created it or not. So the more stuff they put in the system, the more difficult and expensive it is for the company get it certified.
Safety-critical software systems are often distributed systems because:
- they are often large
- subsystems may be developed by different teams or companies
- many of these systems require redundancy and/or the separation of safety-critical code from non-safety critical code
All these factors push the system design towards multiple cooperating processors/subsystems.
There's more safety-critical software than you realize
There's a lot of this software being created. But it doesn't get nearly as much attention as consumer-focused software. For example, just about every story in Military & Aerospace Electronics discusses systems that contain safety-critical software.
It's difficult and expensive to create safety-critical software
It takes lots of resources and money to assemble the cross-functional expertise to develop, certify, sell, and support such complicated and expensive systems. So, while a few small companies might produce small safety-critical software systems, it's more common for these systems to be produced by larger companies.
3. Safety-critical software is almost certainly the most dependable software in the world at any given size and complexity
Software developed and certified as safety-critical is almost certainly the most dependable software in the world. The allowable failure rate for the most critical systems is absurdly low.

And these numbers are for the whole system (hardware and software combined). So the allowable failure rate for software at any given SIL level is even lower!
At SIL 4 (roughly equivalent to NASA's "maximum" category) we are talking about less than one failure per billion hours of continuous operation. That's 114,000 years!!!
To put that in perspective, if your smart phone were built to that standard its unlikely that you or any of your friends and family would have ever experienced a dangerous failure (dead phone, broken camera, random reboot, malware, data leakage, data loss, loss of connectivity, etc.), nor would you expect to encounter one for the entire span of your life! That's an incredibly high bar. And it just shows you how different this kind of product and software development is from the kind you and I do on a daily basis.
Here's my impression of where safety-critical software is supposed to fit in the software quality landscape:
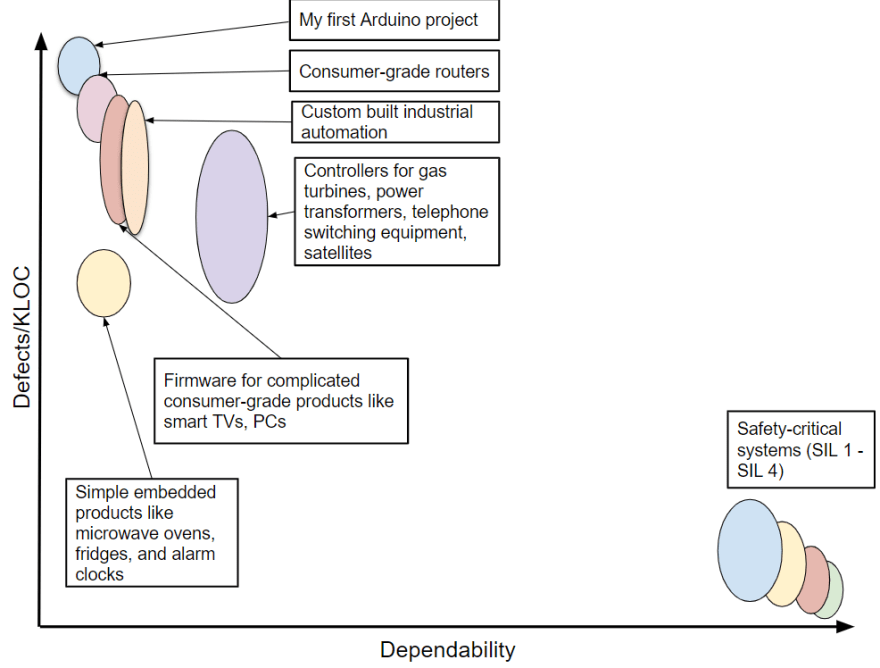
Safety-critical software is designed, built, and tested to ensure it has ultra-low defect rates and ultra-high dependability.
Nothing beats the space shuttle software's quality
The shuttle software is probably NASA's best example of software done right. At the time the article (linked above) was written, the shuttle software was 420 KLOC and had just one error in each of the last three versions. That's orders of magnitude fewer defects than your average software project. Read this article if you want to know what it takes to write the lowest defect software in the world.
4. The focus is on safety, not features or speed
(For the remainder of this post, I'm going to use the NASA Software Safety Guidebook as an example safety standard.)
In most companies, software developers are primarily concerned with getting the software to "work", then going faster, shipping more features, and delivering more value. But software developers involved in the creation of safety-critical systems must be concerned primarily with creating safe systems. And that is a very different task.
They must find all the realistic ways the system could create harm. And then develop ways to mitigate that harm. They also need to make sure the system, as built, functions as specified. They must convince themselves and their auditors that they've done an adequate job of building a safe system before their product can be certified.
We're way beyond unit testing, code reviews, and filling out some forms. We're talking about painstaking checking and re-checking, mandated processes, multiple rounds of analyses, and piles of documentation.
Build it as if you know you are going to be sued
The image that came to my mind as I read through the NASA Software Safety Guidebook is that you have to jump through all these hoops as if you are preparing for a future court case where your product has killed a number of people. And your company and you personally are being sued for tens of millions of dollars. You need to be able to place your hand on a bible and swear that you and everyone working on your project:
- was properly trained
- followed best practices set out in the safety standard you followed
- minimized the risks of harm associated with your product as far as practicable
- earnestly worked to get your product certified as meeting your chosen safety standard by a competent certification body
And then you need to be able to point to a stack of boxes full of your documentation as proof that what you're saying is true, knowing that the plaintiffs' experts and lawyers are going to try to tear you apart.
If you feel like you might not win that hypothetical court case, then your product should not be released.
5. Safety and hazard mitigation requirements will dramatically increase the complexity of your product (and there will be a ton of them)
In addition to software engineering tasks associated with creating software for a normal product, you are going to have a lot of extra requirements related to safety and hazard mitigation. And, as we all know, as requirements interact code volume and complexity skyrocket. For example, we know that doubling the number of requirements will more than double effort required to complete most projects.
Plus, safety and hazard mitigation requirements are often difficult to implement both because they aren't "normal" things software developers do but also because they are inherently difficult. Let's look at an example.
Fail-safe design
Your system must fail safely. That's one of the fundamental principles of safety critical systems design. This means that under any reasonable scenario where the system is being used in accordance with the operating instructions, it must not cause a dangerous situation if something goes wrong.
For many systems that means stopping all actuators and reporting an error. For example, the blade in my food processor will stop immediately if I remove the lid while it is spinning. That's a simple case but for other systems, just figuring out how to fail safely is really difficult.
Heart bypass machine example
What does fail safely mean in the context of a heart bypass machine? The system can't just turn itself off if the power goes out because that will kill the patient.
Battery backup?
