TLDR: Couchbase announces new AI Services in the Capella developer data platform to efficiently and effectively create and operate GenAI-powered agents. These services include the Model Service for private and secure hosting of open source LLMs, the Unstructured Data Service for processing PDFs and images for ingestion, the Vectorization Service for real-time streaming, storage and indexing of vector embeddings, an Agent Catalog providing an extensible framework to help developers add new capabilities to the agent stack, and AI Functions to enrich data using the power of LLMs, collect key data artifacts generated by agents, and establish guardrails for evolving operations as LLMs and agents develop.
Introducing Capella AI Services
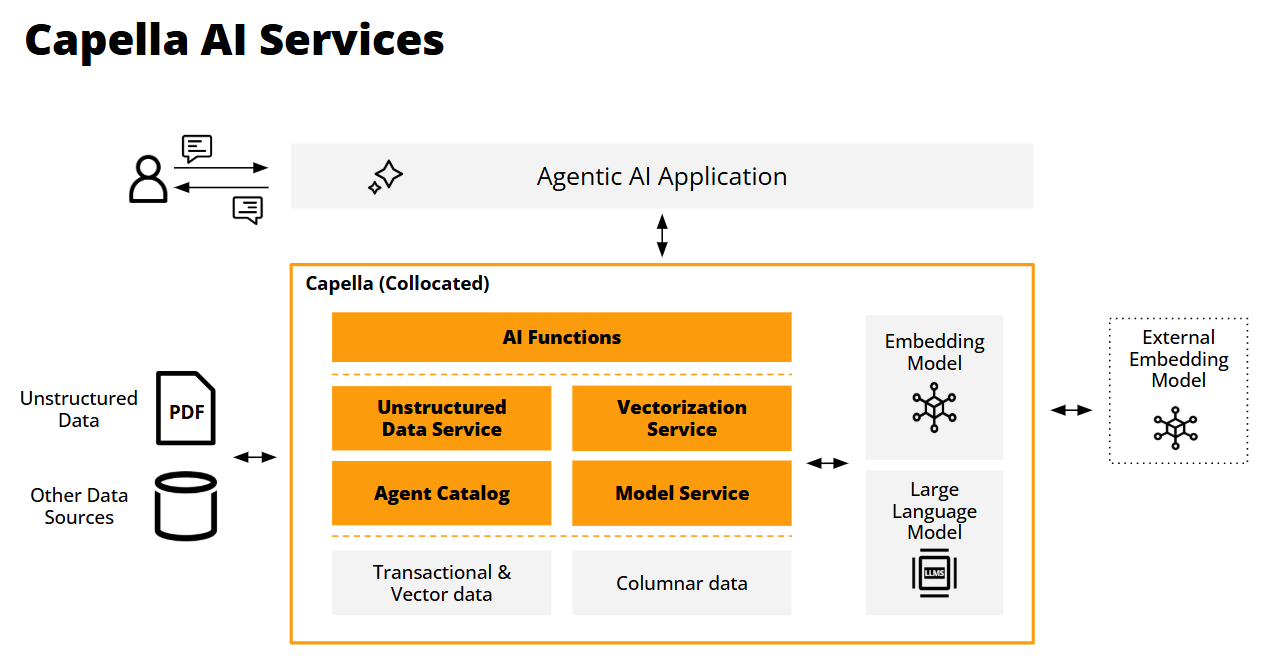
Couchbase is excited to announce a series of new AI Services that will enhance the Capella platform to assist developers in creating and deploying GenAI-powered agents and agentic applications. Agents are autonomous programs designed to use natural language interactions to perform tasks or solve problems by making decisions based on data, conversational exchanges with large language models, and environmental context—all without human involvement.
Agents will not only process textual inputs but also incorporate visual and audio information in executing their tasks. Capella’s AI Services will help developers with many of the data processing steps required when using retrieval-augmented generation (RAG) techniques, and leverage the myriad tools and frameworks within the RAG ecosystem to interact effectively with large language models. Additionally, these services will support architects and DevOps teams in managing the operation of agents over time.

Capella’s new AI Services
-
- Model Service : External, local, and embedded language model hosting to minimize processing latencies by moving models closer to the data and their consumption. This approach helps address data privacy, consistency, and sharing risks by ensuring data never leaves the customer’s VPC. Capella will host models from Mistral and Llama3.
