In this article, I aim to present the concept of isolation levels in a straightforward way. While our examples primarily use MySQL, it's important to note that these principles are applicable across various databases.
Throughout the article, I’ll use following table as example
CREATE TABLE `posts` (
`id` int NOT NULL AUTO_INCREMENT,
`user_name` varchar(255) DEFAULT NULL,
`like_count` int DEFAULT NULL,
PRIMARY KEY (`id`)
)
+-----+-----------+------------+
| id | user_name | like_count |
+-----+-----------+------------+
| 1 | Alice | 10 |
| 2 | Bob | 5 |
| 3 | Charlie | 15 |
+-----+-----------+------------+
For each level, we'll discuss the specific concurrency problems, the issues each level resolves, and how MySQL implements these levels behind the scenes.
(I assume that you have basic understanding of relational databases and transaction concepts.)
Overview
Before getting into the detail of each isolation level, we may need to understand what exactly is isolation level at a high level. Let's take a break from thinking about databases and use transportation as an analogy instead.
Imagine an intersection with four different directions, and cars in each direction want to turn right, turn left, or go straight.

Regardless of the direction a car chooses, it must pass through the orange circle area. At any given time, only one car is allowed in the orange circle area, or else a car accident may occur.
The problem is how to design a policy that prevents car accidents while also avoiding traffic jams.
After a brief thinking, we may come up three potential policies.
-
Block one lane while letting the other three go through
This approach reduces the chances of traffic jams as three lanes remain functional. However, there's a high risk of accidents because it's hard to coordinate three different directions at once.
-
Block two lanes while letting the other two go through
Compared to the first policy, this lowers the risk of car accidents but increases the chance of traffic jams since two lanes are blocked.
-
Block three lanes while letting only one lane go through
This is probably the safest option because only one lane has cars, so accidents can't happen. However, it leads to significant traffic congestion issues.
From the above three different policies, what we’re doing?
We’re making a tradeoff between car accident and traffic jam. More generally, we’re making a tradeoff between “challenge of managing simultaneous access by multiple entities” and “efficiency”. And this is what isolation levels are about.
Each isolation level in databases makes a tradeoff between addressing database concurrency issues and ensuring efficiency. Opting for a higher isolation level resolves concurrency problems but may introduce inefficiencies, and vice versa.
Similar to our intersection example, there's no perfect correct policy as every situation is unique. It's the same for isolation levels - there's no universally correct level because every application uses databases differently.
Read Uncommitted
At the read uncommitted isolation level, a transaction is allowed to read data that has been modified but not yet committed by other transactions. In other words, it reads the latest version of a row, even if the change has not been committed yet.
Let's look at an example

- Transactions T1 and T2 each start their own transaction
- T1 updates the
like_amountcolumn to increment it by 1 for the row whereidis equal to 1 - T2 reads the same row, and output the latest changes by T1(10 → 11) which is not yet committed
This behavior may seem intuitive at first, but what happens if T1 rollback its changes?