So maybe it needs a battery backup to keep it going until the hospital's generator can kick in. And a charging sub-system to keep the battery charged. And a battery health monitoring subsystem to alert the maintainers of the system that the battery won't hold a charge any more. And there should probably be a condition in the code that will not let you start the bypass machine if the battery is defective. Or missing. Or discharged. And some kind of change to the display so the operator can be made aware of status of the machine's power.
By the way, adding a lithium ion battery to a safety-critical system isn't as straightforward as you would think. Even after extensive testing, Boeing's 787 still had battery problems in the field, which required an extensive investigation and changes to the design of the system.
Multiple backups?
Actually, after looking more closely at the requirements, a battery backup alone isn't enough because this system is required to continue to operate with two failures. So maybe we need two independent battery systems? Hmm... do we need to source each system from a different supplier so that a fault in one battery system doesn't bring them both down at the same time?
Or maybe we should install a hand-crank for the nurse to turn a dynamo, which can power the heart bypass machine if the power fails and the battery fails or is exhausted? And we'll need a subsystem to ensure the dynamo works and generates enough power to run the bypass machine. But even a new dynamo won't produce enough power to run all the machine's functions. So maybe we need a low-power mode where the machine runs essential functions only? Or maybe we need to redesign the whole system to use less power? And so on.
So that one safety requirement ("patient must not die if power goes out") ballooned into several explicit requirements and a bunch of questions.
Other failure modes to consider?
And that's just one failure mode. We need to cover all of the realistic failure modes. What about:
- fluctuating power?
- dead power supply?
- damaged RAM?
- memory corruption errors?
- an exception coming out of nowhere?
- sensor failure?
- sensor disagreement?
- hard drive failure?
- a random hard shutdown during a surgery?
- pump failure?
- display failure?
- the case where the operator attempts to input settings appropriate for an elephant instead of a human?
- the case where the operator accidentally turns the machine off?
- a blown capacitor on one of the circuit boards?
- and... and... and...
It's pretty easy to see how the number of safety requirements could easily dwarf the functional requirements in a safety-critical system. And that the implementation of those requirements would drastically increase the complexity of your system for both hardware and software.
6. Some systems are so dangerous that their construction is prohibited
I was surprised to learn that NASA won't let you build anything you want as long as you take appropriate precautions and get it certified (pages 27 - 28).
NASA prohibits the construction of the following kinds of systems no matter how many software precautions you are willing to take:
- systems with catastrophic hazards whose occurrence is likely or probable
- systems with critical hazards whose occurrence is likely
Where:
- catastrophic is defined as: loss of human life or permanent disability; loss of entire system; loss of ground facility; severe environmental damage
- critical is defined as: severe injury or temporary disability; major system or environmental damage
- likely is defined as: the event will occur frequently, such as greater than 1 out of 10 times
- probable is defined as: the event will occur several times in the life of an item
A prohibited system example
A spacecraft propulsion system that will blow up the spacecraft unless a computer continuously makes adjustments to keep the system stable would almost certainly be rejected by NASA as too dangerous.

Even if the system designers believe the software reduces the risk of killing the crew down to 1 incident per 5,000 flight years, the system would likely be classified as "prohibited" because NASA knows that software is never perfect.
7. Safety-critical software is about as far from agile as you can get
While there's some talk of using agile methods for safety-critical software development to improve speed and drive down costs, I don't think it's very realistic to think that agile will get very far in safety-critical circles. The Agile Manifesto defines 4 development values and 12 development principles and most of them are in direct opposition to the requirements of safety-critical software development.
"Welcome changing requirements, even late in development" seems to be a particularly problematic agile principle in the context of safety-critical software development. A single changed requirement could trigger a complete re-analysis of your entire project. If the change introduces a new hazard, it will have to investigated, analyzed, and possibly mitigated. The mitigation may result in multiple design changes. Design changes (hardware and/or software) may result in changes to the documents, safety manual, user manual, operator training requirements, test cases, test environments, simulators, test equipment, and code. Code changes require targeted retesting around the change. Plus, all your safety-related tests are supposed to be re-run for every code change. And, finally, you'll have to get your product recertified.
And that's the easy case. Imagine what would happen if your requirements change pushes your software to a higher safety level (say "minimum" to "moderate" for a NASA project or SIL 2 to SIL 3 for a IEC 61508 project)? Now you have to re-execute your project using the prescribed processes appropriate to your new safety level!
Waterfall or spiral development models dominate the industry
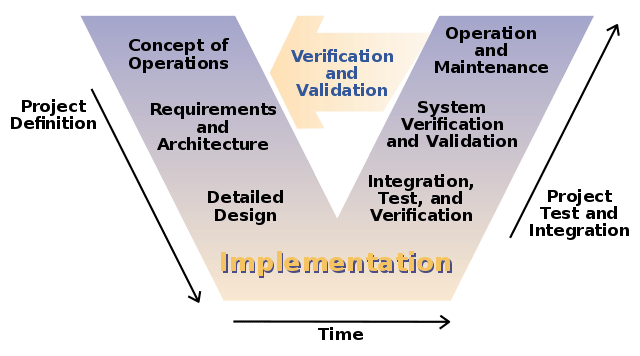
Most safety-critical software appears to be developed using the waterfall or spiral development models. NASA specifically recommends against using agile methods for the safety-critical elements of your software (page 87).
I've seen lots of examples where the V-model is mentioned as a specialized version of waterfall appropriate for safety-critical software development. In the V-model, the steps on the same horizontal level are loosely related. So, for example, you should be thinking about unit and integration tests when you are doing detailed design. Some sources even recommend writing the unit and integration tests during detailed design (before coding begins).
8. "Normal" software is sometimes used for safety-critical purposes
There's considerable controversy about what should be considered safety-critical. If a doctor uses a calculator app on her smartphone to calculate an IV drug dose for a patient on a very dangerous drug is the app safety-critical? What about the math library used by the calculator? What about the phone's OS and the all the other software on the phone? The answer is unclear.
Should doctors be forced to use certified calculators to determine IV drug dosages? Are calculators certified for safety-critical applications even available? I know this sounds like nitpicking; it's obvious that calculators work correctly, right? Actually, no. Harold Thimbleby has made the study of medical mistakes involving technology his life's work. And I found this video of him demonstrating numerous errors in the functioning of regular calculators deeply unsettling. It's not just one or two calculators that have errors. He calls them all "crap."
But it's not just calculators that we have to worry about. How many spreadsheets out there contain safety-critical data and calculations?
Looking in from the outside, authorities don't seem too concerned about the use of normal software for safety-critical functions. However, as a "regular" developer you might want to be aware that your software could potentially be used this way. Unless you are encouraging this use of your software, you are probably in the clear from a legal liability point of view but the ethics of it might be another story.
