
Photo credit: Stefan Vladimirov
When sending messages using a messaging system, you typically have two scenarios you want to achieve. Either you want to:
- send a message to a targeted group of consumers (which might be just one consumer) or
- broadcast the message to all the consumers
Kafka allows you to achieve both of these scenarios by using consumer groups.
Consumer group
A consumer group is a group of consumers (I guess you didn’t see this coming?) that share the same group id. When a topic is consumed by consumers in the same group, every record will be delivered to only one consumer. As the official documentation states: “If all the consumer instances have the same consumer group, then the records will effectively be load-balanced over the consumer instances.”
This way you can ensure parallel processing of records from a topic and be sure that your consumers won’t be stepping on each other toes.
How does Kafka achieve this?
Each topic consists of one or more partitions. When a new consumer is started it will join a consumer group (this happens under the hood) and Kafka will then ensure that each partition is consumed by only one consumer from that group.
So, if you have a topic with two partitions and only one consumer in a group, that consumer would consume records from both partitions.

After another consumer joins the same group, each consumer would continue consuming only one partition.
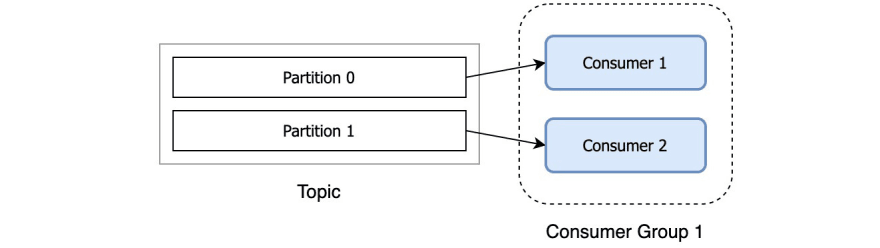
Does it mean if I want to have more than one consumer (from the same group) reading from one topic I need to have more than one partition?
That is correct. If you have more consumers in a group than you have partitions, extra consumers will sit idle, since all the partitions are taken. If you know that you will need many consumers to parallelize the processing, then plan accordingly with the number of partitions.

When we talked about topics and partitions, I mentioned that a partition is a unit of parallelism from the consumer’s perspective. Now you know the reason – there is a direct link between the number of partitions and number of consumers from a group reading in parallel.
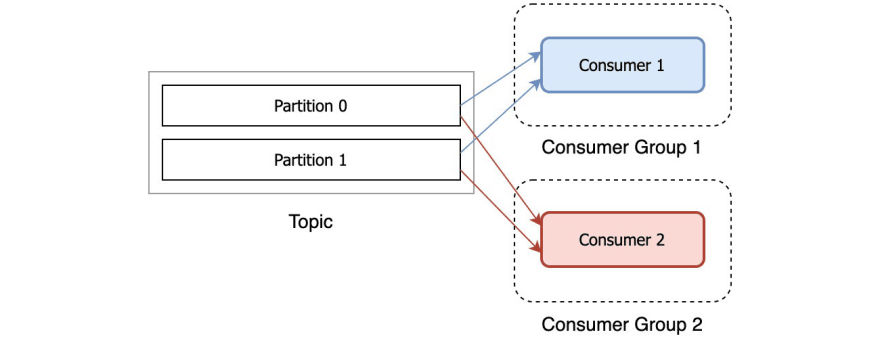
What if I want to consume the same record from multiple consumers?
That is also possible. You can have many consumers reading the same records from the topic, as long as they all have different group ids.
An example to recap
Let’s illustrate what we’ve been talking about with an example.
Let’s say we’re building an online store and it consists of few microservices that are sending events to each other: payment service, shipping service, and notification service. Once the payment service processes the payment it will send an event PaymentProcessed as a record on Kafka topic. Then we want both the shipping service and notification service to consume this record. The shipping service needs the record in order to start the shipping process, while the notification service wants to receive this record so it could send an email to the customer saying ‘Your payment has been received‘. In this case, we want the PaymentProcessed record to be broadcasted to all the consumers.

