title: [Online Course Notes] DeepLearningAI - Advanced Retrieval for AI with Chroma
published: false
date: 2024-01-07 00:00:00 UTC
tags:
canonical_url: http://www.evanlin.com/advanced-retrieval-for-ai-with-chroma-note/
---

# Course Introduction
A new course from Deep Learning AI, focusing on how to optimize IR/RAG on Chroma. The instructor is a Chroma co-founder, and the course covers the following three techniques:
- Query Expansion: Expanding queries through related concepts.
- Cross-encoder reranking: Sorting query results through different retrieval encoding.
- Training and utilizing Embedding Adapters: Optimizing retrieval results by adding adapters.
#### Course Information: [https://learn.deeplearning.ai/advanced-retrieval-for-ai/](https://learn.deeplearning.ai/advanced-retrieval-for-ai/)
## RAG Pitfall
Often, the results returned by RAG queries are irrelevant. How can you tell? Using a umap package.
import umap
import numpy as np
from tqdm import tqdm
embeddings = chroma_collection.get(include=['embeddings'])['embeddings']
umap_transform = umap.UMAP(random_state=0, transform_seed=0).fit(embeddings)
畫點出來
import matplotlib.pyplot as plt
plt.figure()
plt.scatter(projected_dataset_embeddings[:, 0], projected_dataset_embeddings[:, 1], s=10)
plt.gca().set_aspect('equal', 'datalim')
plt.title('Projected Embeddings')
plt.axis('off')
### Comparing Similar Questions (Single Question, Relatively Easy)

It appears that the information queried is quite similar to what we asked. Red indicates the answer. Green indicates the preceding few related items.
### If there are more than two questions, or the questions themselves are not very related.

This will result in very different results, causing the relevance of the queried data to be too low. The results obtained will, of course, be very poor.
The solution relies on the following three methods.
## Query Expansion
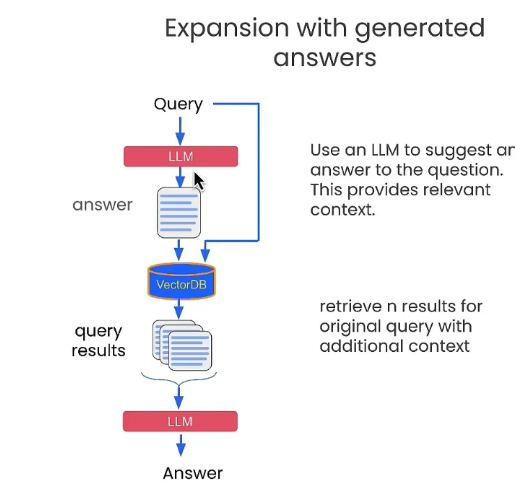
**By extending the hypothetical answer, adding it to the original question. Ask together:**
def augment_query_generated(query, model="gpt-3.5-turbo"):
messages = [
{
"role": "system",
"content": "You are a helpful expert financial research assistant. Provide an example answer to the given question, that might be found in a document like an annual report. "
},
{"role": "user", "content": query}
]
response = openai_client.chat.completions.create(
model=model,
messages=messages,
)
content = response.choices[0].message.content
return content
e.g.
- Q: Was there significant turnover in the executive team?
- First, use this Q directly to ask OpenAI to get a possible answer `hypothetical_answer`, but because there is no specific RAG data, it may not be correct.
- By combining `f"{original_query} {hypothetical_answer}"` and then using VectorDB to find the answer.
original_query = "Was there significant turnover in the executive team?"
