
If you are an experienced developer, you may well know about makefiles. Plain text files defining rules to compile software, back from the old days. Right?
Today we will:
See the Top 3 myths I’ve encountered on my experience and prove them wrong
We will see how make shines when used as expected.
Myth #1
Only useful for C, C++ and native software
Although it’s true that the C/C++ ecosystem was heavily influenced by the presence of make within the ecosystem, there’s much more that you can do with it. make can handle any kind of file, as long as it has a path and a timestamp.
The typical example:
Creates a dependency tree of the commands that need to be run on each execution
If you run
make edit, thenmain.o,kbd.oandcommand.oare compiled first, and theneditis built upon them
However, you could also use it to transform something as simple as plain text files:
In this case, our (default) target is my-content.txt and it is built by simply concatenating the output of two dependent files (created on the fly).

I am successfully using it in other scenarios like web development and mobile app development. But there’s no restriction on how it can be used.
Myth #2
It’s just another task runner, NPM scripts do the same job
That’s indeed not true. Yes, it runs tasks (the commands of a rule) but not necessarily. Let’s put the example above with text files.
When we run make the first time, it will trigger the dependencies and then the main target. So yes, we run a bunch of tasks. But what happens if we run make again?
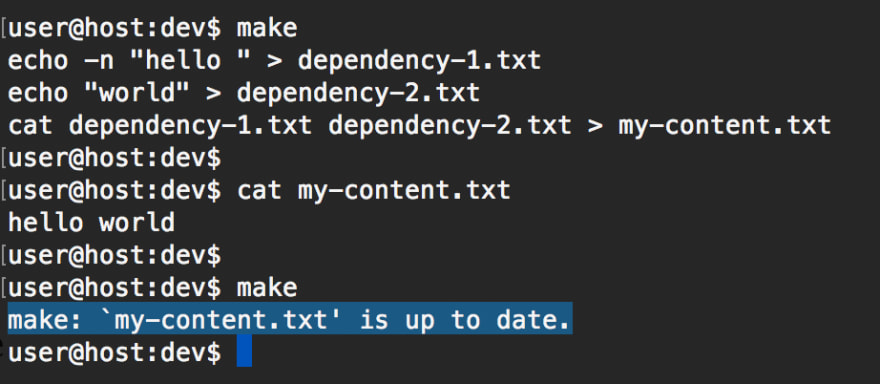
Nothing happens, but why?
It turns out that make is designed to keep track of the modification date of files. In this case, it detects that the modification time of dependency-1.txt and dependency-2.txt has not change since my-content.txt was last built. Hence, my-content.txt does not need to be rebuilt.
What happens if we change the contents of a dependency?

Then, make is smart enough to figure out that only the first rule needs to be executed at this point.
This is not the same as what an
npmscript would doAchieving the same using a shell script would need much more code than a simple
makefileIf each of these 3 rules took 30 seconds to run, you would be saving one minute for yourself on every execution
Myth #3
For web development that’s an overkill tool
If all you ever do is invoking webpack then, it is. In the rest of cases, it might not be at all. Put for example, a simple web site with styles, scripts and a static media gallery like this:

