
5 Best practices of the GIT Version Control System (VCS)…
Table Of Contents
1: Best Practices(#chapter-1)
2: Bonus - Pro Tips!(#chapter-2)
Best Practices
1: The Branch Names best practices
One of the most important aspects of GIT is to wisely choose branch names. We make branches on a day-to-day basis and hence, it becomes a very important and good practice to follow branch name conventions.
It not only provides visibility to all the other team members but also makes our life easy to maintain and debug the changes at a later point in time.
Attaching below is a handy and self-explanatory template:

Most of the time we end up messing with our main master branches, a good way to deal is to either make a new master branch with some identifier (stage ex: prod) or directly identifier stable can be used also.
Usually some people/teams preferred the same conventions but with a prefix of the Developer's name. Ex:
burhanuddin/topic-API-rate-limiterwhich is also fine.
2: Commit Messages best practices
Below are the reasons why commit messages are important:
* Clear and concise description or summary of what is done in the commit, or the issue/ticket closed by the commit & leaves a good impression to other developers!
* Visibility & clarity amongst the team members and Debugging!
* If you have any security vulnerabilities in your repository (repo) that GIT reports like We found potential security vulnerabilities in your dependencies and if you have followed the GIT commit messages conventions below then GITHUB will automatically fix that for you by fixing that build-commit directly as per backward compatibility if it's possible.
Attaching the template, commit message format:
COMMIT MESSAGE MASTER FORMAT: <TYPE>(<SCOPE>): <SUBJECT>
SUBJECT:
The subject contains a succinct description of the change:
* Use the imperative, present tense:
“change” not “changed” nor “changes”
* Don’t capitalize the first letter
* No dot/period (.) at the end
SCOPE:
Mainly file_name/s, for a bunch of files, use functionality name
TYPE:
Please see the sub-template attach below for that (divided into 4 segments):