In that case, T2 would have read the same row twice but received inconsistent results. The first read saw T1's uncommitted change, while the second read would see the original data after T1's rollback. This inconsistent read is known as a dirty read.
Dirty reads are a common phenomenon at the read uncommitted isolation level. In most cases, we want to prevent this from happening because it can lead to data inconsistency and integrity issues.
Read uncommitted is the lowest isolation level. Although it provides the best performance and concurrency, most databases do not use this as the default level because it causes too many concurrency problems. Dirty read is just one of the issues that can occur at this isolation level; we'll explore more of them throughout this article.
Read committed
At the read committed isolation level, a transaction can only read data that has been committed by other transactions. This means it accesses the latest committed version of a row, preventing dirty reads where uncommitted changes are visible.
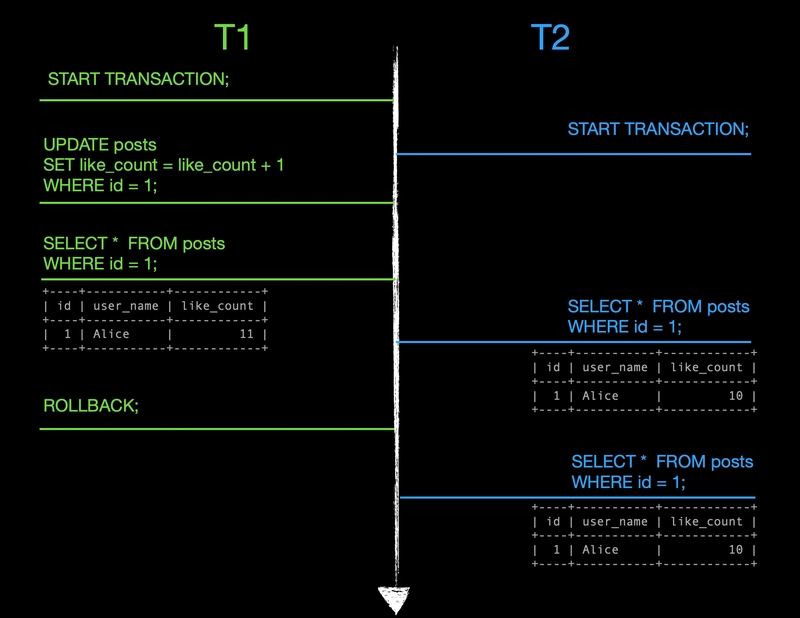
- Transactions T1 and T2 each start their own transaction
- T1 updates the
like_amountcolumn to increment it by 1 for the row whereidis equal to 1 - T1 reads the same row and sees the incremented
like_amountvalue, indicating the change has been made - T2 reads the row and gets the old value of 10 because T1's change is not yet committed
- T1 rollback its transactions
- T2 reads the same row again and still gets the value of 10.
The key difference from the read uncommitted example is that T2 only sees the latest committed data. When T2 first read the row, T1's change was uncommitted, so T2 saw the previous committed value of 10.
The biggest difference between read uncommitted and read committed is that read uncommitted reads the latest uncommitted or committed data, while read committed always reads the latest committed data.
However, what if T1 commits its change instead of rollback?

The only difference in this example is that T1 commit the changes.
In that case, when T2 reads the same row twice, it would get different results: 10 on the first read and 11 on the second read after T1's commit. This is known as a non-repeatable read.
Non-repeatable reads refers to the situation where a transaction reads the same row of data twice within the same transaction, but the data it reads changes between the two reads due to another concurrent transaction.
In addition to non-repeatable reads, another issue can occur: phantom reads.
A phantom read happens when a transaction retrieves a set of rows twice, but the number of rows changes between the two reads because another committed transaction has inserted or deleted rows from that set.
This is very similar to non-repeatable read. Both refer to the result being different even though it’s the same query within a transaction. In this case, a phantom read refers to the difference in the number of rows it returns.
This situation occurs because MySQL only locks the matched rows, not the entire set. Here's an example:
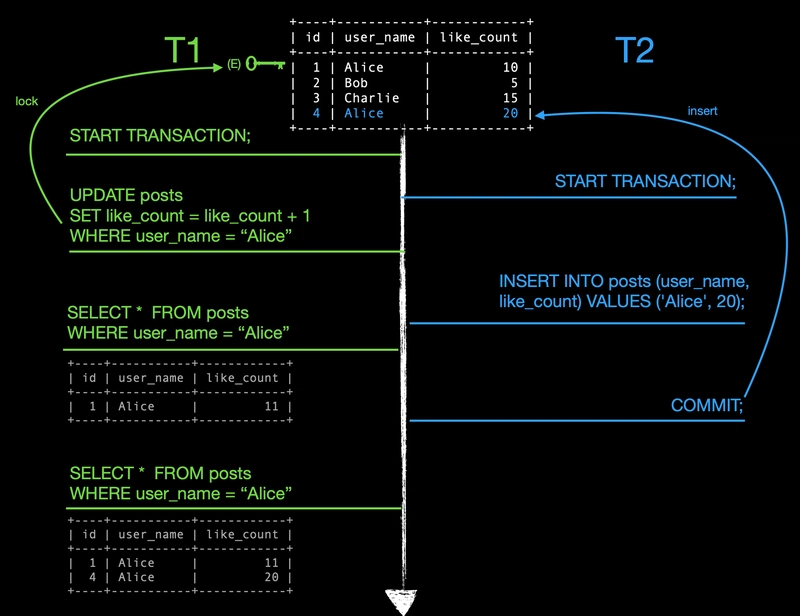
The topmost table represents the latest state of the table. It only updates after a transaction commits its own changes, which is why the new row is only inserted after T2 actually commits.
- Transactions T1 and T2 each start their own transaction
- T1 updates the
like_amountcolumn for the row whereuser_nameis "Alice"- During this operation, MySQL places an exclusive lock on the matched row.
- An exclusive lock prevents other transactions from acquiring a lock on the locked data.
- In this case, other transactions can’t acquire other types of lock on first row.
- T2 inserts a new row into the
poststable - T1 finds the rows where
user_nameis "Alice"- It only returns one row because T2 hasn’t committed yet.
- T2 commits its changes
- T1 runs the same query again, but now it returns two rows because T2's insert is visible
This is a phantom read: T1 executed the same query twice but got a different set of rows. We’ll explore how higher levels solve this problem.
Note that any problems occurring at a higher level also occur at a lower level, so non-repeatable read and phantom read also happen at the read uncommitted level.
One final thing we may miss: How does MySQL implement read committed?
To implement read committed, MySQL takes a snapshot of the database's current state for each query within a transaction. This snapshot represents the latest committed data at the time of the query, excluding any uncommitted changes.
When a transaction reads data, it accesses the snapshot instead of the source table. In the read committed level, a snapshot is refreshed and updated for subsequent queries within the same transaction.
Let’s see diagram to be more clear.

