
There is a new way to jump over Cloudflare anti-bot detection with a new web scraping service: antidetect browsers.
If you google “Cloudflare bypass”, you will find hundreds of articles and Github repositories explaining how to bypass Cloudflare (or sell a solution for doing it). The reason is pretty straightforward: Cloudflare Bot Management solution is one of the strongest and most used anti-bot protection used on the internet.
Is It That Difficult?
– Yes.
Traditional security measures rely on IP blocking or CAPTCHAs. The Cloudflare’s Bot Management solution uses advanced machine learning algorithms to analyze requests coming to website. So, it’s able to naturally identify bots by interpreting their typical behavior patterns.
Here are some examples of what bots are very likely to do:
- make a large number of requests in a short period of time
- use a specific type of user agent or IP address
- have inconsistent/suspicious fingerprints.
Cloudflare’s Bot Management solution is also hard to bypass because it’s constantly taught to detect new types of web scraping bots. The company uses machine learning algorithms to update its detection methods to quickly identify and block new types of bots as they appear.

Another stumbling point with Cloudflare is it being a highly customized solution. Methods that work for one website are likely to be useless for another one.
As proof of this, in my previous post about Cloudflare, I wrote three similar solutions for 3 different websites, but only two of them still work. During the past weeks, I’ve struggled to use Playwright with the Antonioli website to bypass Cloudflare. After a few pages I was blocked again, especially when the execution was running inside a VM on AWS.
So, the truth is – there’s no silver bullet against Cloudflare Bot Management. However, there are solutions that work well.
A New Approach: Antidetect Browsers As Web Scraping Service
I’ve tried working with Playwright in different browsers and contexts, as well as on several cloud providers – no success whatsoever. So, I decided to give Playwright a try in an antidetect browser.
What Are Antidetect Browsers?
Antidetect browsers are usually based on Chromium, but with features that enhance user privacy. Typically they create new fingerprints that look authentic to websites, protecting real location of the user. This is the key difference from a classic Playwright or Selenium execution.
I’ll put it in more simple words. Using Playwright under Chrome, the server knows you’re using a genuine version of Chrome, but from a Datacenter machine – because of its device fingerprint. With an antidetect browser, you’re using a version of Chromium set up for maximum privacy.
It sets up a sophisticated connection profile that sends custom device fingerprints. So, even the most advanced website engines see you’re running the browser from a regular Mac while it’s actually running from a server. Thus, your work is protected.
GoLogin
I needed to test if this solution could work. Between the several browsers available, I had to choose one with the following specs:
- Has a fully working free demo to test my solution
- Can quickly be integrated with Playwright, minimizing the impact on my production environment
- Has a Unix client for my production environment.
Given that, technically, any chromium-based browser could run with Playwright if the executable_path is specified in the following way
browser = playwrights.chromium.launch(executable_path='/opt/path_to_bin')
I’ve chosen GoLogin web scraping service because of all the features above and for the fact that I could create different profiles (each under different fingerprints), which I could use for my experiments.
The Configuration
After signing up, I created my first profile that mimics a Windows workstation. Then I downloaded the browser’s client and the python source code from their repository, which is needed for interacting with Playwright using their API.
Using the tests on amiunique.org we can see the differences between the Playwright standard execution of Chrome from my Mac laptop and the one with a custom profile of a windows machine using GoLogin browser.
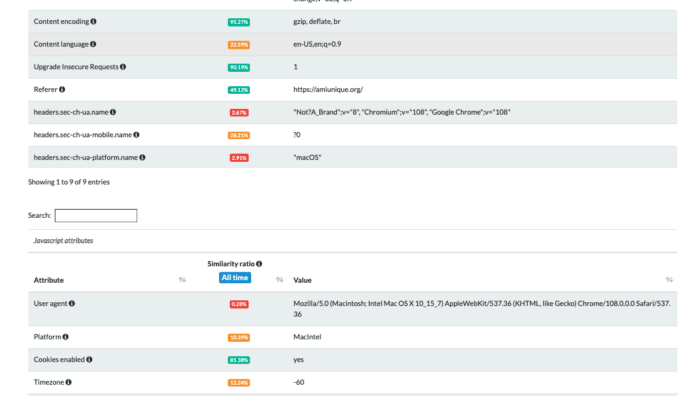
In the first case, we can see the Macintel platform and the macOS headers, which could be easily changed anyway.
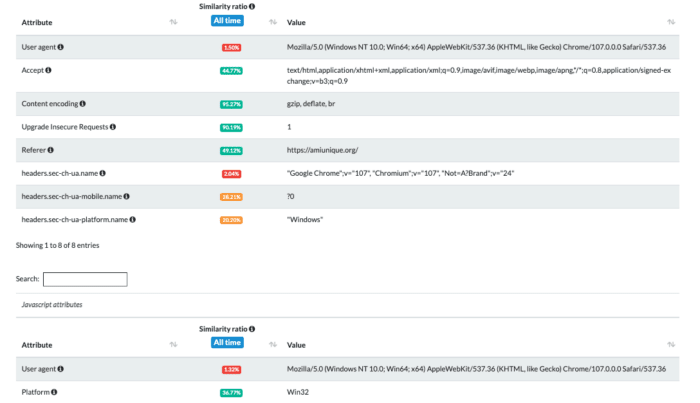
Using Gologin instead, I am imitating the execution from a Windows machine. Of course, the differences are much more than those I screenshotted. You can easily check them by yourself using the code I’ve shared in The Web Scraping Club Github repository reserved for paying readers.
Download GoLogin here and scrape freely - with our free plan!
This article was kindly provided by Pierluigi Vinciguerra, web scraping expert and founder of Web Scraping Club. Follow this link to see the original post.

Top comments (1)
In my work, I often encounter tasks where I need to bypass various protection systems, including Cloudflare. One of the key tools that helps me with this is the anti-detect browser. I use a browser from masqad.com, which provides the necessary tools to bypass such protections and allows you to remain unnoticed. This browser copes well with tasks that require high anonymity and flexibility in settings, which is especially important when working with web scraping.
Some comments may only be visible to logged-in visitors. Sign in to view all comments.