9. Insecure software cannot be considered safe
Many people criticize the safety standards for doing a poor job of addressing security (see the criticisms section below). So it shouldn't surprise you to learn that security researchers have found glaring security vulnerabilities in many classes of safety-critical products.
Because your entire safety case relies on your software behaving exactly as specified, you have a major problem if someone can make your system misbehave.
10. There are no silver bullets
I was hoping that my investigation into safety-critical software development would introduce me to some secrets of fast, high quality software development beyond what I've already discovered. I was looking for some tools or techniques to give me an edge in my day job. But I found nothing useful.
Safety-critical software development succeeds, for the most part, by throwing large quantities of money and people at the problem of quality. I think there's definitely an element of "do it right the first time" that's applicable to all software development efforts where high quality is desirable but there's nothing magical happening here. For the most part it's process, process, and more process.
The closest thing I found to "magic" is automatic code generation from simulation models and correctness by construction techniques. But neither of these approaches are going to benefit the average developer working on a non-safety-critical project.
11. How developing safety-critical software systems is supposed to work
There are a bunch of safety standards out there. If you are developing your own system, the standard you use may be dictated by your industry. Or, under certain circumstances, you can choose the standard you intend to meet. Then you assemble a competent team, build your product, and attempt to get your product certified by a certification body or you might chose to self-declare that your product meets the standard, if that's an option in your industry.
If you're building a product for someone else they may dictate the standard you must meet as part of your contract. If your customer is NASA then you are expected to follow the NASA Software Safety Guidebook for software development (and possibly some others, depending on the nature of your system).
Determining your safety level
The rules are very complicated but the basic idea is that you have to evaluate how dangerous your product is, the probability that the danger might occur, and the extent to which your software is expected to mitigate that danger (as opposed to hardware controls or human intervention).
Software that ensures a consumer pressure cooker doesn't over-pressure and explode would be certified to a lower level than the software that autonomously controls the safety functions of a nuclear power plant. So you'd have to follow a more rigorous process and do more work to certify the software for the nuclear power plant.
NASA has 4 levels of certification for safety-critical software: "full", "moderate", "minimum", and "none" (page 28). The NASA Software Safety Guidebook will help you figure out which level your proposed system is at.
It's also possible to have a mixed level system. For example one sub-system might be at the "full" level but another sub-system might be at the "minimum" level.
Adopting the required processes, analyses, and documentation
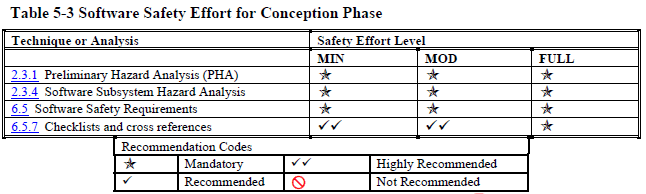
Once you know what level(s) your product is at, you can look up which processes, analyses, and documentation, you need to follow, perform, and create to achieve that level. Each development phase has a table that tells you what you need to do (other standards have similar tables).
(I think these tables are interesting enough that I included the tables for each phase of the development from the NASA Software Safety Guidebook below. But you don't have to read them to understand the remainder of this post.)
Conception (the stage before requirements where you are defining what kind of system you need) (page 102):
Requirements (page 107):
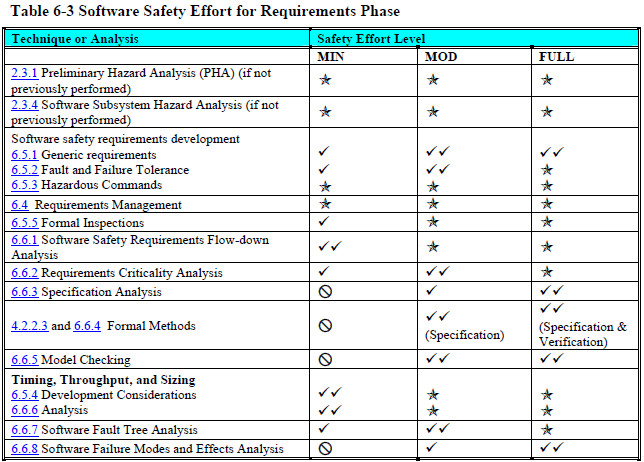
Design (page 136):
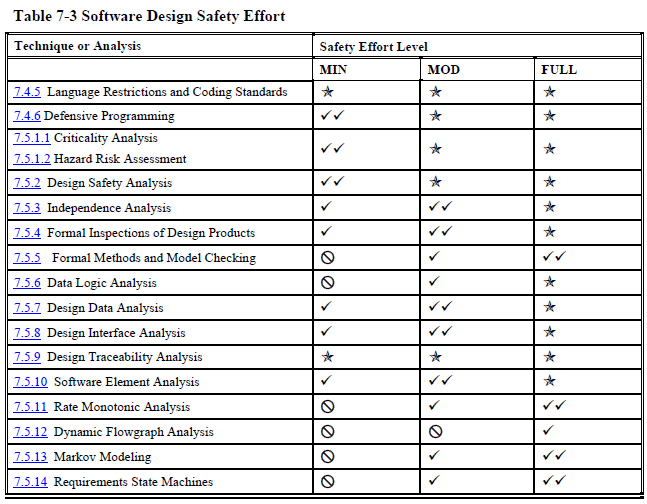
Implementation (coding) (page 167):
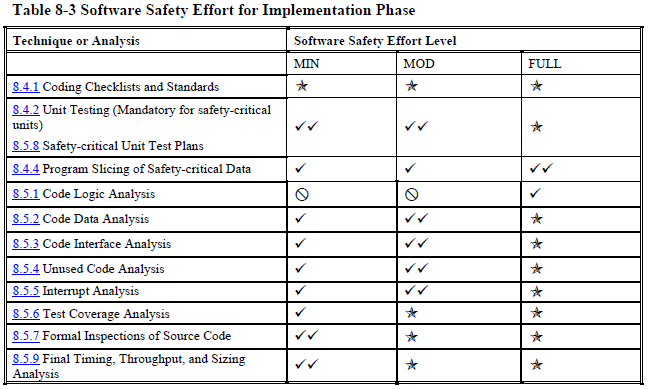
Testing overview (page 181):
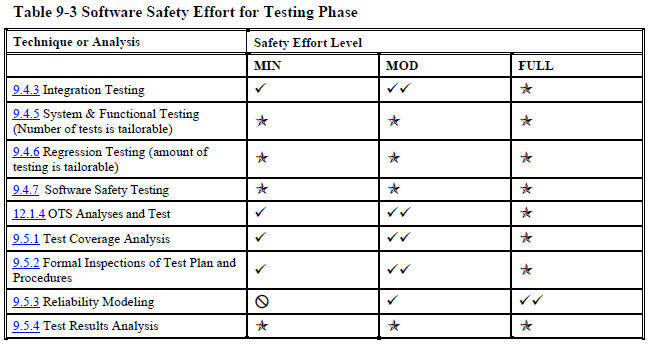
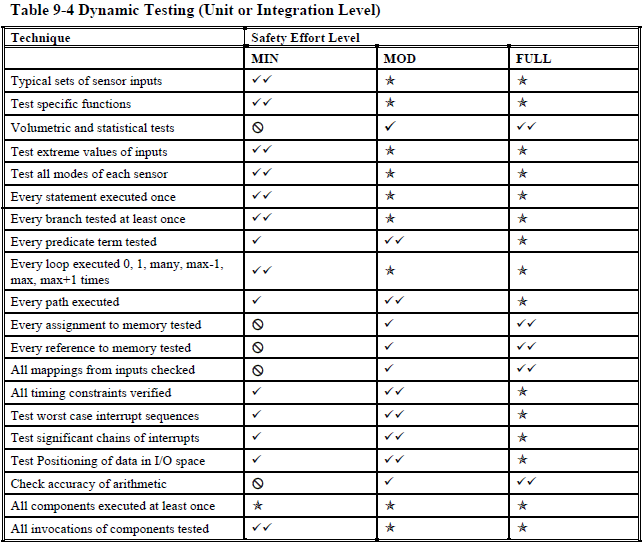
Unit or integration testing (pages 181 - 182):
System testing (page 182):
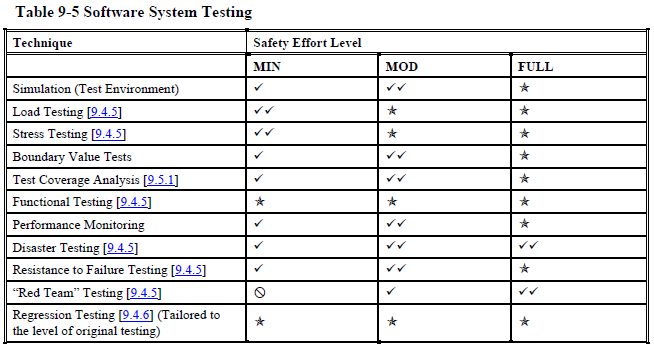
Operations and maintenance (page 199):

As you can see, even at the "minimal" safety level NASA wants you to do many, many things that most software projects never do.
You are expected to go to extreme lengths to ensure your software is safe
Let's take a closer look at the dynamic testing table to illustrate my point. Even if you already routinely unit test your code for non-safety critical projects, I bet you aren't that thorough. Maybe you skip things that are particularly difficult to test and either not test them at all or "sort of" test them manually? Well, that's not good enough for safety-critical software. And getting to "good enough" might take more time than all the easy testing combined.