When T2 issues the read operation, a snapshot of the current state of the database is constructed, and T2 reads the result from this snapshot, not directly from the source table itself.
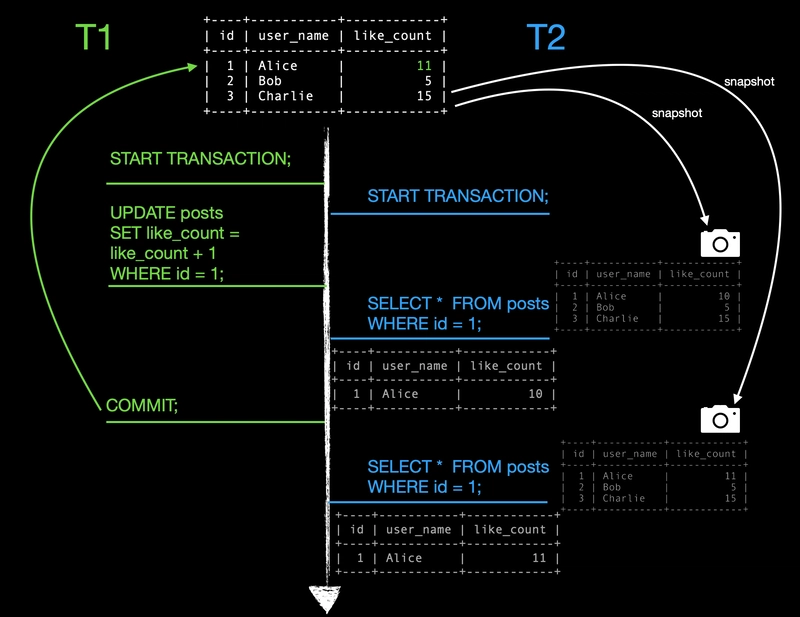
Once T1 commits its change, the source table finally gets updated to reflect T1's modification.
Now, when T2 makes the second read, the snapshot is refreshed and synchronized with the updated source table. T2 then reads the result from this refreshed snapshot.
It's important to note that for each query within a transaction at this isolation level, MySQL creates its own separate snapshot of the database.
While read committed successfully prevents dirty reads with good performance, it does not solve non-repeatable reads and phantom reads. Despite this, some databases, like PostgreSQL, use read committed as the default isolation level. However, this is not the case for MySQL.
Repeatable Read
The primary distinction between the committed read and the repeatable read lies in "when does snapshot refresh" and the "locking strategy."
Let's start with snapshot refreshing. In the repeatable read level, a snapshot is constructed by the first read. This snapshot is then used for all subsequent reads in that same transaction until it gets committed or rollback. Consequently, it ensures that each read query consistently returns the same result within the same transaction.
Let’s again see the diagram.