hypothetical_answer = augment_query_generated(original_query)
joint_query = f"{original_query} {hypothetical_answer}"
print(word_wrap(joint_query))
## Cross-encoder reranking
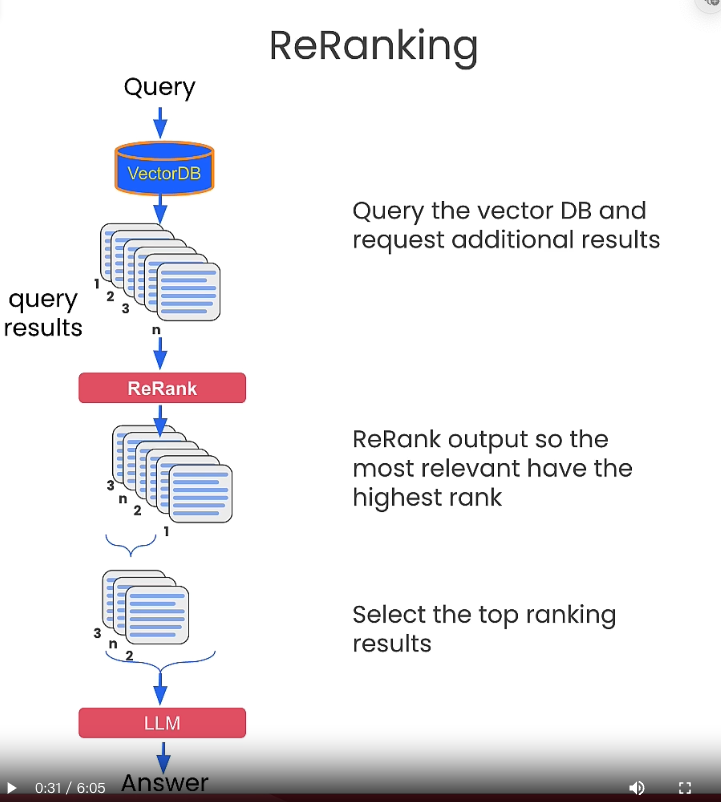
**By using different questions to obtain similar questions. Use this method to score.** The approach here is as follows:
- The original question `original_query` gets several `generated_queries`:
- Then, use the original question and other questions to find the answers to the array.
- For each set of answers, score them by using `scores = cross_encoder.predict(pairs)`.
- Select a few items with higher scores and then go to RAG
original_query = "What were the most important factors that contributed to increases in revenue?"
generated_queries = [
"What were the major drivers of revenue growth?",
"Were there any new product launches that contributed to the increase in revenue?",
"Did any changes in pricing or promotions impact the revenue growth?",
"What were the key market trends that facilitated the increase in revenue?",
"Did any acquisitions or partnerships contribute to the revenue growth?"
]
queries = [original_query] + generated_queries
results = chroma_collection.query(query_texts=queries, n_results=10, include=['documents', 'embeddings'])
retrieved_documents = results['documents']
Deduplicate the retrieved documents
unique_documents = set()
for documents in retrieved_documents:
for document in documents:
unique_documents.add(document)
unique_documents = list(unique_documents)
pairs = []
for doc in unique_documents:
pairs.append([original_query, doc])
print("Scores:")
for score in scores:
print(score)
## Training and utilizing Embedding Adapters
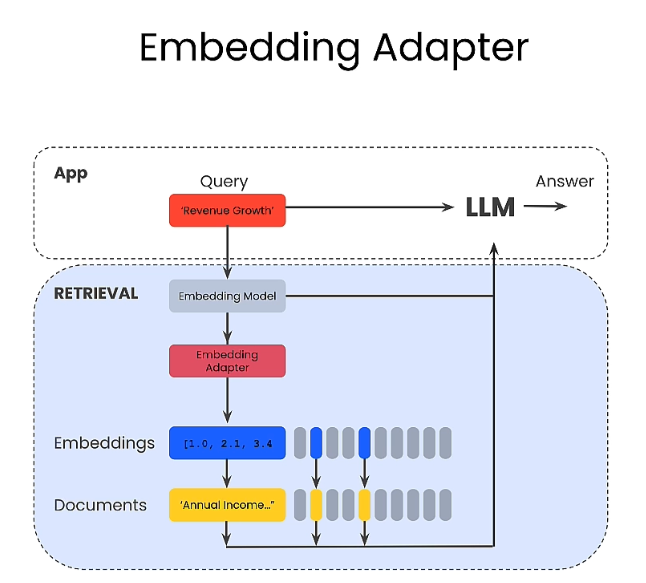
產生相關問句
def generate_queries(model="gpt-3.5-turbo"):
messages = [
{
"role": "system",
"content": "You are a helpful expert financial research assistant. You help users analyze financial statements to better understand companies. "
"Suggest 10 to 15 short questions that are important to ask when analyzing an annual report. "
"Do not output any compound questions (questions with multiple sentences or conjunctions)."