NASA wants to see the following tested for the "minimal" safety level:
- typical sensor values
- extreme values of inputs
- all modes of each sensor
- every statement, branch, and path executed
- every predicate term tested
- every loop executed 0, 1, many, max -1, max, and max + 1 times
It doesn't take much imagination on your part to realize a few things are going to happen if you attempt to follow these testing requirements to the letter:
- you need to write all production code for testability, which will negatively impact other properties of your code
- the volume of your test code is going to be larger than the volume of your production code (probably by a wide margin)
- it's going to be difficult for you to write your test cases in such a way that you can track each of them back to the dynamic testing category it covers as well as the specific requirement it satisfies
- it's going to be even more difficult for you to know that you've created enough test cases to satisfy the dynamic testing requirements for every subroutine in your code base
- because you are testing so deeply in your system (not just the public API like most unit testers recommend for non-safety-critical systems), you are going to find it nearly impossible to refactor your code without causing chaos in your test suite
- if QA discovers a problem with your product, it's going to be a nightmare to modify your code and test cases without making any mistakes
Getting your product certified
There are two ways to go here.
Self declare you meet a standard
In some industries you can simply declare that your product meets all the requirements of some standard, possibly with the assistance of an independent company to confirm the declaration.
While this might seem like an easier route to certification, your customers might not accept it. Plus, I'm not actually clear on when or under what circumstances you can self-declare that your product meets a certain standard. NASA doesn't allow it. And, based on what I've read, it seems unlikely that the FAA and the FDA allow it either. But other industries might be different? Please leave comment on this post if you know how self-declaration works.
Have your product certified by a certification body
The other way to go is to hire a certification body to independently evaluate your product and issue a certification if your product meets the standard you seek. This is the more rigorous of the two routes.
If you are going to work with an external company to help certify your product, they should be brought into the development process as early in your project life cycle as possible. It is not uncommon for an entire product to be developed and then fail to receive certification because of a mistake made very early in the development process. Adding missing requirements, processes, or documentation to a product after it has been constructed can be virtually impossible.
Certification is not guaranteed. Only 25% of companies seeking certification received it in this paper. I'm sure the rigor of certification varies from industry to industry and SIL to SIL but, as far as I can tell, it's a serious process everywhere.
Independent Verification and Validation
If you are working on a NASA project that is particularly high risk or high value, NASA may assign an Independent Verification and Validation (IV&V) team to your project (page 102). This team is tasked with ensuring that your project is on track to deliver the quality and functionality required for a safe and successful system/mission. The work the IV&V team does is over and above all the work you are expected to do for the project, not a replacement for it. The IV&V team can also act as a resource to answer your questions and help you tailor your effort appropriately to the risks of your project.
Tracking your product in operation
You are responsible to tracking usage and defects in your product as it operates in the field. The scope of this activity varies depending on the kind of product you are creating but the goal is to gather data to show how dependable your system is in actual use.
For example, Rolls-Royce jet engines use satellite communications to "phone home" with engine telemetry. Rolls-Royce collects data on the number of hours of use, along all kinds of performance, fault, and failure data for their engines. You probably can't get better tracking than that.
On other other end of the spectrum, something like an airbag in a car might rely on estimates of deploy events and consumer reports of malfunctions. This is much lower quality tracking data than Rolls-Royce collects but it's still better than nothing.
13. How developing safety-critical software systems actually works
I've described how safety-critical software systems are supposed to be built. But the reality of the situation appears to be quite different. It didn't take me long to realize that some companies approach safety-critical software development with little regard for the standards or the seriousness of what could happen if their systems fail.
