
Originally published in the Cloud Knowledge Base
A strong and mature trend in modern cloud software development is to implement components that are:
- Single-purpose
- Small
- Deployed independently
- Easily testable
These component services are then composed (or orchestrated) into a cohesive and organized workflow to fulfill higher-level tasks and accomplish the business or practical purposes expected from the system.
Having independent components enables software reusability and decoupling of the software architecture. As a result, the entire system can be easier to test, extend and maintain.
How about composition in Serverless?
Composing serverless functions, such as AWS Lambda, is not as easy as it may sound. Many benefits that developers appreciate in serverless functions are dependent on certain properties.
For example:
- High scalability of functions depends on its stateless property
- Pay-per-use model (no idle resource waste) is only possible because functions are ephemeral, run on-demand, with no long-running processes
The same properties that make serverless so attractive are also what poses some challenges for services composition.
In function composition architectures, we would want at least three principles met:
- Substitution: being able to replace (or perhaps extend/modify) a component without breaking the rest of the system;
- Isolation: each component should be a black-box, no service should be aware of other services' implementation details;
- Zero-waste: since serverless is about pay-per-use, we would like to avoid a double-billing situation, for example (more on that below)
Serverless composition challenges
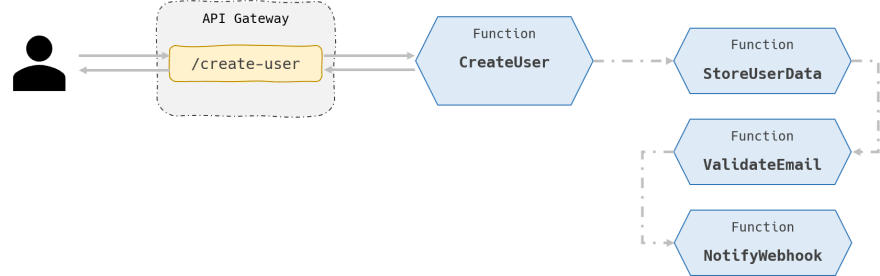
Let's consider a trivial situation: a user creates a free account (no payments involved) and subscribes to an online service. Some tasks should be performed as a result:
- Persist the user data in a database store
- Send a message to validate the user e-mail address
- Notify a webhook to track marketing campaign performance (conversion from lead to a subscribed user)
If each of these tasks should be performed by isolated and independent components, how should we coordinate them together?
A flat, simple implementation would be having a function running behind an API and coordinating all other tasks sequentially. We will see next why this implementation is sub-optimal, but please check the diagram below first:

Recovering the three principles we are looking to meet:
- Substitution
- Isolation
- Zero-waste
The implementation above does not meet any of these desired properties.
Breaks Substitution
First, it makes it difficult to replace and extend components. Suppose this system has been running for a while. Now there is a requirement to also validate the user mobile phone number with an SMS. When CreateUser invokes the ValidateEmail function, it only provides a recipient e-mail address, not a phone number. We cannot just replace ValidateEmail with a more general-purpose ValidateContacts, for example.
Breaks Isolation
Second, the CreateUser function must be aware of other services and at least some of their implementation details. For example, it must be aware that these services are implemented as a Lambda function. This breaks the isolation property.
Breaks Zero-waste
Finally, there is a lot of double-billing going on. While the StoreUserData is communicating with the backend database, for example, the CreateUser keeps waiting in idle state before moving to the next task. Even if the code is implemented asynchronously, there will still be some latency in which multiple functions will be billed at the same time. This breaks the zero-waste property.
Considering options
Let's find out whether we can meet all three desired principles while orchestrating our functions. We will cover several different approaches to function composition below, both in the client and in the backend.
Some of these patterns should be avoided, others are recommended, but have their strong sides and weaknesses and should be considered depending on the context and use case.
Client-side
For processes that have some sort of interaction with a UI (user interface), the orchestration logic could be embedded in the client-side.
In the user subscription example above, this could be structured as such:

