Containers on Kubernetes is the modern way of deploying, managing and scaling applications in the cloud. At Engine Yard, we’ve always built products that make it easy for developers to deploy applications in the cloud without developing cloud expertise - in other words, we always helped developers focus on their applications; not the plumbing around deployment, management and scaling. In early 2021, we released container support on Engine Yard (called Engine Yard Kontainers, EYK for short). We spent more than a year architecting and building the product. Happy to share the lessons we learned in the process.
Kubernetes is the way to go:
Kubernetes (also known as K8s) is the best thing that happened to modern application deployment, particularly on the cloud. There’s no doubt about it. Some of the benefits of deploying Kubernetes include improved engineering productivity, faster delivery of applications and a scalable infrastructure. Teams who were previously deploying 1–2 releases per year can deploy multiple times per month with Kubernetes! Think ‘Agility’ and Faster time to market.
Kubernetes is complex:
OK. That’s an understatement - Kubernetes is insanely complex. Here’s a visual analogy of how it feels like in expectation vs. reality.


• Out of the box Kubernetes is almost never enough for anyone. Metrics, logs, service discovery, distributed tracing, configuration and auto-scaling are all things your team needs to take care of.
• There's a steep learning curve with Kubernetes for your team.
• Networking in Kubernetes is hard.
• Operating and tuning a Kubernetes cluster takes a lot of your team’s time away from development.
Given the enormous benefits of Kubernetes and the complexity involved, it’s almost always beneficial to choose a managed Kubernetes service. And remember - not all managed Kubernetes services are created equal - we’ll talk about it in a while. Nonetheless, these lessons we learned below are useful irrespective of your choice of Kubernetes service.
Here’s the list of 10 lessons:
1 Stay up to date with Kubernetes releases
Kubernetes is evolving fast and they release rapidly. Make sure you have a plan to stay up to date with Kubernetes releases. It’s going to be time consuming and it might involve occasional downtime but be prepared to upgrade your Kubernetes clusters.
As long as you do not change your application’s container image, Kubernetes releases themselves may not force a big change on your application but the cluster configuration and application management would probably need changes when you upgrade Kubernetes.
With Engine Yard, here are the few things we did:
• Planned for cluster upgrades and updates without application code changes and with minimal application downtime
• Created a test plan that we execute every time there is an upgrade or update on the cluster - just to make sure that we are addressing all aspects of the cluster management
• Architected the product to run multiple versions of Kubernetes clusters. We don’t want to run multiple versions because that’s a lot of work but we know that we’ll eventually run into a situation where we’d be forced to leave a particular version without upgrading because that version might break applications of several customers.
2 Set resource limits
Kubernetes is designed to share resources between applications. Resource limits define how resources are shared between applications. Kubernetes doesn’t provide default resource limits out-of-the-box. This means that unless you explicitly define limits, your containers can consume unlimited CPU and memory.

These limits help K8s with right orchestration - (a) K8s scheduler chooses the right node for the pod (b) limits maximum resource allocation to avoid noisy neighbor problems (c) defines pod preemption behavior based on resource limits and available node capacity.
Here’s a brief description of of four resource parameters:
- cpu.request - minimum cpu requested by the pod. K8s reserves this CPU and cannot be consumed by other pods even if the pod is not using all of the requested CPU.
- cpu.limit — if a pod hits the CPU limit set for it, Kubernetes will throttle it preventing it to go above the limit but it will not be terminated
- memory.request - minimum memory requested by the pod. K8s reserves this memory and cannot be consumed by other pods even if the pod is not using all of the requested CPU.
- memory.limit - if a pod goes above its memory limit it will be terminated
There are other advanced concepts like ResourceQuota which help you set resource limits at the namespace level but be sure to set at least these four parameters listed above.
With Engine Yard, here’s how we set resource limits:
- We simplified these limits to a metric called Optimized Container Unit (OCU) which is equal to 1GB of RAM and proportionate CPU. Developers just need to decide the number of OCUs (vertical scaling) and number of pods / containers (horizontal scaling).