- Transactions T1 and T2 each start their own transaction
- T1 updates the
like_amountcolumn to increment it by 1 for the row whereidis equal to 1 - T2 reads the rows and gets an output of 10
- This is the first read operation within T2's transaction, so a snapshot is created.
- Since T1 hasn't committed its change yet when the snapshot was constructed, it still shows Alice's
like_countas 10.
- T1 commits its change and update the table
- T2 reads the same rows and still gets the output 10
- This is the key difference we mentioned earlier.
- Instead of refreshing the snapshot, the second read accesses the old snapshot (gray arrow). In the repeatable read level, a snapshot remains the same throughout a transaction.
This mechanism helps solve the problem of non-repeatable reads.
It's worth noting that issues resolved by lower isolation levels won't reoccur at higher levels, so we can guarantee that dirty reads won't happen in the repeatable read level either.
Now, let's talk about the locking strategy.
At the repeatable read level, MySQL locks more than just the matched rows when performing an update.

- Transactions T1 and T2 each start their own transaction
- T1 updates the
like_amountcolumn for the row whereuser_nameis "Alice"- Now, MySQL not only locks matched row but also locks all subsequent rows.
- In simpler terms, MySQL locks the rows from
id1 to infinity, preventing other transactions from inserting new rows. - Note that the three dots (...) don't represent actual values; they're just a simple representation to show that MySQL locks all subsequent rows.
- Adding an exclusive(X) lock on the rows prevents other transactions from acquiring any lock on those rows.
- T2 attempts to insert a new row into the
poststable- Because all rows are locked, T2 has to wait until T1 releases the lock before inserting new rows.
- T2 gets a lock wait timeout error
- After a few seconds, T2 receives the lock wait timeout error due to T1 hasn't released the lock within the allowed timeout period.
- The red error message indicates that a transaction is waiting for a lock to be released but exceeding the timeout period allowed for that lock.
- As long as T1 releases the lock before the lock wait timeout, T2 can successfully insert the new row.
Because MySQL uses a more rigorous locking strategy to lock subsequent rows, it prevents phantom reads from happening in the repeatable read level.
(For more information about locks in MySQL, you can check out here)
However, there's a caveat to the snapshot mechanism. It only applies to read operations. When performing updates, MySQL will look at the source table to find the matching rows, and then update them accordingly.

- Transactions T1 and T2 each start their own transaction
- T1 inserts a new row into table
- T2 reads the rows where
like_countis equal to or greater than 15 and matches one row - T1 commits its change, updating the source table
- T2 updates the rows where
like_countis equal to or greater than 15, and matches two rows- Surprisingly, the query response indicates "2 rows affected," which means that MySQL doesn't use the snapshot to match rows for updating.
- Instead, it reads from the source table to find the matching rows and updates them accordingly.
- T2 runs the same read query again but gets two rows, which is different from the first time
- Because T2 uses the source table to update rows, a new snapshot is re-created for subsequent reads.
From the above example, we can see that phantom reads may still occur in some edge cases, even at the repeatable read level. We should consider this pattern in our applications if it poses a potential issue. The only way to prevent phantom reads in every case is to use the serializable level, which we'll discuss in detail later.
There are still some issues in the repeatable read level, one of which is the lost update problem.
A lost update refers to a situation where two or more transactions concurrently read the same data, modify it based on the read data, and then finally write the modified data back to the database. Because neither transaction is aware of the modifications made by the other, the second change overwrites the first modification.
In most cases, the lost update occurs in a read-modify-write pattern.

