title: [LangChain] Potential Issues with LangChain Embedding
published: false
date: 2023-07-10 00:00:00 UTC
tags:
canonical_url: http://www.evanlin.com/langchain-embedding-issue/
---

# Preface:
I previously took the new DeepLearning.ai course "[LangChain Chat with Your Data](https://learn.deeplearning.ai/langchain-chat-with-your-data)", which shares many very practical case studies. Here, I want to share a problem that is easy to misunderstand.
## Case 1: Searching for Excessive Similarity, But Forgetting Important Information
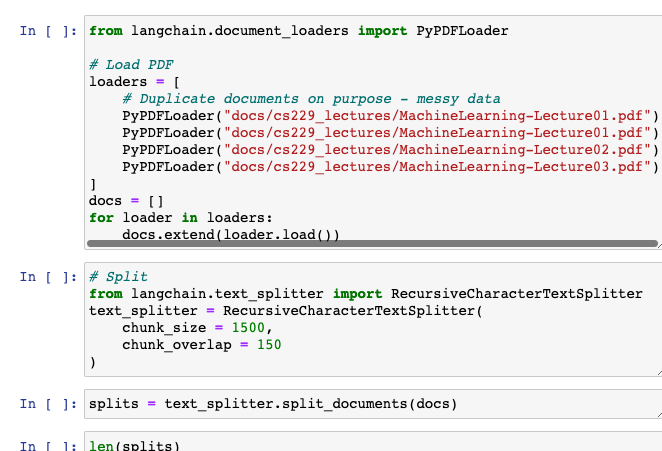
Here, four documents are loaded. You can see that it intentionally rereads the files once or twice, intending to make the data incorrect.
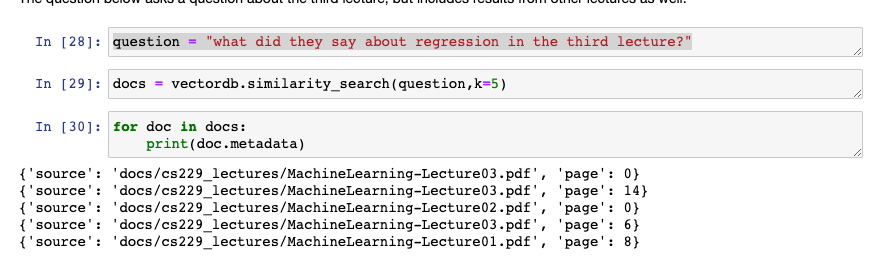
When trying to query "whether there is data about Regression in 'Chapter 3'", due to the data confusion, it will also return the results of Chapter 1, because there is a confusion problem. This causes it to not pay attention to "Chapter 3", but only to the word "regression".

At this time, use the "Maximum Marginal Relevance (MMR)" method to find the data, and don't look for the closest data.
vectordb.max_marginal_relevance_search(query,k=2, fetch_k=3)
`query = "What is the bitcoin?"
query = "What is the bitcoin?"
vectordb.similarity_search(query, k=2, filter={"page": 1})
`
Through `filter`, you can specify many parameters, from which document, from which content is cut, and even content comparison.

Top comments (0)