The Description
Casper nodes emit events on state changes. These events in the platform are categorised into three event stream types:
Deploy Events
Finality Signature Event
Main Events
Within each stream type there are multiple event types such as DeployAccepted or BlockAdded
See the Casper documentation for a full description.
The Problem
As can be seen from the diagram below, there will be n nodes emitting 3 event stream types.
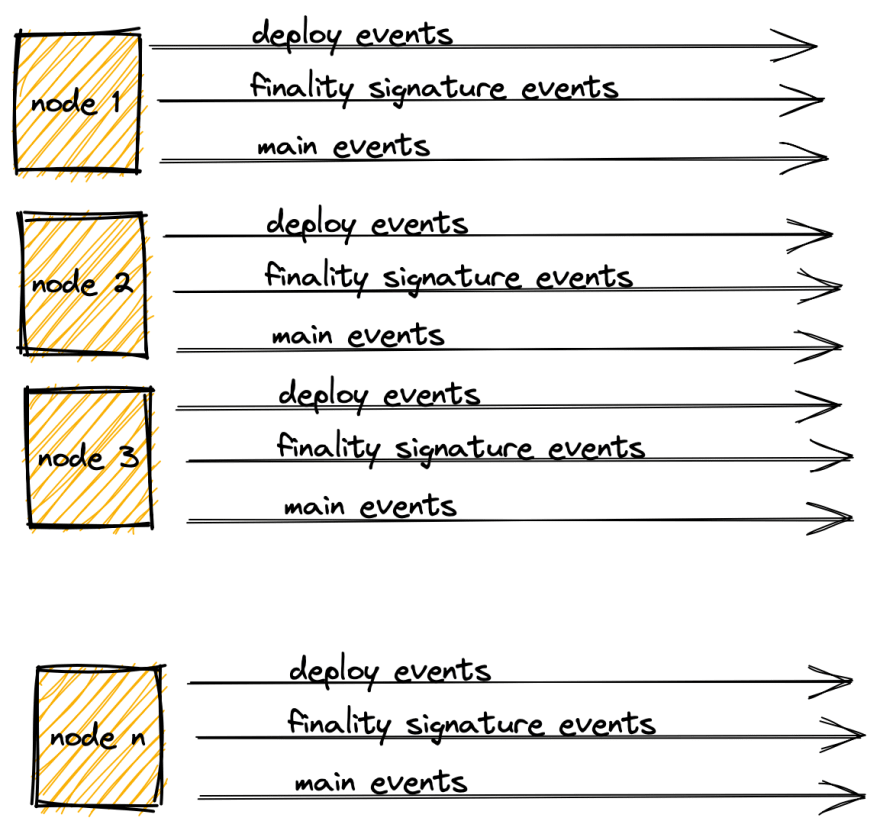
This is a lot of events.
Even if the event stream is restricted to one or a group of nodes we are still seeing many events.
Casper clients use these events to build up a picture of state changes in the node and smart contracts.
These state changes can notify audit tools of any discrepancies, such as suspicious transactions, asset mutation or chain failure.
The Solution
How can we handle so many events?
To reliably consume these event streams we need a high throughput, highly available messaging service.
We need to differentiate the event types.
We need to load balance the event stream types into separate silos (Finality Signature events are the majority of events by many multiples)
We need to be able to replay the events in the case of any data loss or DR
We need confidence in our architecture
Enter Kafka, which will satisfy the concerns above.
Kafka has concepts such as Brokers, Partitions, Replicas, Topics which will all be discussed in details in later sections.
For now we just need to know that Kafka will be running n brokers acting as a cluster. The Kafka cluster will use Zookeeper to orchestrate the brokers.