- We automatically set and tune Kubernetes resource limits based on OCU
- We developed a system of predictive scaling that factors in the resource limits (via OCUs) and usage patterns - more on that later
3 Watch out for pod start times
Whether your application is a standard application, serverless or follows micro-services architecture, you always need to watch out for pod start times. Managed K8s platforms promise pod availability around 2 seconds but that’s far from reality when it comes getting your application container up and running - total time (including pod availability, pulling docker image, booting the application etc.) can be minutes before you can expect your application to be available.
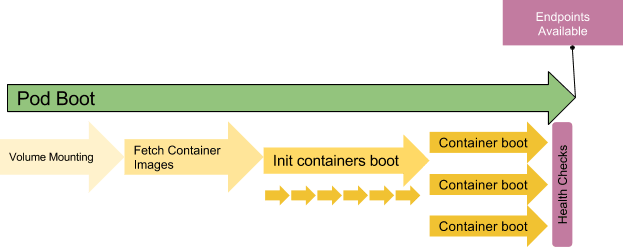
Steps involved in pod booting - courtesy Colt McAnlis
The best bet is to test your application's start times and tune the infrastructure such as K8s configuration, docker image size and node availability.
With Engine Yard:
- We provide standard ‘application stacks’ which are tuned for a particular runtime environment such as ‘Ruby v6 stack’. This allows us to tune these application stacks for faster start times and superior performance.
- Node availability is the single biggest factor that influences pod start times. We built a predictive scaling algorithm that scales underlying nodes ahead of time.
4 AWS Load Balancer alone is not enough
Engine Yard runs on Amazon Web Services (AWS). For each of our EYK private clusters, there is an underlying AWS EKS cluster and a corresponding Elastic Load Balancer (ELB). We learned through our experience that AWS ELB alone is not enough because of the limited configuration options that ELB comes with. One of the critical limitations is that it can’t handle multiple vhosts.
You can use either HAPorxy or NGINX in addition to ELB to solve this problem. You can also just use HAProxy or NGINX (without an ELB) but you would have to work around dynamic AWS IP addresses on the DNS level.
With Engine Yard:
• We configured an NGINX based load balancer in addition to the ELB that is standard in an Elastic Kubernetes Service (EKS) cluster.
• We generally prefer using AWS managed services because those scale better with less configuration but in this case, ELB limitations forced us to use a non-managed component (NGINX).
• When you set up NGINX as the second load balancer, don’t forget to configure auto scaling of NGINX - if you don't, NGINX will become your bottleneck for scaling traffic to your applications.
5 Setup your own logging
When you deploy your applications on Kubernetes, those applications run in a distributed and containerized environment. Implementing Log Aggregation is crucial to understanding the application behavior. Kubernetes does not provide a centralized logging solution out of the box but it provides all the basic resources needed to implement such functionality.
With Engine Yard, we use EFK for logging:
• We use Fluent Bit for distributed log collection
• Fluent Bit aggregates data into Elasticsearch
• Kibana helps you analyze logs that are aggregated into Elasticsearch
6 Setup your own monitoring
Monitoring your applications and cluster is important. Kubernetes does not come with built-in monitoring out of the box.
With Engine Yard, we use:
• Prometheus for metrics and alerting
• Grafana for metrics visualization
7 Size and scale it right
There are two, well - may be three, ways of scaling your K8s cluster.
- Cluster Autoscaling
- Vertical Sizing & Scaling
- Pod Sizing
- Vertical Pod Autoscaling
- Horizontal Pod Autoscaling
These are a bit tricky but it’s important to understand and configure them right.
Cluster Autoscaler automatically scales up or down the number of nodes inside your cluster. A node is a worker machine in Kubernetes. If pods are scheduled for execution, the Kubernetes Autoscaler can increase the number of nodes in the cluster to avoid resource shortage. It also deallocates idle nodes to keep the cluster at the optimal size.
Scaling up is a time sensitive operation. Average time it can take your pods and cluster to scale up can be 4 to 12 minutes.

Pod Sizing is the process of defining the amount of resources (cpu and memory) you need for your pod (equals the size of container if you are keeping 1 pod per container) at the time of deployment.
As we discussed in resource limits, you are going to define the pod size with (1) min cpu (2) max cpu (3) min memory (4) max memory.
The most important thing is to make sure that your pod isn’t smaller than what you’d need for a bare minimum workload. If it’s too small, you won’t be able to serve any traffic because your application might end up in out of memory errors. If it’s too big, you’ll be wasting resources - you are better off enabling horizontal scaling.