- Transactions T1 and T2 each start their own transaction
- T1 checks Alice’s
like_count, which returns 10 - T2 also checks Alice’s
like_count, obtaining the same result of 10 - T1 updates the
like_countto 15 - T2 updates the
like_countto 20 - T1 commits its changes, resulting in the table value becoming 15 (green)
- T2 then commits its change, overwriting the previous value with 20 (blue)
As we can see, T1 and T2 are both trying to update the same row concurrently, and T2 overwrites the updated value made by T1.
One approach to mitigate this problem is by using atomic operations.
UPDATE posts SET like_count = like_count + 10 WHERE user_name = 'Alice';
Another approach is leveraging higher isolation levels to help us.
Repeatable read is the standard level in MySQL. Through its snapshot mechanism and locking strategy, it solves the issues such as non-repeatable reads and phantom reads. However, there are still unresolved issues.
Serializable
The overall idea behind the serializable level is that even though transactions may execute concurrently, MySQL ensures that the end result is the same as if they were executed serially (one after the other).
A key distinction of this level is its requirement for every read operation to acquire a shared lock on the data it accesses.

- Transactions T1 and T2 each start their own transaction
- T1 reads data, causing shared locks on all rows
- This behavior highlights why serializable is the strictest level.
- MySQL places shared locks on entire rows for a single select statement.
- T2 attempts to insert a new row into the "posts" table
- Because all the rows are locked, T2 has to wait until T1 releases the locks to insert new rows.
- T2 encounters a lock wait timeout error
- T2 performs an update on the row
- T2 encounters another lock wait timeout error
Because any read query acquires shared locks on rows, any write or update operations by other transactions will have to wait until the shared locks are released. This pattern prevents the problems we mentioned earlier, such as non-repeatable reads and phantom reads.
While serializable enhances data consistency, it also increase the possibility of deadlock.

- Transactions T1 and T2 each start their own transaction
- T1 reads the data, causing shared locks to be acquired on all the rows
- T2 also reads the data, causing shared locks to be acquired on all the rows
- Shared locks can be held simultaneously by multiple transactions.
- T1 attempts to update a row, waiting for T2 to release its shared lock
- T2 attempts to update the same row, waiting for T1's shared lock release
Both transactions are waiting for the other to release its shared lock so that an exclusive lock can be acquired to perform the update. This behavior is called a deadlock. Since neither transaction can actively release its shared lock, MySQL decides to throw an error immediately without waiting.
After T2 encounters the error, T1 successfully updates the row.
Although the serializable level successfully eliminates the problems that the repeatable read level cannot solve and prevents most database concurrency issues, its strict locking mechanism can significantly affect performance. Therefore, it's generally not the recommended default choice for most database applications.
Summary
In this article, we explored the concept of isolation levels in MySQL, which represent different approaches to managing concurrency and ensuring data consistency in a transactional environment. Each isolation level strikes a balance between addressing potential concurrency issues and maintaining optimal performance.
- Read Uncommitted
- The lowest isolation level allows transactions to read data that has been modified but not yet committed by other transactions.
- While offering the best performance, this level is generally not recommended due to the increased risk of encountering dirty reads and inconsistent data.
- Read Committed
- By utilizing a snapshot mechanism, this level ensures that transactions only read data that has been committed by other transactions, preventing dirty reads.
- The snapshot is constructed for each query within a transaction.
- However, it does not address non-repeatable reads and phantom reads, where the same query within a transaction may return different results due to concurrent modifications.
- Repeatable Read
- As the default isolation level in MySQL, this level addresses non-repeatable reads by creating a consistent snapshot of the data for each transaction.
- The snapshot is constructed during the initial read operation and remains consistent until the transaction is committed or rolled back.
- However, non-repeatable reads still may occur in some edge cases.
- It also employs a more rigorous locking strategy to prevent phantom reads. While resolving many concurrency issues, it may still encounter problems such as lost updates.
- Serializable
- The highest isolation level provides the strictest data consistency by enforcing a serial execution order for transactions.
- It acquires shared locks on all rows it accesses, effectively preventing lost updates, and other concurrency issues.
- However, this extensive locking mechanism can significantly impact performance and increase the likelihood of deadlocks.

Top comments (2)
amazing
🫡 my respect