Yet, if we have multiple instances of the consuming services, we always want exactly one of the instances to process each record. For example, we wouldn’t want multiple instances of the notification service to process the PaymentProcessed record and send multiple ‘Your payment has been received’ emails to the customer. Nor would we want multiple instances of shipping service to receive the same PaymentProcessed record and start the shipment process multiple times, potentially losing us money.
To ensure the record reaches both the shipping and the notification service but only once, we would put all the payment service instances in one consumer group and put all the notification service instances in another consumer group.
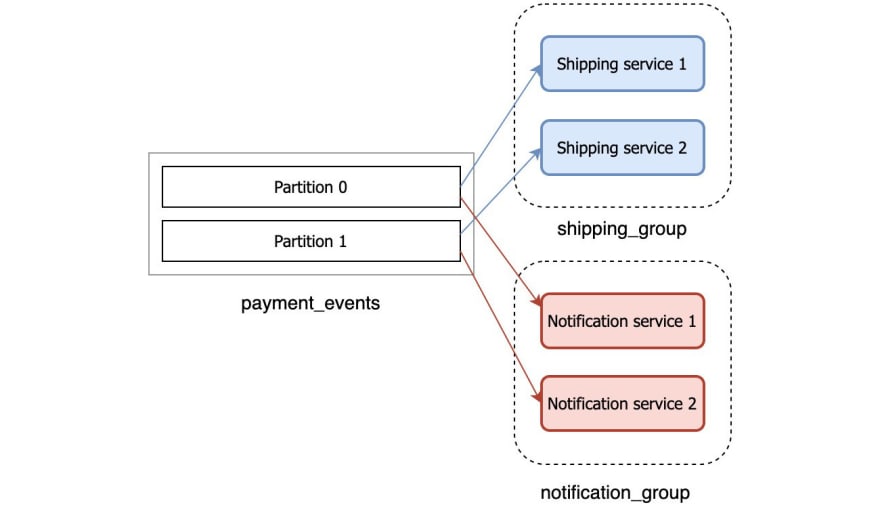
This ensures that all the records are always read by both shipping_group and notification_group, but within those groups, one record will always go to only one instance. That’s what consumer groups enable us to do.
A consumer group and record offset
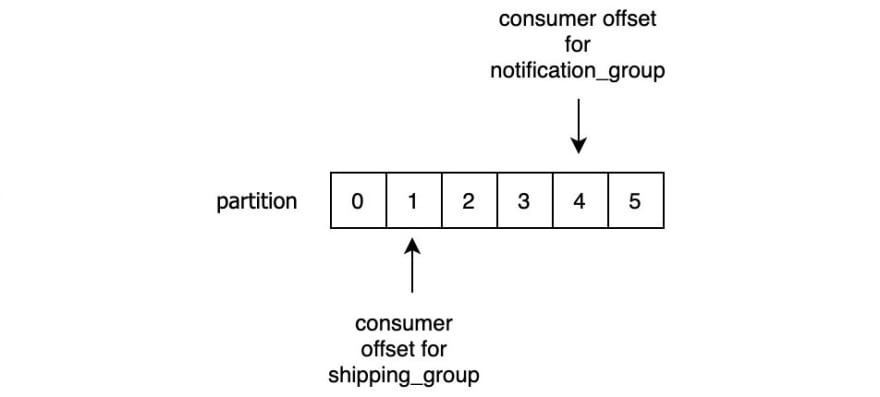
If you remember when we talked about topics, we said that each record is uniquely identified by an offset in the partition. These offsets are used to track which record has been consumed by which consumer group.
Kafka employs an approach of ‘a dumb pipeline, smart clients’ meaning that Kafka brokers don’t know anything about consumer offsets. The consumers themselves are in charge of tracking which records have been consumed. Once the consumer reads the record it will store this offset in a special Kafka topic called __consumer_offsets (yes, those are two underscores at the beginning). When a consumer stores the offset in this topic we’re saying that it’s committing the offset.
This enables consumers to always know which record should be consumed next from a given partition. Since the consumer offset is stored in Kafka, it means that the position of the consumer group is maintained even after restarts.
In the topic post, I also mentioned that records remain in the topic even after being consumed. This allows multiple consumers to consume the same message, but it also allows one more thing: the same consumer can re-consume the records it already read, by simply rewinding its consumer offset. This is very useful when you e.g. had a bug in your consumer and want to re-read the records after fixing the bug.
And there you have it, Kafka consumer groups in a nutshell.
Would you like to learn more about Kafka?
I have created a Kafka mini-course that you can get absolutely free. Sign up for it over at Coding Harbour.

Top comments (5)
Literally the best available over internet
very helpful for beginners in flink to read!
Great article!
One typo here: "we would put all the payment service instances"
"payment"should be "shipping"
Excellent article, thanks for sharing.
Nice Article , very easy to understande . :P