
Do you know what is the easiest way to run AI models? It’s of course, using Docker.
Docker has added support for running AI models in Docker Desktop 4.40.0, and it’s sooo easy to get started — right now, this is only available on Mac with Apple Silicon. Soon, this will also be available on Windows.
Note: I got early access to the feature, and this will be soon GA.
How does the Model Runner work?
The Docker Model Runner doesn’t run in a container, and it uses a host-installed inference server (llama.cpp), that runs locally on your computer. In the future, Docker will support additional inference servers.
To break down how this works:
- You have a host-level process that allows direct access to the hardware GPU acceleration
- GPU acceleration is enabled via Apple’s Metal API during query processing.
- Models are cached locally in your host machine’s storage and are dynamically loaded into memory by llama.cpp when needed This means that your data never leaves your infrastructure.
Models are stored as OCI artifacts in Docker Hub, ensuring compatibility with other registries, including internal ones. This approach enables faster deployments, reduces disk usage, and improves UX by avoiding unnecessary compression.
How can you use the Model Runner?
To get started, first go to Docker Desktop, and under Settings select Features in Development, and ensure the Enable Docker Model Runner is toggled on.
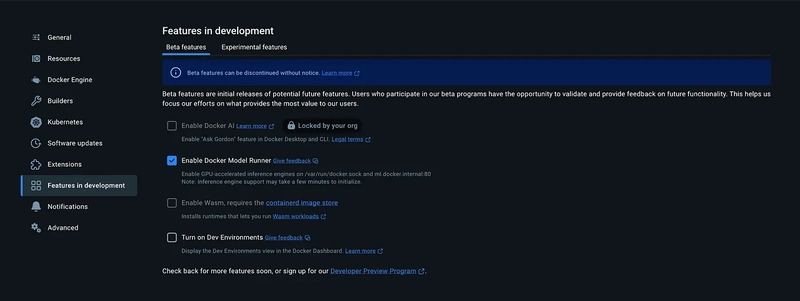
After you enable the feature, make sure you restart Docker Desktop.
To see if the model runner is up, you can simply run:
docker model status
Docker Model Runner is running
If you want to see what are the available models in Docker:
docker model list
{"object":"list","data":[]}
Of course, you haven’t pulled any model yet, the list is going to be empty, as it is in my case.
Right now, you can find a list of models here:
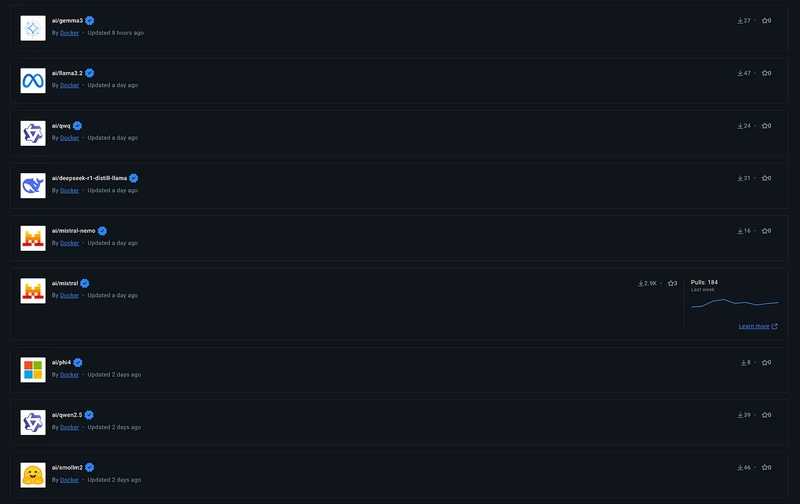
To pull a model, you can simply run:
docker model pull model_name
For this example, I will use ai/llama3.2.
docker model pull ai/llama3.2
Model ai/llama3.2 pulled successfully
We are now ready to run the model. You can do it either interactively, or just do a one-off command.
docker model run ai/llama3.2
Interactive chat mode started. Type '/bye' to exit.
> Hey how are you?
I'm just a language model, so I don't have feelings or emotions like
humans do, but I'm functioning properly and ready to help you
with any questions or tasks you may have!
How about you? How's your day going?
docker model run ai/llama3.2 "Hello"
Hello! How are you today? Is there something I can help you with, or would you like to chat?
Well, this is cool, but you want to take it to the next level and use it in your apps, right?
You can connect to the model in three ways:
- From the container by using the internal DNS name: http://model-runner.docker.internal/
- From the host using the Docker Socket
- From the host using TCP
Another great thing is that the API offers Open-AI compatible endpoints:
GET /engines/{backend}/v1/models
GET /engines/{backend}/v1/models/{namespace}/{name}
POST /engines/{backend}/v1/chat/completions
POST /engines/{backend}/v1/completions
POST /engines/{backend}/v1/embeddings
Wrap-up
Docker Model Runner makes running AI models ridiculously simple. With just a few commands, you can pull, run, and integrate models into your applications — all while keeping everything local and secure.
This is just the beginning — as Docker expands support to Windows and additional inference servers, the experience will only get better.
Stay tuned, and keep building 🐳

Top comments (0)