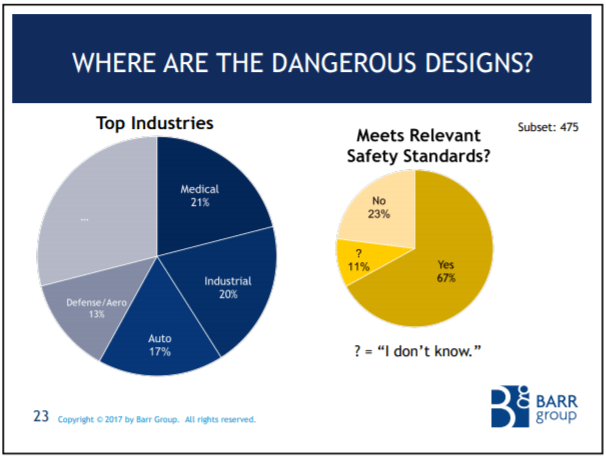
The Barr Group's 2017 Embedded Safety & Security Survey
The Barr Group surveyed embedded developers around the world and found a shocking lack of best practices on safety-critical projects.
28% of all respondents work on safety-critical projects.
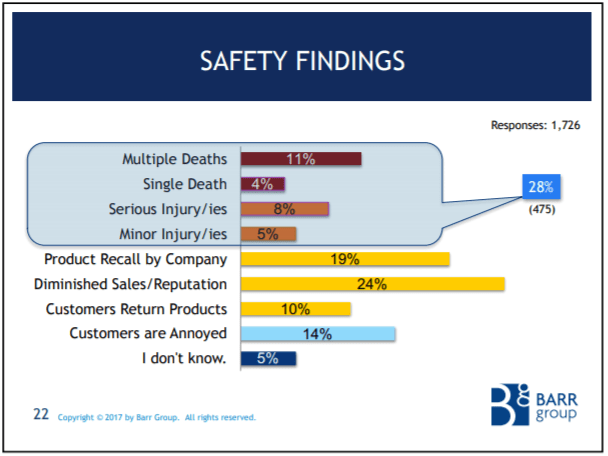
Only 67% of the safety-critical subset meet a safety standard!
Coding standards, code reviews, and static analysis are all mandatory at my e-commerce job because they are cost-effective, proven ways to improve quality. But a significant portion of the safety-critical subset don't do them.
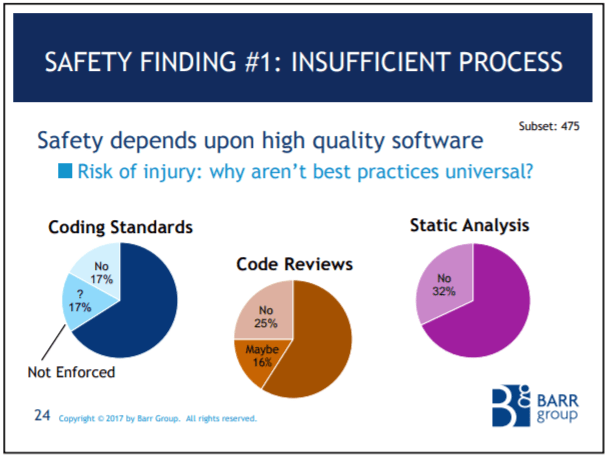
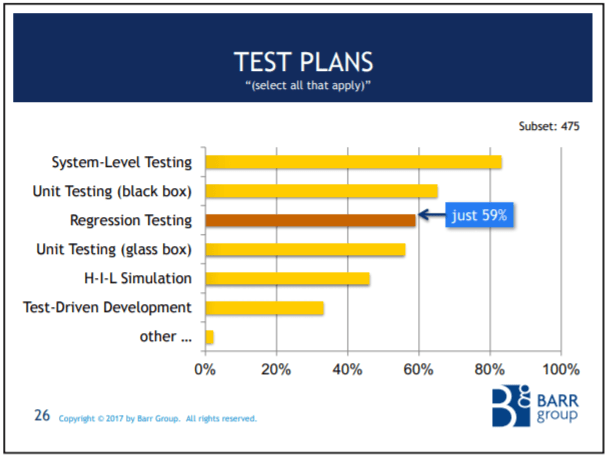
And it just gets worse. Only 59% of the safety-critical subset do regression testing! Less than 100% do system level testing!
These numbers are hurting my brain!
And there's much more to be concerned about in this survey. I encourage you to watch the CEO of the Barr Group go over the survey findings in this YouTube talk.
Anyway, if you look at these results and compare them to all those tables I reproduced from the NASA Software Safety Guidebook, its pretty easy to imagine how many of the other tasks are not being done on safety-critical projects in the real world.
Toyota Unintended Acceleration Investigations
If you haven't heard Toyota's unintended acceleration problems I suggest you read a brief summary on wikipedia to get yourself up to speed. This is definitely a safety-critical software system and it is a mess.
Let's set the hardware and safety culture problems aside for a moment and just look at some of the software findings for the Electronic Throttle Control System. It's the system responsible for reading the pedal position and controlling the engine throttle settings:
- over 250 KLOC of C (not including comments)
- 2,272 global variables
- 64 instances of multiple declaration of the same global
- 333 casts alter value
- 22 uninitialized variables
- 67 functions with complexity over 50
- one function was found to have a complexity of 146. It contained 1,300 lines of code and had no unit tests
- bugs that can cause unintended acceleration
- gaps and defects in the throttle failsafes
- blackbox found to record incorrect information
- stack overflow and defects that can lead to memory corruption
- and more...
Anyone who has made it this far in this post knows this is not the kind of code you want to see in a safety-critical system.
For more details please watch Philip Koopman point out multiple problems with Toyota's hardware, software, and safety culture (slides). It's an eye-opening talk.
Patients hacking their insulin pumps and posting the plans online
I ran across a video several years ago where a non-programmer was describing how he glued together a bunch of tech to allow his continuous glucose monitoring device to send commands to his insulin pump to automatically adjust the amount of insulin it delivered to his body to control his diabetes.
As a professional software developer, who is very aware how difficult it is to write correct software, I was very alarmed by what this guy was doing. He knew basically nothing about programming. He was building this system from tutorials and trading information with other non-programmers who were also working on the project in their spare time. I believe it was literally the first thing he ever programmed and it is definitely safety-critical--too little or too much insulin can definitely kill you.
Now, if you want to take your life into your own hands and build something like this for your personal use, I say go for it. But these people were sharing the design and code on a website and making it available for anyone to use, which is not cool in my opinion. The FDA issued a public warning not to build your own "do-it-yourself" pancreas after watching from the sidelines for several years.
Anyway, this is another example of how the theory is radically different than the reality of safety-critical software development.
The Boeing 737 Max and Starliner software issues
Two Boeing 737 Max crashes and a failed Starliner test flight are what inspired me to write this post. But as I dug deeper and deeper into safety-critical software development and safety-critical software development at Boeing in particular I've realized that this topic deserves its own post. I'll link to that post here when I publish it.