- Vectorization Service: For creating, streaming, storing, and searching vector embeddings to enhance conversation quality and accuracy, and facilitate ongoing interaction contexts as LLMs evolve and may lose context.
- Unstructured Data Service: Transforms unstructured data such as text documents, PDFs, and media types like images and recordings into “chunks” of readable semantic information (e.g., sentences and paragraphs) for generating usable vectors. This pre-processing step broadens the range of use cases agents can support.
- Agent Catalog: Accelerates agentic application development with a centralized repository for tools, metadata, prompts, and audit information to manage LLM flow, traceability, and governance. It also automates discovery of relevant agent tools to answer user questions and enforces guardrails for consistent agent exchanges over time.
- AI Functions: Boost developer productivity by integrating AI-driven data analysis directly into application workflows using familiar SQL++ syntax. This accelerates developer productivity by eliminating the need for external tooling, custom coding, and model management. Capella AI Functions include summarization, classification, sentiment analysis, and data masking.
Through its unified developer data platform, Couchbase empowers customers to deliver their most critical applications in this new AI-driven landscape, offering a persistent, stateful data supply for AI interactions, agent application functionality, and the ongoing development and maintenance of these systems.
Why do we need AI Services?
Agentic application development and operation will introduce many new data-centric challenges. These include:
Working with GenAI fundamentally changes developers’ everyday workflows
While the concept of Agents is straightforwrad–creating task-based programs that independently figure things out, such as making reservations on your behalf–developing Agents requires new techniques beyond RAG to ensure reliable, trustworthy behavior. This involves maintaining consistent behavior within each Agent and every LLM exchange for ongoing Agent invocations over time. Instead of simply designing database-powered applications, developers will need to incorporate agentic interactions between both databases and application functionality. Our new AI Services will help developers take advantage of these new workflows and become proficient in using LLMs in their development.
Everyone must learn new technologies and operational techniques
Building AI-powered functionality introduces new development workflows, integrations, and processes into today’s software development lifecycle. AI interactions will become programmatic, and new types of data, such as vectors, will be both generated and consumed during these exchanges. The new AI Services introduced in Couchbase Capella will help developers and architects address these new processes, including automating RAG (Retrieval Augmented Generation), prompt construction, guardrails for prompts and responses, and response tracking, agent observability, and validation for LLM accuracy. Capella’s AI services will help DevOps make sure that agents are doing what we expected and not creating surprises.