We may want to:
Instal the NPM dependencies
Minify the HTML code
Transpile Typescript, bundle and minify it
Fetch a remote JSON file with data to be imported by Typescript
Compile sass code into CSS and bundle it
Generate the sitemap
Optimize the images and videos
Etc…
You may be thinking of a simple script that would do the trick, run a few commands and the job is done, right? Well, you may get the site built, but at the expense of building everything every time.
Even if you just changed one character, the videos of your web site are going to be transcoded once and again. Even if you have the same styles, sass is going to launch every time. Even if you have a static site generator and the list of products hasn’t changed, your entire application will be rebuilt from scratch.
If you care about speed and efficiency, then make is definitely your friend. But if you only need to launch a few scripts, then make is not the tool you’re looking for.
Top mistakes found when using make
They may be hard to understand if you don’t take the time to carefully read the docs.
It is quite common to see a makefile like this:
The typical approach is to see the makefile as a task/subtask tree. When you run make all then, all the dependencies are build.
While this example might eventually work, what are the main issues?
Using rules as if they were a simple task
This is more of a conceptual concern, but rules are meant to be evaluated, in order to decide whether the target needs to be built or not.
However, in the example above markdown: is being used as an “alias” instead of a rule that prevents useless computation.
A rule’s dependency files are not declared
To take advantage of make, the markdown rule should (at the very least) be written like:
Rule names should be bound to actual output files
Using abstractions like all: markup scripts styles media to make things clean and flexible is fine. However, indirect targets should always link to the specific target file that will fulfill the dependency.
When defined like this, the modification date of the dependencies and the target file tell make wether the rule needs to run again or not.
These are seconds that you can save!
Variables are there to help
If the list of source files is known beforehand, wouldn’t it be great to use a variable instead of hardcoding the dependencies each time?
Note that here, the $(MARKUP_FILES) variable is used to define the dependencies. But it could also be placed on the commands to execute:
Looks good, but we can still do better. Let’s also factorize the sass executable path as well:
Confusion with make and shell variables
In the example above, note that variables like $(STYLE_FILES) are make variables. Not shell variables.
Make variables are evaluated to generate the exact shell command and then, the shell command is executed.
When writing a command like echo $(PWD):
makewill replace$(PWD)by the current value (i.e.)/home/userbashwill then executeecho /home/user
This is not the same as if you run echo $$HOME. In this case:
makewill replace$$by$bashwill executeecho $HOME
Use the builtin variables
Still on the same example, we can improve the rule.
Imagine that index.sass internally imports other sass files. How do we declare them as dependencies, too?
Ok, this change needs a bit of explanation:
The
wildcardkeyword evaluates the glob and puts any matching file path on the variable. So our variable contains a dynamic list of source files.$@is evaluated to the name of the target. In this case it is an alias forbuild/index.css. Instead of rewriting the own name, we can use this shortcut.$<is evaluated to the first dependency of the rule. We use it because sass takes the entry point, instead of the whole list.
In this case,$<evaluates to$(STYLE_FILES)which equals$(wildcard src/index.sass src/styles/*.sass). This is the same as passingsrc/index.sassIf sass took the whole list of files, then we would write
$(SASS) $^ $@.
So the command $(SASS) $< $@ would translate into something like:
./node_modules/.bin/sass src/index.sass build/index.css
Ensure that target folders exist too
If we run the main target as it was, commands would probably complain about the build folder not being present.
A clean way to ensure its existence would be to create a target for the folder and make targets depend on in before running.
markup will trigger build first and build/index.html after.
We could also use it for our NPM packages. A typical way is to define a make init static action, but hey… what if this could be automatic?
Look at this:
When
node_modulesdoes not exist (target), the ruler will be triggered.When
package.jsonchanges (timestamp is newer thannode_modules), the rule will also trigger.
Setting static actions as Phony
On actions that do not depend on any previous state, a special rule should be used. Typically on actions like make clean you want the command to be triggered, regardless of the current artifacts.
Setting .PHONY ensures that if the clean rule is matched, it will always execute.
Why do we need this? Well, imagine that a file named clean is accidentally created on the project. What would happen if we ran make clean? Well, we would get something like: make:clean' is up to date` and you would think “fine, it’s clean”.
But this message would actually mean: The target file clean already exists and it has no newer dependencies. So, no need to do anything.
If you set .PHONY: clean you ensure that clean will always run rm -Rf ./build/*
How would the end makefile of the example look like?
As final remarks:
Think of a makefile in a declarative way, not in an imperative way (a bit like a ReactJS component)
Think of rules as statements that transform some input into some output and run only if the source content has changed
Approach your makefile by looking from the end (the target files, even if they don’t exist yet) and bind any abstract rules to specific output files
And this wraps it up for today 🎉🎊
I hope you found the article cool and refreshing ❄️🍦 enough to scroll down a bit more and hit the clap 👏👏 button 😃.
There’s more to come. If you want to stay tuned, don’t hesitate to follow Stack Me Up and new articles like this will be waiting for you next time.
Until then, take care!
 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://res.cloudinary.com/practicaldev/image/fetch/s--Hry61Ilu--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/14720/0%2A0W8jmPsVmV4P0toh)

Top comments (4)
Awesome article! I remember loving the simplicity of Make back in the day, and now that I think about it, many of the little utility bash scripts I e written could probably be simplified by turning them into makefiles. Thanks for the reminder!
The reminder is just a pleasure, Ken ;)
Great tips, thanks 👍 I use Make as a glorified script runner (all targets are phony), but after this I’ll go optimise.
Just to rant this somewhere: One detail I’ve always hated with Make, is when the default target starts a bunch of processing. I find that terribly confusing because who knows what it’s doing. So I’ve always set up my Makefiles to have a phony default target that explains what can be done.
I'd like to do a quick bonus with an auto help generator. Stay tuned :)