"Output each question on a separate line divided by a newline."
},
]
response = openai_client.chat.completions.create(
model=model,
messages=messages,
)
content = response.choices[0].message.content
content = content.split("\n")
return content
Generate related answers
generated_queries = generate_queries()
for query in generated_queries:
print(query)
Through 10 ~ 15 questions, generate derived answers. About 150. This becomes a new dataset. (RAG)
Through a new similarity comparison method (mse\_loss):
def mse_loss(query_embedding, document_embedding, adaptor_matrix, label):
return torch.nn.MSELoss()(model(query_embedding, document_embedding, adaptor_matrix), label)
In this way, find the best answer.
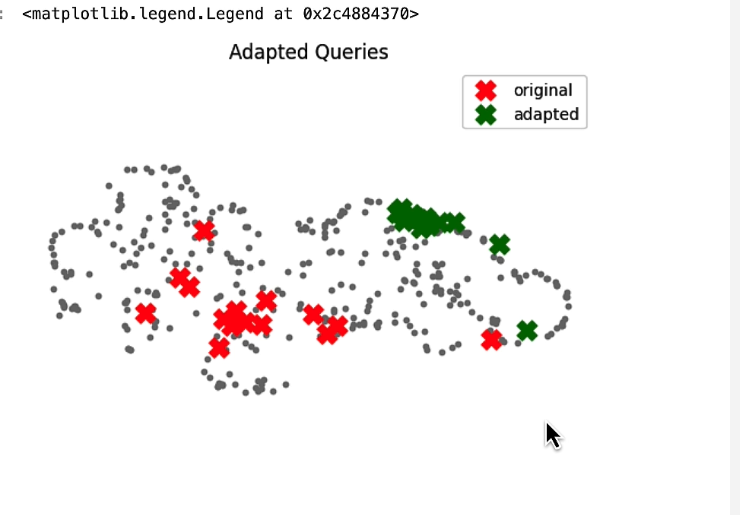
This image shows that the adapted query results are less likely to produce irrelevant answers. There is also a suggestion here that if you can get the user's data to use as an adapted question, it may make the answer better.
Derived thinking:
- When you find that the results are too irrelevant.
- Ask a few more questions, and then find related answers.
- Become a new dataset, as a query. This can optimize the entire RAG dataset, and thus get better answers.
## Course Summary:
- First, explain the traps that RAG often encounters. Questions that are too scattered cause similar answers to be irrelevant, and the replies will not be accurate.
- **Expanding Query**: Ask OpenAI to ask you a few more questions, and then put the questions and answers in to ask.
- **Cross Re-Rank**: This is an advanced version of the above, through generating the answers to the questions. Through a scoring mechanism. Find better answers and then go to RAG.
- **Embedding Adapter**: Generate more questions, and use the answers generated by the questions. Treat it as a new dataset, and then RAG.
# More References:
- [https://learn.deeplearning.ai/advanced-retrieval-for-ai/](https://learn.deeplearning.ai/advanced-retrieval-for-ai/)
- [The Tech Buffet #18: Advanced Retrieval Techniques for RAG](https://thetechbuffet.substack.com/p/advanced-retrieval-techniques-for-rag)
- [9 Effective Techniques To Boost Retrieval Augmented Generation](https://towardsdatascience.com/9-effective-techniques-to-boost-retrieval-augmented-generation-rag-systems-210ace375049)
- [The Tech Buffet #18: Advanced Retrieval Techniques for RAG](https://thetechbuffet.substack.com/p/advanced-retrieval-techniques-for-rag)

Top comments (1)
Some comments may only be visible to logged-in visitors. Sign in to view all comments.