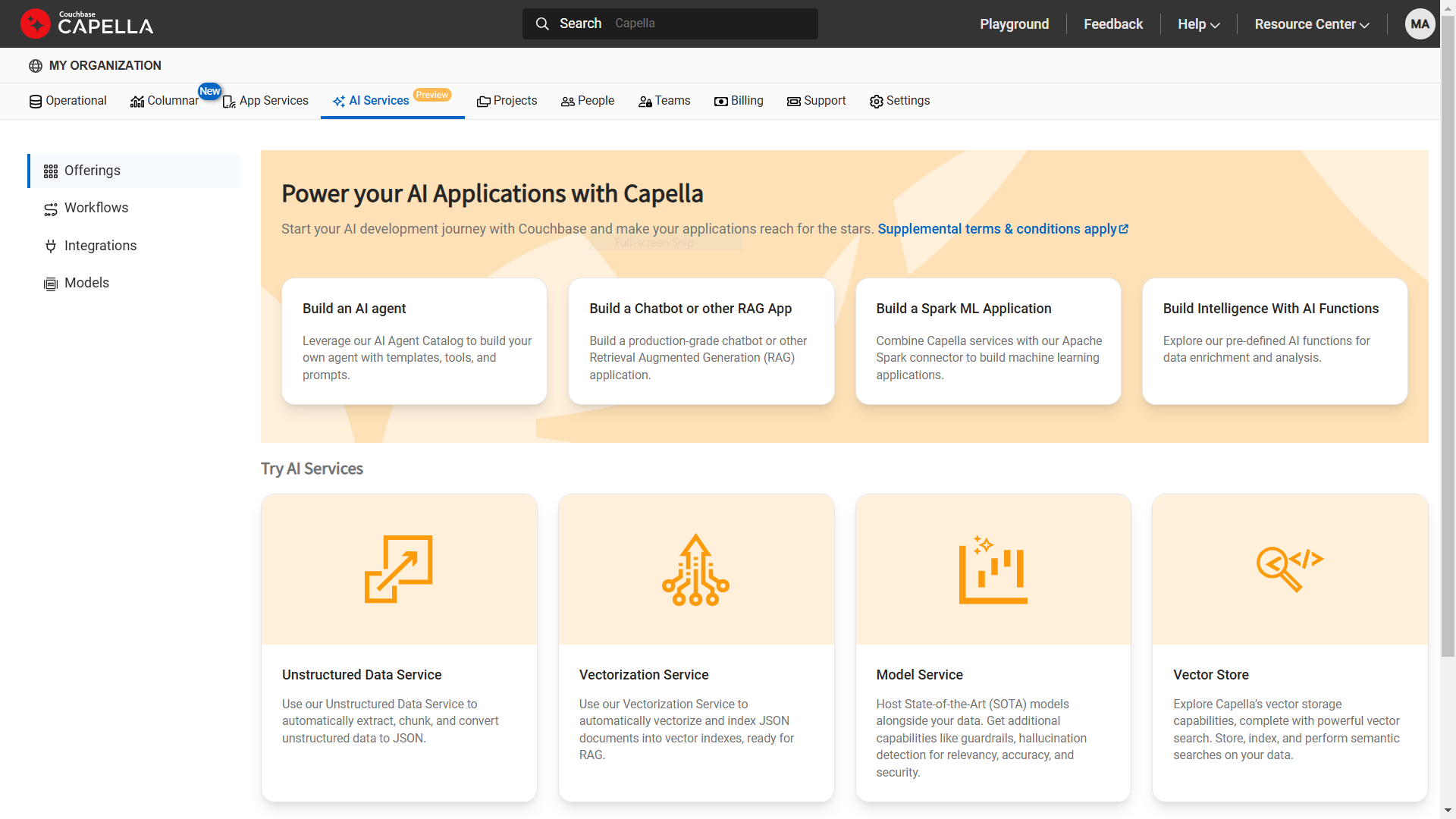
Capella AI Services web-based management interface
Offering proprietary data to private models
According to our conversations with customers, the scariest thing about GenAI is sharing data that shouldn’t be shared publicly. But in many cases proprietary company data is required to make sure the LLM’s knowledge is as accurate and contextual as possible. This may require teaching the model with proprietary and sensitive business data that cannot be divulged publicly. To meet this requirement, LLMs must be privatized or hosted privately and not exposed to the public. To address this need, Capella will host language models privately on behalf of customers.
Intensive conversations with LLMs
Vector Search and chatbot assistants are just the early applications of GenAI. They represent single interactions with one language model. What we will see in the near future is the evolution of RAG to encompass an explosion of multiple exchanges with LLMs, similar to a crowd of back and forth conversations. We will also see Agents working in concert as an ensemble, conversing with multiple models across multiple, ongoing conversations to complete larger, more complex tasks. When we first learned about RAG, it was presented as a single-path workflow with many steps. In reality, agent workflows will be recursive and much more complex.
Reducing latency to improve user experiences
Latency is the enemy of AI. It is especially intolerable when real people are involved. As we mentioned earlier, we expect to reduce latency by hosting models alongside their data supply. Similar to Netflix, we believe that content should be processed close to where it is consumed–on mobile devices for users. A major advantage of Capella is that it offers a local data store, Couchbase Lite, to process LLM exchanges directly on devices. This will help keep users happy because they won’t have to exclusively wait for cloud-hosted LLMs to respond.
Preprocessing unstructured data prior to vectorization
Incorporating both structured and unstructured data within the RAG process is essential. Unstructured data, such as PDF files, is not immediately ready for consumption by an LLM. This data must be parsed, broken into logical chunks, and transformed into simple text or JSON before it can be fed into an embedding model or an LLM’s knowledge base. This is often referred to as “Preprocessing and Chunking,” or preparing unstructured data for inclusion in the RAG processes of an Agent. Capella will offer an unstructured data service for preparing objects like PDFs to be used as sources for vector embeddings and their indexing. During this process, we extract important metadata, chunk and vectorize the data based on its semantic content, and generate high-quality vector embeddings for AI insights.