14. The safety standards are widely criticized
The standards are designed and approved by committees. They are based on what the drafters could get approved, instead of what is most appropriate or what is backed by evidence. While there appears to be broad agreement that coding standards, design reviews, code reviews, unit testing, and the like are good things, the standards disagree on specific practices and approaches.
Industry doesn't want to be told what to do
One criticism I read suggested that industry wants to minimize the work prescribed by the standards so it lobbies against adding more prescriptions to them. In some cases it is because they want to minimize their work to get their products certified. In other cases, it is so they can pursue the most effective techniques as they become available instead of being forced to do something they know is ineffective compared to the state of the art, just because the standard says they have to do it.
There's little evidence that following the standards produces safe software
There is actually little evidence that following the prescribed activities will result in the expected quality/failure rates experienced in the field. I think page 12 of the NASA Software Safety Guidebook describes the situation very well:
Opinions differ widely concerning the validity of some of the various techniques, and this guidebook attempts to present these opinions without prejudging their validity. In most cases, there are few or no metrics as of yet, to quantitatively evaluate or compare the techniques.
Security is ignored
Other people criticize the standards because they are mostly silent on security. I think that's a valid concern. If your product isn't secure, it's hard to argue that it's safe.
Here's another slide from the Barr Group's 2017 Embedded Safety & Security Survey. It shows that only 78% of the respondents who are working on safety-critical projects that are connected to the internet even have security as a requirement. It's not even on the radar of 22% of projects! Now, how many of the 78% of respondents who do have security requirements do you suppose are doing security well?
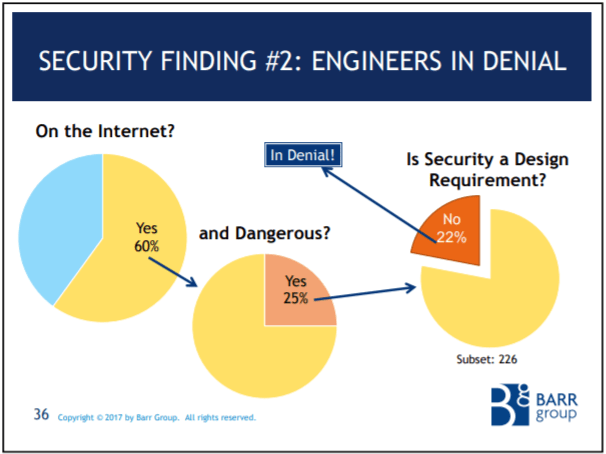
Here's the compliance with coding standards, code reviews, and static analysis for the safety-critical and connected to the internet subset. The ratios are about the same as the safety-critical only subset I showed you previously in this post. If you're not following a coding standard, doing code reviews, or using static analysis, I have a hard time believing you're somehow writing ultra-secure code for your internet connect, safety-critical product.

The standards don't address component interaction failures among others
Nancy Leveson shows many examples where following the standards isn't enough. Just as we acknowledge that all software contains defects and plan accordingly, we should also acknowledge the possibility that our software may also contain/experience:
- component interaction failures
- requirements errors
- unanticipated human behavior
- system design errors
- non-linear or indirect interactions between components or systems
- etc.
Leveson argues that we need to build safety-critical systems that can cope with these factors. She proposes STAMP as an additional approach to improve system safety for these types of issues. She has a great talk on YouTube that covers the basics.
By the way, she's not an odd-ball spouting BS from the sidelines. She's the Professor of Aeronautics and Astronautics at MIT and she works with the DOD, NASA, and others on safety-critical systems.
15. Thoughts on the future of safety-critical software development
Here are some of my ideas for where safety-critical software development is going and some of the challenges we'll face in getting there.
I anticipate sky-rocketing demand for this kind of software in the following areas:
- autonomous cars and driver assist features
- internet of things (including the industrial internet of things)
- robotics and industrial automation
- military systems
- medical devices and healthcare related applications
- space-based applications
Challenges:
- demand for larger, more complex systems surpasses our ability to build them to the quality standards this kind of software requires
- we need a way to drastically reduce the cost and time required to produce this kind of software
- how can we incorporate AI and machine learning into safety-critical systems?
- how do we allow safety-critical systems to communicate with each other and with non-safety-critical systems without degrading safety?
- security is going to continue to be a thorn in our sides
- more and more software is going to be used for safety-critical purposes without having been designed and built to safety-critical standards (like the doctor calculating IV drug doses on her smartphone)
- how do we attract sufficient numbers of talented software developers to work on safety-critical projects?
Resources
- NASA Software Safety Guidebook (pdf)
- Great Introduction to safety-critical systems (pdf)
- Martyn Thomas talk on safety-critical systems and criticisms of the standards (video)
- Martyn Thomas talk on correctness by construction techniques (video)
Wrapping up
What do I want you to take away from this?
The quantity and complexity of safety-critical software is growing rapidly
Safety-critical software is all around us and we can only expect more of it as we connect more of the world to the Internet, make "dumb" devices "smart", and invent entirely new products to make our lives better.
Developing this kind of software is hard
Developers of safety-critical software systems feel the pain of the lack of maturity of the software engineering field more than most of software developers. Much to my disappointment, they don't appear to be hoarding any magic tools or tricks to get around the problems we all face in trying to develop complex products. Aside from doing more up-front planning than the average project, they just throw money and process at their problems just like the rest of us.
Some safety-critical software is developed with a shocking disregard for best practices
There's a wide gap between how safety-critical software systems are supposed to be developed and certified and what actually happens. I was shocked to learn that many safety-critical projects don't use coding standards, static analysis, code reviews, automated testing, or follow any safety standard at all!
If you find yourself working on such a project, maybe take some time to consider the potential consequences of what you're doing. There are plenty of jobs for talented developers where you aren't asked to endanger people's lives.
Most safety-critical software is relatively safe
Despite the many challenges of safety-critical software development, most safety-critical software systems appear to be, more or less, safe enough for their intended purpose. That doesn't mean that it doesn't contain errors, or even that it doesn't kill people (because it almost certainly does). What I mean is that most safety-critical software is trustworthy enough to be used for its intended purpose as evidenced by the public's willingness to fly on planes, live near nuclear power plants, and have medical devices implanted in their bodies.
Until Boeing's recent problems with the 737 Max, the go-to example of a safety-critical software error resulting in death was malfunction of the Therac-25 radiation therapy machines. An investigation revealed that the machines were pretty much a disaster from top to bottom. And between 1985 and 1987 a handful of people received harmful doses of radiation from Therac-25 machines and a couple of people died.
That the Therac-25 was the go-to example of a failure of safety-critical software causing death says something about just how well most of these systems perform in the real world. After all, safety-critical software is controlling nuclear power plants, medical devices, rail switching, elevators, aircraft, traffic lights, spacecraft, weapons systems, safety features in cars, and so on. But when is the last time you heard about a software error causing a safety-critical system to fail and kill people (besides the Boeing 737 Max and Tesla autopilot fatalities)?