Yes, there are tools like commitizen, etc. that are just all of the above. But, I don’t like that for simple reasons:
* It asks so many details before allowing us to commit
* Restrict us to make it our habit to do it on our own — which I prefer generally!
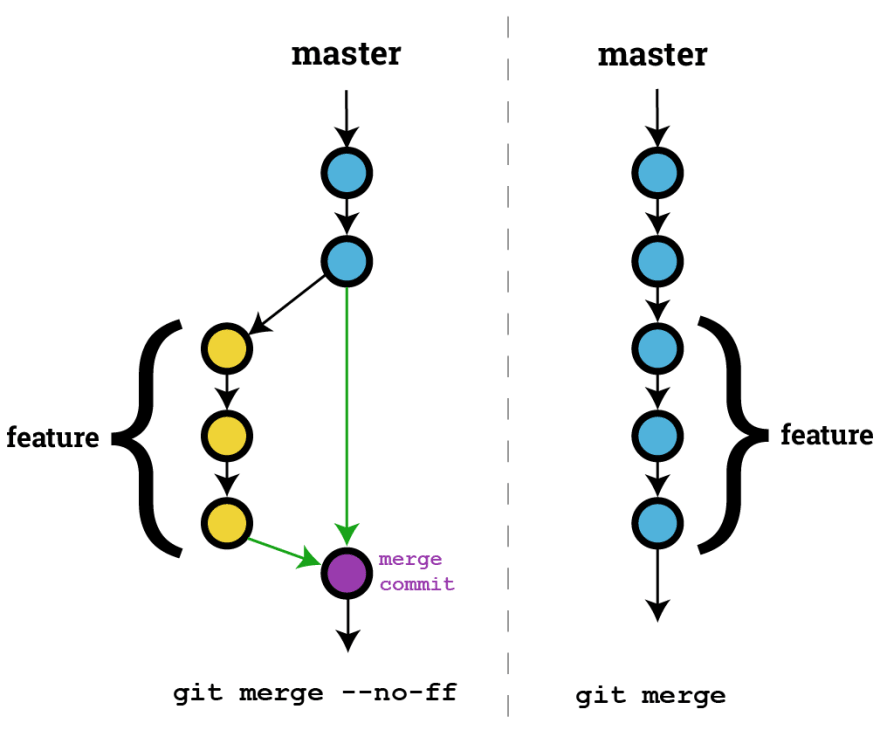
3: Squash, Rebase & then Merge for linear commit history on the stable branch
This is something again based on the practices which various DEV teams follow. Some teams follow and want to maintain merge commit while others prefer to have a linear commit history on the master OR main branch.
The best of both worlds is to Squash the related commit on the feature branch and then go for rebasing followed by a merge. This will have a linear commit history while the related commit will be squashed (like a merge commit)
The downside of the above approach is that you may need to avoid squashing if multiple developers working on the same branch as this approach require force push. A turnaround of this is to use --force-with-lease while pushing on to the feature branch after squashing.
git checkout -b topic-something # HEAD off from stable
git rebase -i HEAD~5 # Squash 5 commit made on the feature
git push origin --force-with-lease topic-something
git pull origin --rebase stable-branch # If fetched already
git push origin topic-something # Pushing merge conflicts fix
git checkout stable-brach
git merge topic-something # W/o --no-ff avoiding merge commit, thus maintaining linear commit history
git push
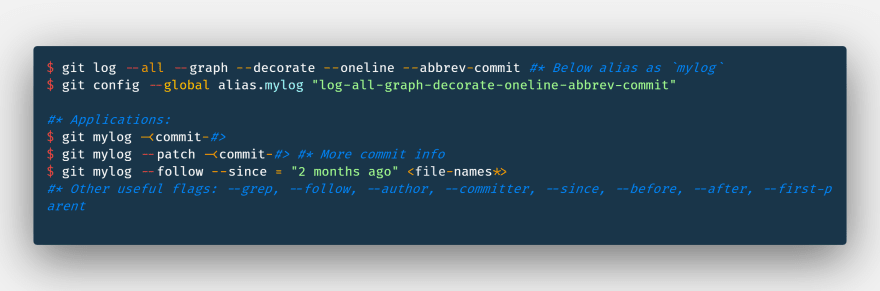
Below is the useful command to check the commit history in the form of decorating graph, you can alias the below command using ~/.gitconfig details on this to be followed.
$ git log --all --graph --decorate --oneline --abbrev-commit
4: Use --reset-index instead of --cached
We at times run into a problem where .gitignore simply doesn’t listen or work. This happens for already tracked files by GIT. Eventually, end up using — cached flag, but it is having 2 disadvantages:
* --cached flag sets that particular file flag as deleted in staging, end up having one extra unnecessary commit.
* And after the commit, if you pull that code, into the production repo, it will delete that file (say config file), and hence eventually mess up the entire production code.
A simple solution is to update that particular file index to listen to .gitignore
$ git update-index --assume-unchanged <file-names*>
5: Use GIT config for aliases, push/pull settings and across different workspaces
GIT config can be highly useful for the following reasons:
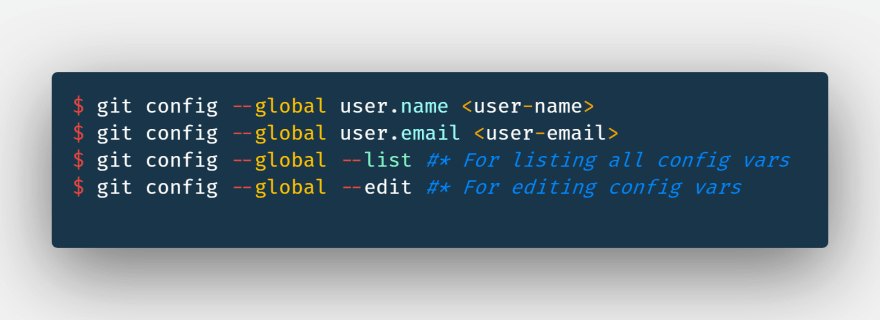
5.1: For adding author info for each commit globally and locally for different workspace across the same system:
5.2: For adding the GIT default merge-tool and diff-tool very handy! Helps in resolving the merge-conflicts from the terminal itself:

5.3: Make aliases for your favorite GIT commands, for example, is used for mainly below command:
There are other more useful features of GIT like setting the core.editor or settings file-options etc. for which GIT config can be used.
Bonus — Pro Tip!
Recently (2019) Github announces GitHub Actions that enables SDLC or CI workflows directly from GitHub only. GitHub Actions are available with GitHub Free, GitHub Pro, GitHub Team, GitHub Enterprise Cloud, and GitHub One.
It is a plus, as compared to using 3P CI services like Travis CI, Circle CI, CodeShip, etc. because it eases the maintenance to maintain the Workflow from GitHub only. Attaching below is a sample YAML file to set up the GitHub Actions into your repo:
Thanks for reading. I hope you will find this blog helpful. Please stay tuned for more such upcoming blogs on cutting-edge Software Development Engineering, Big Data, Machine Learning & Deep Learning. And lastly, always remember to breathe :)
Playlist:
-
Big Data & Cloud Engineering:
- Medium-Towards Data Science Publication — 4 Easy steps to setting up an ETL Data pipeline from scratch
- Medium-Towards Data Science Publication — Amazon S3 Data Lake | Storing & Analyzing the Streaming Data on the go | A Serverless Approach
- Serverless Database migration and replication in nearly no downtime

 towardsdatascience.com
towardsdatascience.com


Top comments (3)
Tip from something I learned the hard way:
If you use branches with slashes NEVER EVER have a branch with a name of part of that path.
e.g.:
If you try to have a branch myfeature and a branch myfeature/testing, you are in for a world of hurt.
Not to be negative, but IMHO I don't agree/wouldn't recommend some of the claims in this article:
Omg... #2 ist terrible advice
Please check chris.beams.io/posts/git-commit/ to understand how commit message should look like and why
Some comments have been hidden by the post's author - find out more