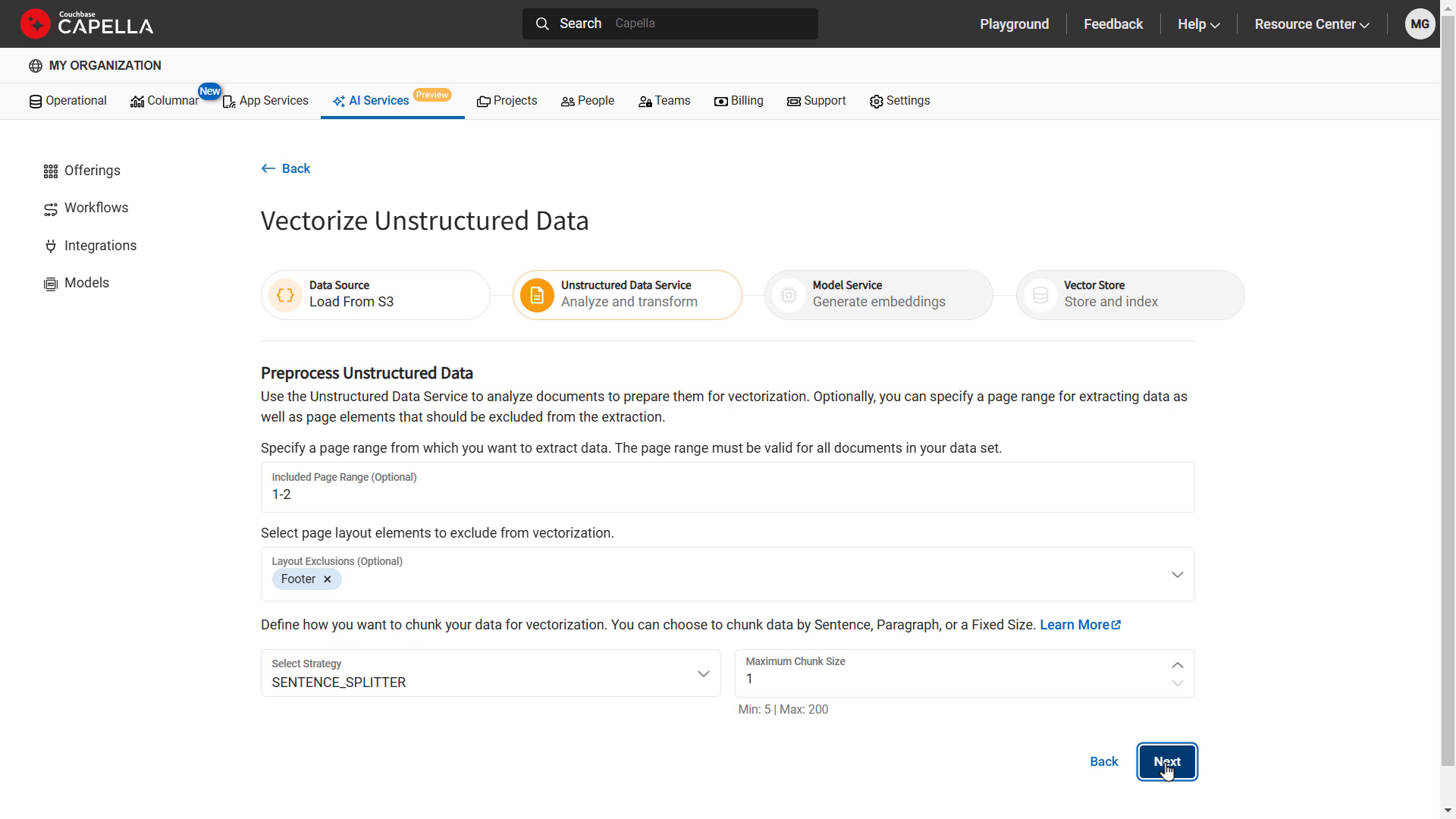
Web-based workflow for managing unstructured data via AI Services
Vectorization: creation and streaming of vectors in real-time
Once processed, this unstructured data, plus regular operational and semi-structured data, can be fed into an embedding model for creating vector indices (vectors) that serve as contextual guideposts within a prompt to an LLM. The process of creating vectors as a streamed service enables real-time context setting and vector creation as the agent runs. The quantity of vector dimensions and embeddings could be immense, potentially reaching the billions. This volume will pose challenges for existing data platforms that are unprepared or under-designed to handle such scale.