Have a comment, question or a story to share? Let me have it in the comments.
Enjoy this post? Please "like" it below.

Top comments (24)
Trevor Kletz devotes chapter 20 of What Went Wrong? Case Histories of Process Plant Disasters to "problems with computer control". It has some good general points:
Good points. Thanks for sharing.
The belief that all software errors are systemic appears to be outdated.
I read Embedded Software Development for Safety-Critical Systems by Chris Hobbs as part of my research for this post. And he writes extensively about heisenbugs, which are bugs caused by subtle timing errors, memory corruption, etc. In fact, he shared a simple 15 line C program in his book that crashes once or twice every few million times it's run.
In the multicore, out-of-order executing, distributed computing era, systems aren't nearly as deterministic as they used to be.
They're exactly as deterministic as they used to be! What Went Wrong's first edition dates to 1998 -- at that point hardware and software engineers had been dealing with race conditions, scheduling issues, and the like for decades, although Kletz doesn't get into the gory details as he's writing for process engineers rather than software developers. Computer systems have not become non-deterministic (barring maybe the quantum stuff, which I know nothing about); rather, they've become so complex that working out the conditions or classes of conditions under which an error occurs tests the limits of human analytical capacity. From our perspective, this can look a lot like nondeterministic behavior, but that's on us, not the systems.
Isn't what you are saying effectively amount to non-determinism? If your safety-critical product crashes dangerously once every million hours of operation on average for reasons you can't explain or reproduce, no matter how hard you try, isn't it hard to say that it's a systemic error for all practical purposes?
This really isn't my area of expertise by the way. Chris Hobbs explains what he means in this YouTube talk.
This is a great article!
I do have a few comments.
Not only is it not on the average developer's radar, but it's almost certainly not on the average consumer's radar either. And as software systems get more information about our personal lives - what we look like, who we talk to, where we go - the systems become more safety-critical for more people. Maybe we aren't talking about the system itself causing bodily harm, but the system containing data that, in the wrong hands, could cause harm to the individual. We don't all need NASA levels of development processes and procedures to build systems that have runtimes of tens of thousands of years without errors, but many can learn from some techniques that go into building these critical systems.
This is probably the only thing that I don't agree with at all.
Agile in safety-critical systems isn't about improving speed. In fact, nothing about Agile Software Development is about improving speed - the "speed improvement" is mostly perceived due to more frequently deliver and demonstration of software. The advantage of agility is about responding to uncertainty and changes.
The ability to respond to changing requirements is important, even in critical systems. I can't tell you the number of times that the software requirements changed because the hardware was designed and built in a manner that didn't fully support the system requirements. It was more cost effective to fix the hardware problems in software and go through the software release process than it was to redesign, manufacture, and correct the hardware in fielded systems. In some cases, the hardware was fixed for future builds of the system, but the software fix was necessary for systems already deployed in the field.
The basic values and principles still apply to safety-critical systems and I highly recommend considering many of the techniques commonly associated with Agile Software Development as I've personally seen it improve the quality of software components going into integration and validation.
Hi Thomas, thanks for taking the time to leave a comment.
I totally agree with your first comment.
I have some thoughts about your second comment though. It's probably more correct to say that teams adopt agile to better respond to uncertainty and change than to go faster and reduce costs. Thanks for pointing that out.
I want to preface my next comments by stating that I've never worked on a safety-critical project. I'm just writing about what I learned from reading and watching talks about it.
Let's look at the agile principles and how they might present themselves in a large safety-critical system:
So, after going through that exercise I think I agree that the agile principles can add value to a safety-critical development effort. But I think several of them are in direct conflict with the processes imposed by the standards and the nature of these projects. We are therefore unlikely to see them as significant drivers of behavior in these kinds of projects.
If you were asked to look at a safety-critical project, examine its documents and plans, and even watch people work, and then rate the project from one to ten where one was for a waterfall project and ten was for an agile project, my impression is that most people would rate safety-critical projects closer to one than ten. Would you agree with that?
It depends on how you define "customer". Consider a value stream map in a critical system. The immediate downstream "customer" of the software development process isn't the end user. You won't be able to continuously deliver to the end user or end customer - the process of going through an assessment or validation process is simply too costly. In a hardware/software system, it's likely to be a systems integration team. It could also be an independent software quality assurance team.
Continuous integration is almost certainly achievable in critical systems. Continuous delivery (when defined as delivery to the right people) is also achievable. Depending on the type of system, continuous deployment to a test environment (perhaps even a customer-facing test environment) is possible, but not it's not going to be to a production environment like you can with some environment.
If you were to change a requirement after certification or validation, yeah, it's a mess. You would need to go through the certification or validation process again. That's going to be product and industry specific, but it likely takes time and costs a bunch of money.
However, changing requirements before certification or validation is a different beast. It's much easier. However, if it could have impacts in how the certification or validation is done. It also matters a lot if it's a new or modified system requirement or a new or modified software requirement (in cases of hardware/software systems).
This is one of the harder ones, but in my experience, most of the "changing requirements" in critical systems comes in one of two forms. First is changing the software requirements to account for hardware problems to ensure the system meets its system requirements. Second is reuse of the system in a new context that may require software to be changed.
Again, you can think outside the box on what it means to "deliver working software". The development team frequently delivers software not to end users or end customers but integration and test teams. They can be set up to receive a new iteration of the software in weeks or months and be able to create and dry run system level verification and validation tests and get feedback to development teams on the appropriate cadence.
I don't think there's a difference here. Hardware/software systems also need this collaboration between software developers and the hardware engineering teams. There may also be independent test teams and such to collaborate with. But the ideal of collaboration is still vital. Throwing work over the wall is antithetical to not only agile values and principles, but lean values and principles.
Yes, you need more documentation around the product and the processes used to build it. But highly motivated individuals go a long way to supporting continuous improvement and building a high quality product.
I'm not familiar with any instance with anywhere close to 500 developers. Maybe on an entire large scale system, but you typically build to agreed upon interfaces. Each piece may have a team or a few teams working on it. This is hard to do on large programs, but when you look at the individual products that make up that large program, it's definitely achievable.
This goes back to defining who you deliver to. Getting working software to integration and test teams so they can integrate it with hardware and check it out helps them prepare for the real system testing much earlier. They can make sure all the tests are in place and dry run. Any test harnesses or tools can be built iteratively just like the software. Since testing usually takes a hit in project scheduling and budgeting anyway, this helps identify risk early.
I've also read about death marches in non-safety-critical software development. Other techniques such as frequent delivery and involvement of the downstream parties helps to identify and mitigate risk early.