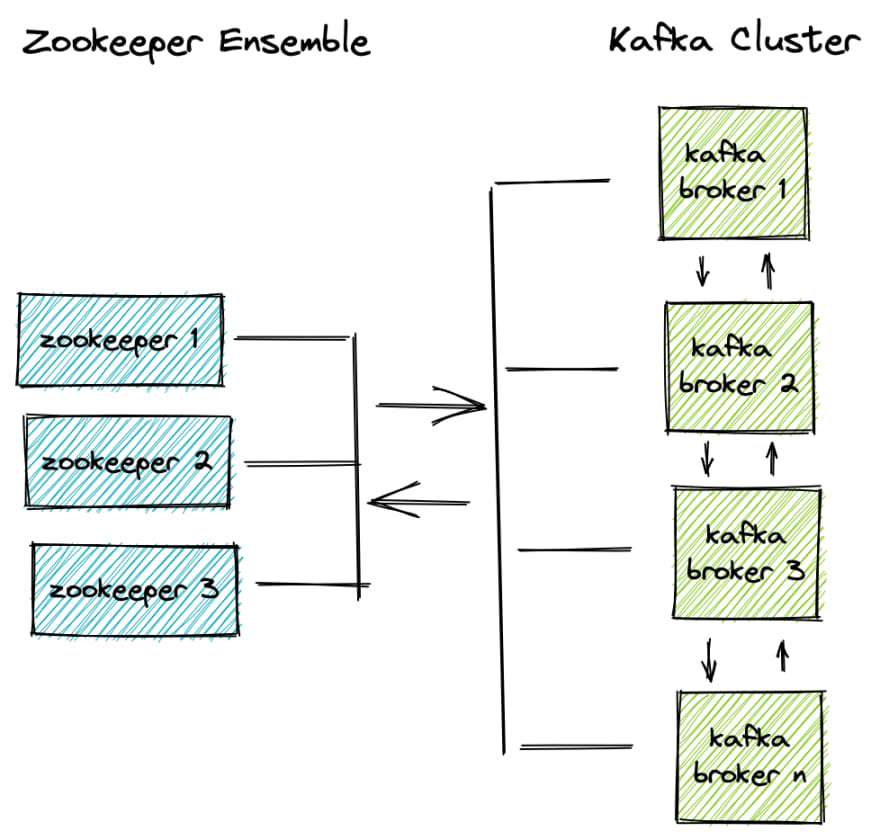
Kafka uses the leader/follower pattern where it will decide amongst itself who is the leader and who follows. If the leader is lost, a new leader will be elected. An odd number is preferred as is always the case with clusters.
Like all messaging systems, we need to produce and consume messages, Kafka like RabbitMQ handily names these as Producers and Consumers. Lets look into how these fit into our architecture:
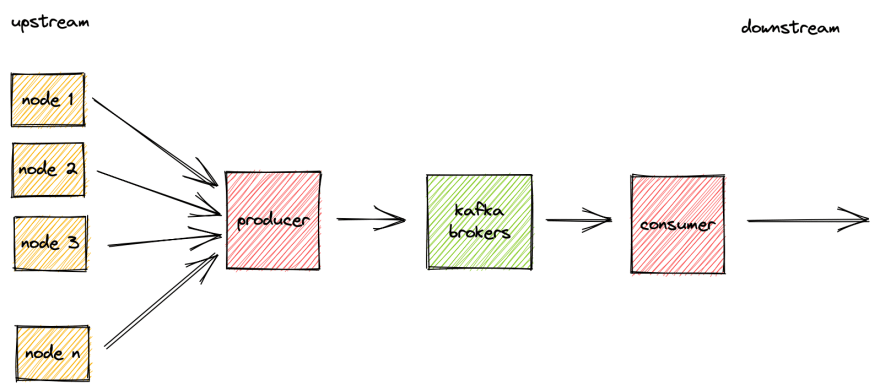
A simple and clean architecture.
The event streams are read by the producer, any transformations are made, eg text to json, and the event is added to a Kafka topic.
The consumer will then retrieve this event via its topic and process it accordingly.
Where can we host this architecture?
Kubernetes. Whatever the question in DevOps, Kubernetes is usually the answer.
For all it’s minor annoyances (looking at you YAML), what other system can give us guaranteed uptime, replicated apps, ease of deployment/updates etc etc. What else are we going to use? Docker Swarm….
So that being said, with K8s we can run multiple instances of the producer and consumer. We can also run the Kafka cluster within the K8s cluster to further guarantee its availability. Here’s what the final architecture diagram looks like:

Consumer groups are a very useful concept added to our solution. They each read a message from a topic once, so both Consumer Group A and B will both read the same message exactly once. Any other consumers can also read the message (Kafka has a time to live on messages)
As can be seen, we are writing to both an Audit and UI document store. Audit will be used to replay the event history in case of DR, UI will be a structured store which can be used by any UI or reporting tools.
Implementation details will follow in the coming articles

Top comments (0)