Specialization will drive the need for many models and many agents
Developers will need to track the programs that interact with AI models, because models will evolve over time. To keep their knowledge up to date, language models will need to become smaller so they can shrink their learning cycles. As models specialize, they will also become more focused on specific topics or contexts, such as a model that predicts weather patterns, evaluates medical test results, or understands specific laws of physics. Similarly, agents will also become specialized in their functionality. This will create the need for a catalog index that maintains different agents and their interactions with specialized models.
Maintaining persistent context over time
Long-running agents will need data persistence to ensure the outcomes or outputs from the agent remain consistent and as expected over time. This is challenging because large language models do not maintain context from one conversation to the next. They need to be re-informed of their context from session to session, which requires conversations to be preserved.
LLM knowledge changes over time, and agents need guardrails
Further complicating the data preservation problem is the fact that the knowledge in an LLM is dynamic and growing, which means that the model may not provide the same answer to a prompt from one moment to the next. Therefore, developers must incorporate reliability verification routines to check the expected outcomes and consistency of LLM exchanges over time. This means that yesterday’s LLM conversation must be preserved and persisted so that it can be used as validation data for today’s LLM interaction. What this means is that Agent interactions with LLMs—along with their inputs, response outputs, and contextual metadata— must be preserved for each conversion to further accuracy validation. This will generate a lot of data that needs to be stored in an AI-ready database like Couchbase.
Building an agent involves selecting an LLM for reasoning and function calling, managing tools and data, maintaining prompts, optimizing with caching, and iterating for quality. The Couchbase Agent Catalog seamlessly integrates with the Capella Developer Platform to streamline this process, reducing cognitive load for developers. Our multi-agent catalog helps developers manage tools, datasets, templates, ground truth, and prompts across agents. It supports semantic tool selection for queries, provides prebuilt tools, and offers best-in-class model-serving infrastructure for hosting LLMs. Additional features include guardrail enforcement, hallucination detection, query lineage auditing, forecasting, and RAG-as-a-Service (RAGaaS) integration for agent quality assessment.
Minimizing the costs of LLM conversations
Conversations with LLMs will be expensive and slow. Agents will engage in multitudes of conversations with LLMs, which make this a significant challenge. This is why each CSP is excited about the models they support (Bedrock/Claude, Gemini, ChatGPT) as future revenue generators. With Agent performance, milliseconds cost money. Couchbase will leverage multiple performance advantages already built into Capella to make LLM interactions faster and more cost effective. These include the ability to cache common queries for prompts, minimizing redundant hits to an LLM, and offering semantic and conversational caching of LLM results for common answers. Capella also provides performance-tuning features such as multidimensional scaling and cross-datacenter replication. We expect that Capella will offer a compelling price/performance advantage to customers.
Diving further into the challenges and opportunities, Stephen O’Grady, principal analyst at RedMonk, said: “As AI continues to transform the enterprise, it’s posing significant new challenges for infrastructure. In order to apply AI to their existing businesses, enterprises have been required to integrate large and disparate data sources and an array of rapidly evolving AI models using complicated workflows. This has created demand for an alternative, multi-modal data platform with access to not just the necessary training data but the models to apply to it. This is the opportunity Couchbase’s new Capella AI Services were built for.”
Conclusion: Welcome to our AI world!
Couchbase is expanding its developer data platform to include an array of AI services to support both the creation and operation of agentic applications. These services address multiple pressing needs for data persistence and organization when agents are running, and simplify many of the early-stage headaches developers face when creating them. These services will be offered to customers and qualified prospects as a private preview. We are extremely excited about what we are introducing to support critical applications in this new AI world. Come join the ride!
For more information
-
- Read the Press Release
- Check out Capella AI Services or Sign up for the Private Preview
- Blog: What is RAG?
- Blog: What is an AI Agents?
- Register for the webcast: A Roadmap for the New Age of AI Agents – Challenges and Opportunities

The post Couchbase Introduces Capella AI Services to Expedite Agent Development appeared first on The Couchbase Blog.

Top comments (0)