Hey Guys, Today I will tell you how you can scrape a website using PHP language. To scrape a website using PHP you need to include simple_html_dom.php file in your PHP file. This file contains predefined functions to parse the html website or to search through the tags of that site. Keep in mind Scraping a website without the site’s permission can be considered illegal.
*This post is just for Educational Purpose.
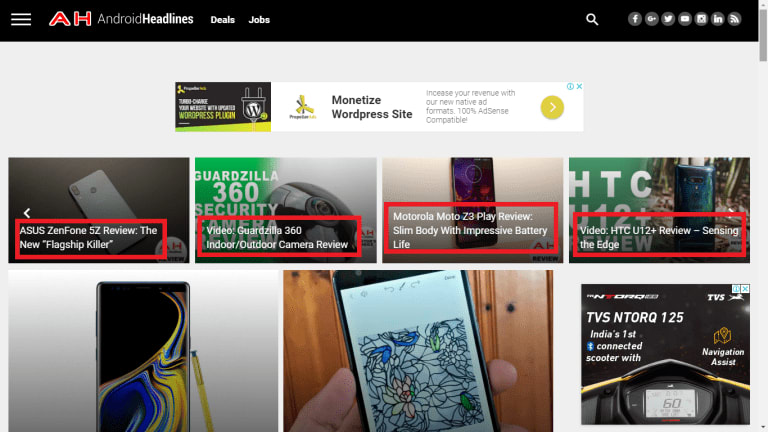
First choose the website and the data on it which you want to Scrape. Here I am taking the example of AndroidHeadlines.com site. From it we are going to scrape the Latest Headlines.
Step 1 : First you need to start the PHP tags–
Step 2 : Second include the simple_html_dom file in your PHP code and place that file into the same folder –
Step 3 : Now create a variable which will contain a method named as file_get_html (this method will create the Document Object Model for the URL provided by the user inside it’s parenthesis) –
Step 4 : Now by using the variable $html, we can find the site’s tag. So let’s find the tag which contains all the latest posts. For finding the tag inside the $html variable we will use find() function –

Step 5 : As we only want to scrape the title of the headline and there being multiple headlines, we need to create an array to store all these headlines –
Step 6 : Now we are going to find the tag which contains the title of the headline. As you can see the span tag contains the title. So, just scrape it and don’t write any index at the end. Now we can directly save it to our titles array –

Step 7 : Now to print the array titles use foreach or any other loop –
Step 8 : Finally, You’ll obtain the scraped data as output in the following manner –

I hope now you know how to actually scrape data from a website. Feel free to ask any question.
Don't forget to visit my blog to get more posts like this ganofins.com

Top comments (2)
This blog provides a clear and concise guide on scraping websites using PHP, with a helpful step-by-step approach. It's a great resource for those looking to learn web scraping techniques. If you need further assistance, don't hesitate to ask. Also, check out Crawlbase for more advanced scraping solutions.
Hi, I am maintaining a modern fork of "simple_html_dom" for PHP, maybe you will like it. :)
-> github.com/voku/simple_html_dom