Partition collections using the C# MongoDB driver with Azure Cosmos DB.
Azure Cosmos DB is a fully managed NoSQL database. I’ve written about it extensively on this blog. An advanced and powerful feature is the ability to partition data. This is commonly referred to as sharding. Azure Cosmos DB manages this for you when you follow these prerequisites for partitioning.
I won’t go into too much detail about partitioning here because it’s well-explained in the documentation. In a nutshell, a logical partition is a range of items that are grouped together. This is determined by a property on the documents that may be either hashed or specified as a range. Logically, items with the same partition key are kept together. Physically, a node may store one to many partitions or shards. This is handled transparently for you by Azure Cosmos DB based on demand.
Read everything there is to know about partitioning here: Partitioning and scale in Azure Cosmos DB
Partition keys help with scale, especially when your database is geographically distributed. This is because when items are inserted or updated, replication can focus on that specific partition rather than the entire database. Reads can also be optimized by co-locating partitions for those reads. The replication behavior is optimized by setting a specific consistency level.
Although the documentation discusses how partitioning works across various APIs (for an overview of the different APIs and database “flavors” that are available, read this overview of Azure Cosmos DB APIs), there wasn’t an explicit example of how to set the partition key through code.
I started with my existing USDA Database example. This contains almost 9,000 food items that are assigned to a particular “food group.” There are many best practices for choosing a partition key. To keep this example simple, I chose to partition on the FoodGroupId property.
The code to create a collection in MongoDB looks like this:
To specify a partition key, we have to create a sharded collection. This is done by passing a command to the database. MongoDB commands and queries are all JSON documents, so we can use the driver’s BsonDocument class to construct the command. This is the command to create a sharded collection:
The collection name is passed as a fully qualified database and collection name, followed by the key for the shard that points to a hash of FoodGroupId. The document is used to construct the command and is then passed to the database.
After the data is inserted, you can view the distribution of storage across partition keys in the portal.

You can see there are a few outliers with more storage but in general the storage is evenly distributed. You specify the partition key to create a logical partition that guarantees to keep items with the same hash of the key together. Cosmos DB manages the physical partitions based on needs. In the portal, you can see that although we have a few dozen partition keys, there are only a handful of partitions.

The partitions are sequenced. I highlighted “partition 3” that is holding 40 megabytes of data. Clicking on the partition reveals the logical keys that it contains.

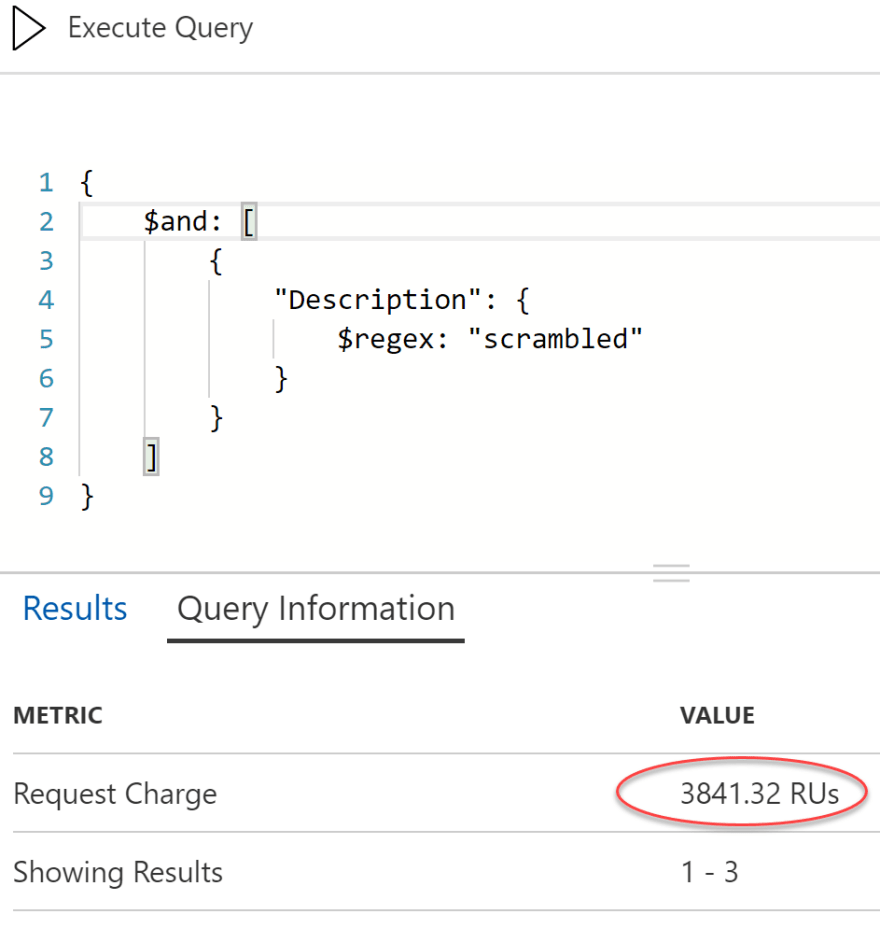
Every document in the collection must have the partition key or an error is thrown when you try to insert or update it. To see how partitioning works from a performance and cost perspective, I first ran a search for the text “scrambled” across the entire database (multiple physical and logical partitions).
If you are confused by the JSON syntax I use for MongoDB queries, you can read more about it and how it relates to SQL syntax here: MongoDB query documents.
A request unit represents a fixed amount of memory, storage, and CPU required to complete an operation. Here, we are at almost 4,000 RUs for the query to run. The query had to scan every item and apply the regular expression. Let’s narrow it down to the two unique food groups that were returned. This query will span two logical partitions, and just happens to span two physical partitions (0100 is on a different partition than 2100).