Right pod sizing would approximately be a [minimum + 20%]. Then, you’d apply horizontal scaling on that pod size.
Vertical Pod Autoscaling (VPA) allows you to dynamically resize a pod based on load. However, this is not a natural or common way to scale in K8s because of few limitations.
• VPA destroys a pod and recreates it to vertically autoscale it. It defeats the purpose of scaling because of the disruption involved in VPA
• You cannot use it with Horizontal Pod Autoscaling and more often that not, Horizontal Pod Autoscaling is way more beneficial
Horizontal Pod Autoscaling (HPA) allows you to scale the number of pods at a predefined pod size based on load. HPA is the natural way of scaling your applications in K8s. Two important things to consider for successful HPA are:
- Size the pod right - if the pod size is too small, pods can fail and when that happens, it wouldn’t matter how much you scale horizontally.
- Pick your scaling metrics right - (a) average CPU utilization and (b) average memory utilization are the most common metrics but you can use custom metrics too
With Engine Yard, we use:
• Engine Yard manages cluster autoscaling for its customers and we use custom built predictive cluster scaling to minimize the time it takes to scale your pods.
• Each application configures its pod sizes in increments of 1GB memory (we call these Optimized Container Unit = OCU) that allows fine grained control while making it simpler to size pods.
• We do not encourage Vertical Pod Autoscaling
• We fully support and manage Horizontal Pod Autoscaling for our customers including (a) cpu, memory based scaling and (b) custom metrics based scaling
8 Not all Managed Kubernetes are created equal
There are several offerings in the market that claim to be ‘Managed Kubernetes’ services. What you really need to understand is the level of managed services each of these offer. In other words, what the service manages for you and what you are expected to manage yourself.
For example, AWS Elastic Kubernetes Service (EKS) and Google Kubernetes Engine (GKE) position themselves as Managed Kubernetes services but you cannot manage these K8s clusters without in-house DevOps expertise.
With Engine Yard:
• We designed the EYK product to be a NoOps Platform as a Service (PaaS) where our customers can focus on their applications and not need in-house DevOps expertise. Our customers are expected to just deploy their code to EYK with git push and the platform takes care of the rest.
• We top it off with exceptional support (as Engine Yard always did) so that customers never have to worry about ‘Ops’
9 Setup a workflow to easily deploy and manage applications
What’s the cluster worth if you cannot easily and continuously deploy applications to the cluster? Describing apps, configuring service, configuring ingress, setting configmaps etc. could be overwhelming to set up for each application. Make sure there is a workflow process / system for managing the lifecycle of applications deployed on your K8s cluster.
With Engine Yard:
• We add a developer friendly layer to Kubernetes clusters. This layer makes it easy to deploy applications from source via git push, configure applications, creating and rolling back releases, managing domain names and SSL certificates, providing routing, and sharing applications with teams.
• Developers can access their cluster and applications via both a web based UI and a CLI.
10 Containerization is not as hard as you think
You do need to containerize your application in order to run it on Kubernetes and containerizing from scratch is hard. Good news is - you don’t necessarily need to start containerization from scratch. You can start with prebuilt container images and customize those. Start with public container registries such as Docker Hub, GutHub Container Registry to find a suitable image to start with.
With Engine Yard:
• We create ‘Application Stacks’ which are prebuilt container images to suit most common application patterns.
• Based on the code in your repositories, many times, Engine Yard is able to recommend suitable Application Stacks for your application.
• As an additional benefit of building ‘Application Stacks’, we can tune these stacks for faster start times, better performance and greater scalability.
• Containerization, particularly when your team doesn’t have DevOps expertise, can be hard despite all the guidance. That’s why our support team helps our customers with the process.
One more thing! When you set up Kubernetes and components, it’s better to do it using Terraform scripts and Helm charts so that you can always reproduce the cluster (by running these scripts again) whenever you need it.
Enjoy all the goodness of Kubernetes and Containers!

Top comments (3)
Very informative.
Thank you, @pavanbelagatti . We have been producing such blogs for long. Read them here: blog.engineyard.com/
Thank you, @cermitio . Read more such blogs on our website: blog.engineyard.com/