The client-side software is responsible for invoking each of the endpoints needed for fulfilling the user creation process. All invocations can be executed in parallel to speed up the overall processing time for the end-user.
There are a few downsides and caveats to this model, though:
Lacks reusability
The client-side model makes code reusability harder. Since enabling reusability is one of the main purposes of designing modular component architecture in the first place, it might not be a good fit for our goals.
The orchestration process is implemented for one single type of client: a web browser. The code implemented for this client cannot be easily transported into a backend serverless environment.
What happens if, for instance, we would like to support programmatic account creation through an API or CLI (Command Line Interface), instead of a browser UI?
One could argue: the same Javascript code running in the browser could be used in a NodeJS serverless function. While that is technically true, from an architectural perspective it may lead to bad implementation.
By moving this client-side diagram architecture to a backend serverless function, we would be back in a situation similar to the sequential model described above. In this model, our composition fails to meet all of the three design principles we are looking for.
Difficult to handle consistency
What happens if the StoreUserData function could not reach the database at the moment the account was being created? The user data would remain pending for storage. Database-wise speaking, the account wouldn't have been created yet.
- Should the client still request the validation e-mail?
- How about the webhook, should it still be notified?
These decisions will all have to be made in the client, increasing the complexity of the software running on the client-side. Depending on the answers to the questions above, it won't be possible to request all three endpoints in parallel. But responding to the user only after a three-step sequential API interaction might be too long.
Exposes internal business rules
Some business rules that would ideally be kept private have to be exposed on the client-side for the orchestration to run there. This is inherent to running code on the client-side and can't really be solved.
Asynchronous Messaging
We covered asynchronous messaging more extensively in another page, so we won't go into details about the concept here.
It is possible to satisfy all three principles with this architecture: substitution, isolation, zero-waste.
The disadvantages of this approach are when we need more fine-grained control over the workflow logic. The same questions related to handling consistency in the Client-side model also apply here. If one step fails, for example, it is very difficult - if not impossible - to control how other steps of the process should behave.
That doesn't mean this pattern shouldn't be used. As a matter of fact, it is perhaps one of the most commonly and successfully used patterns for a serverless composition strategy that is both scalable and maintainable. It's just not a good fit for all use cases.
Chaining
Each function could be wired up, having one invoking the next after the end of each task execution. The end-user waiting time could be reduced by having the API responding early with a confirmation message that the request was received and is being processed.
This model unfortunately also breaks some of the design principles we are looking for.
It is not possible to easily replace a component without affecting other parts of the system. Substitution is broken.
Different components must be aware of each other and some implementation details are leaked to one another. Isolation is broken. This could be solved by using an internal API Gateway or a Message Queue as an interface between components, though.
The last principle, Zero-waste is satisfied, since there would be no double-billing in this model.
Asynchronous Orchestrator
This pattern involves the usage of a concept called Finite-state Machine (FSM). If you are not familiar, please take a look at this introductory article we published recently before moving forward.
In an FSM, it is possible to:
- Easily replace components without breaking the rest of the system
- Have components acting as complete black-boxes, without knowledge of each other or implementation details leakage
- Avoid double-billing
Some additional advantages to this pattern:
- Run multiple tasks in parallel
- Easily handle retry in case of failure in a specific step of the process
- Handle complex logic such as:
if Step_1 returns True:
run Step_2
else:
run Step_3
Along with Asynchronous Messaging discussed above, this is one of the most commonly and successfully used patterns for serverless functions composition.
Although it is a bit more difficult to implement, deploy and test, it meets the needs of more complex workflows while still delivering a scalable and maintainable architectural design.
Most cloud service providers will have managed/serverless offerings of an FSM, which greatly simplifies the implementation and maintenance. AWS, for example, has the StepFunctions service.
References
Leveraging Serverless Cloud Computing Architectures (Master Thesis), by R.T.J. Bolscher
Composition of Serverless Functions, by Olivier Tardieu
Comparison of FaaS Orchestration Systems, by Pedro García López, Marc Sánchez-Artigas, Gerard París, Daniel Barcelona Pons, Álvaro Ruiz Ollobarren and David Arroyo Pinto
The serverless trilemma: function composition for serverless computing, by Ioana Baldini, Perry Cheng, Stephen Jason Fink, Nick Mitchell, Vinod Muthusamy, Rodric M. Rabbah, Philippe Suter, Olivier Tardieu

Top comments (1)
Awesome. Already subscribed to the Newsletter.