The filter reduced the RUs significantly, but this is mainly because the query engine is taking advantage of built-in indexes to narrow the subset of items to scan. If we limit the query to a single partition (both logical and physical), performance again improves dramatically:

The performance advantage isn’t solely due to the limited records to scan. We can limit the records to the exact same subset using a different column that is not the partition key (the group description, instead of it’s unique identifier), and the RUs will increase because it is not constrained to a single partition:
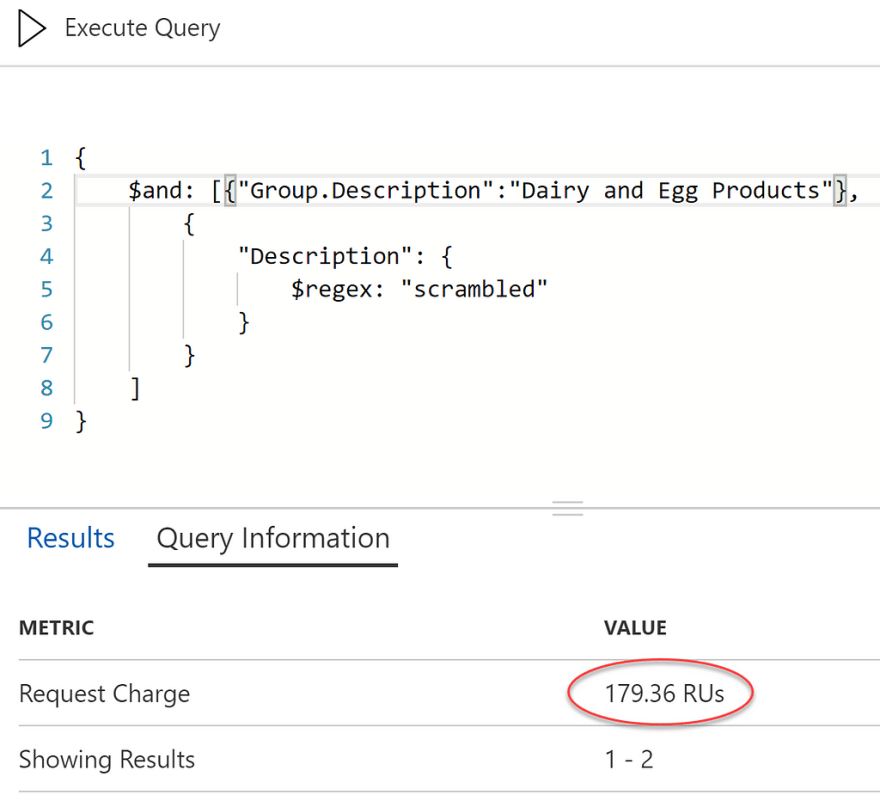
The increase is not as dramatic for megabytes of data but would be more evident when dealing with terabytes and petabytes of data.
If you are moving to Azure Cosmos DB from MongoDB or simply interested in using the MongoDB API, you now know how to take advantage of partition keys for replication at scale with Azure Cosmos DB. The concept is similar for other APIs but the implementations vary.
Ready to get started with the MongoDB API? Read the introduction to Azure Cosmos DB with the MongoDB API.
Regards,

Top comments (0)