The idea of a bunch of people sitting in a room coming up with a design and then throwing it over the wall exists, but it's not as common as you'd think. When I worked in aerospace, it started with the system engineers and working with senior engineers from various disciplines to figure out the building blocks. When it came to software, the development team that wrote the code also did the detailed design. The senior engineer who was involved at the system level was usually on the team that did the detailed design and coding as well.
This is very closely related to the lean principles of reducing waste. It's true that there is little discretion over the requirements that need to be implemented before the system can be used, but there can still be ways to ensure that all the requirements do trace back to a need. There's also room to lean out the process and make sure that the documentation being produced is required to support downstream activities. Going electronic for things like bidirectional traceability between requirements and code and test and test results and using tools that allow reports and artifacts to be generated and "fall out of doing the work" also go a long way to agility in a regulated context.
This depends greatly on the organization and the criticality of the system being developed. It's important to realize that the regulations and guidelines around building critical systems almost always tell you what you must do, not how to do it. With the right support, a team can develop methods that facilitate agility that meet any rules they must follow.
Retros for a safety critical project aren't that different than anything else. The biggest difference is that the team is more constrained in what they are allowed to do with their process by regulatory compliance and perhaps their organization's quality management system.
I believe that you could get up to a 7 or 8. I think that agility is still gaining traction in the safety-critical community, and it's probably at a 1 or 2 now. It's extremely difficult to coach a development team operating in a safety critical or regulated space without a background in that space. But after having done it, it's possible to see several benefits from agility.
Awesome feedback! Thanks for sharing your knowledge and experience.
Hi Blaine, another excellent article!
Steve McConnell's book, Code Complete “Industry Average: about 15 – 50 errors per 1000 lines of delivered code.” And I think Steve was being optimistic.
Easy enough to do a
find . -iname "*.cpp" -print0 | xargs -0 wc -land divide by 50 to get a sense of how many defects are in the codebase. Using the high-end of Steve's range, which I think the low end is already optimistic.And this is why I never use the self-driving feature of my car. No way. I don't want to be the next Walter Huang.
Thanks.
I wrote a post where I criticized into Tesla's autopilot. In the area of driver assist features, I much prefer Toyota's Guardian approach of actually finding ways to help drivers drive more safety instead of asking them to give control to a giving half-baked AI.
Would you use something like Guardian if your car had it? Or do you distrust all safety-critical systems that rely on AI/ML?
I am okay with driver assist technologies. I'm not okay with fully autonomous self-driving cars. Some day, I imagine self-driving cars will be the mainstay. But in the meantime, it'll be a slog up that technology hill.
Thanks for the updated link. Interesting article. I don't think the details of the technique are exactly applicable to safety-critical systems. But I have read about how complicated safety-critical systems with redundancies and fail-overs test how their systems respond to failures, disagreement in voting architectures, power brownouts, missed deadlines, etc. I suppose it would all fall under the banner of chaos engineering.
I doubt very much it was plain luck that you were asked to participate. I'm sure your engineering skills had something to do with your invitation.
Cheers.
First of all I think it is good that you use NASA as a way to talk about safety critical system standard. I think the common industry application is actually based upon certain variation of IEC 61508 due to it being general in nature but there is certain safety standards for different industry.
Second in terms of SIL level the introduction of AI is considered a breach of it. Therefore the use of AI is labeled to be "experimental" aka you do it your own risk that you might die or injured you. My professor always joked on it that as a safety critical guy. He would never a ride in a self driving car because you can never quantify or justify that it will work as intended due to nature of software is unpredictable. What you can do is to based on the probability of failure in the hardware which there is a expected graph of how a it will lead to failure overtime.
3rdly the whole purpose of safety critical system is to prevent the lost of life or detrimental physically harm to a human or equivalent to it. This is justified by the cost of a human life is about 1 million USD. Which is why the higher a SIL compliance the more expensive it become to build that piece of software to comply with the standard. Which is why you only do it because you want to enter or sell it to certain market or country that adopts that safety critical standard.
Depending on depending on the nature of industry, a higher failure rate is allowed like for medical devices.
All good points.
I used NASA's standard because anyone can look at it for free, which is not the case for IEC 61508 or ISO 26262.
I have no idea how these ML/AI systems are being installed, certified, and sold in cars as safe. My best friend was nearly killed twice in one day by one of these systems. In the first case his car veered into oncoming traffic. And in the second case the adaptive cruise control would have driven him right into the car in front of him had he not intervened and turned it off.
He pulled over and found snow had collected in front of the sensors. The car didn't warn him about questionable sensor reading, or refuse to engage those features. It just executed its algorithm assuming the sensors were correct. Not very safe behavior in my opinion.
Good point about the cost of saving one life. I've read it's different from industry to industry and from country to country. I believe nuclear and avionics in the US put the highest value on a life in the data I saw.
Ahhh... now I understand the why you choose it. Since a module of mine is based on that particular standard in my university. Plus it's really a niche subject that my professor shared to the class. He has to go to China or Singapore from time to time to teach due to the lack of it. Despite its really important especially you are implementing in the area you had mentioned.
As much as I want to have a self driving car to fetch me to move from point A to point B. Till now I'm in the same thinking as my professor of having to drive it myself or grab a taxi.
Thanks, Phil.
It's perfectly acceptable to go over and above the standards and do as much fuzz/dynamic/exploratory testing as you like. I don't think you would have much luck convincing regulators that it's a good substitute for MC/DC unit test coverage. But you could capture all the inputs that cause faults, fix the errors, and then add them to your official regression test suite.
Your SlideShare link appears to be broken. I'm curious to read what was there.
I've bookmarked your satellite project post and I'll read it when I get a minute. Writing code that either flies or runs in space is on my bucket list. I'm envious.
Hi Blaine, thanks for this really great post! Sadly you're right: there are no magic tricks to quickly develop safe software. I develop safety-critical software in the automotive area (ISO26262) and it's also extremely much process, analysis, testing and documentation. Coding is only a few percent of the work.
Care to share a couple more details about your job?
What specifically are you working on? What SIL level? Team size? What do you like best/worst about your job?
I am surprised you didn't mention Ada in your article. Ada is great for safety-critical software, especially since programs written in a subset of it can be mathematically verified to be bug-free.
Oh man, I'm a huge fan of Ada and SPARK. I just wrote and open sourced a sumobot written in SPARK.
My post just kept growing and growing in length so I decided to make some hard edit choices to prevent it from becoming a short book. But safer languages are definitely an option.
I enjoyed your well written article. I plan on taking the time to look up some of the references you mentioned. I have always got a kick out of the disclaimer on the retail box of Windoz long ago.
I'm glad you enjoyed it.
I don't understand your reference. What does the disclaimer say?