Imagine finding a DBMS that aligns with tech goals of your organization. Pretty exciting, right?
Relational databases held the lead for quite a time. Choices were quite obvious: MySQL, Oracle or MS SQL, to mention a few. Though times have changed pretty much with the demand for more diversity and scalability, haven't they?
There are many alternatives in the market to choose from, though I don’t want you to get all confused again. So how about a faceoff between two dominant solutions that are close in popularity?
Both of these are some of the most popular open-source database software.
On that note, let’s get started.
Flexibility of Schema
One of the best things about MongoDB is that there are no restrictions on schema design. You can just drop a couple of documents within a collection and it isn’t necessary to have any relations between those documents. The only restriction with this is supported data structures.
But due to the absence of joins and transactions (which we will discuss later), you need to frequently optimize your schema based on how the application will be accessing the data.
Before you can store anything in MySQL, you need to clearly define tables and columns, and every row in the table should have the same column.
And because of this, there isn’t much space for flexibility in the manner of storing data if you follow normalization.
For example, if you run a bank, its information can be added to the table named ‘account’ as follows:
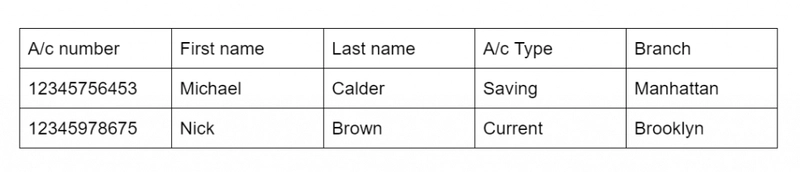
This is how MySQL stores the data. As you can see, the table design is quite rigid and it is not easily changeable. MongoDB stores the data in the JSON type manner as described below:

Such documents can be stored in a collection as well.
MongoDB creates schemaless documents which can store any information you want though it may cause problems with data consistency. MySQL creates a strict schema-template and hence it is bound to make mistakes.
Querying Language
MongoDB uses an unstructured query language. To build a query in JSON documents, you need to specify a document with properties you wish the results to match.
It is typically executed using a very rich set of operators that are linked to each other using JSON. MongoDB treats each property as having an implicit boolean AND. It natively supports boolean OR queries, but you must use a special operator ($or) to achieve it.
MySQL uses the structured query language SQL to communicate with the database. Despite its simplicity, it is indeed a very powerful language which consists mainly of two parts: data definition language (DDL) and data manipulation language (DML).
Let’s have a quick comparison.

Relationships in MongoDB and MySQL
MongoDB doesn’t support JOIN — at least, it has no equivalent. On the contrary, it supports multi-dimensional data types such as arrays and even other documents. The placement of one document inside another is known as embedding.
One of the best parts about MySQL is the JOIN operations. To put it in simple terms, JOIN makes the relational database relational. JOIN allows the user to link data from two or more tables in a single query with the help of single SELECT command.
For example, we can easily obtain related data in multiple tables using a single SQL statement.
This should provide you with an account number, first name, and the respective branch.
Performance and Speed
One single main benefit it has over MySQL is its ability to handle large unstructured data. It is magically faster because it allows users to query in a different manner that is more sensitive to workload.
Developers note that MySQL is quite slower in comparison to MongoDB when it comes to dealing with large databases. It is unable to cope with large and unstructured amounts of data.
As such, there is no “standard” benchmark that can help you with the best database to use for your needs. Only your demands, your data, and infrastructure can tell you what you need to know.
Let’s look at a general example to understand the speed of MySQL and MongoDB in accordance with various functions.
Measurements have been performed in the following cases:
MySQL 5.7.9
MongoDB 3.2.0
Each of these has been tested on a separate m4.xlarge Amazon instance with Ubuntu 14.4 x64 and default configurations; all tests were performed for 1,000,000 records.
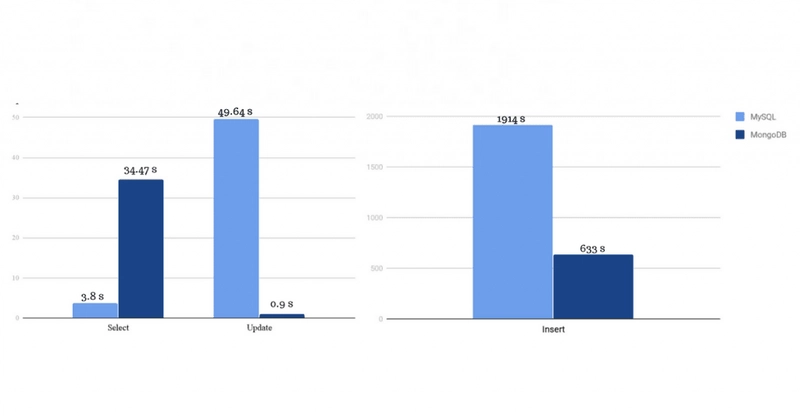
It is evident from the above graph that MongoDB takes way more lesser time than MySQL for same commands.
Security Model
MongoDB uses a role-based access control with a flexible set of privileges. Its security features include authentication, auditing, and authorization.
Moreover, it is also possible to use Transport Layer Security (TLS) and Secure Sockets Layer (SSL) for encryption purposes. This ensures that it is only accessible and readable by the intended client.
MySQL uses a privilege-based security model. This means it authenticates a user and facilitates it with user privileges on a particular database such as CREATE, SELECT, INSERT, UPDATE, and so on.
But it fails to explain why a given user is denied specific access. On the transport layer, it uses encrypted connections between clients and the server using SSL.
When to Use MongoDB or MySQL? This infographic explains when you'd use MongoDB over MySQL and vice versa.

Conclusion
To answer the question, “Why I should use X over Y?” you need to take into consideration your project goals and many other things.
MySQL is highly organized for its flexibility, high performance, reliable data protection, and ease of managing data. Proper data indexing can resolve your issue with performance, facilitate interaction and ensure robustness.
But if your data is not structured and complex to handle, or if predefining your schema is not coming easy for you, you should better opt for MongoDB. What’s more, if you're required to handle a large volume of data and store it as documents, MongoDB will help you a lot!
The result of the faceoff: One isn’t necessarily better than the other. MongoDB and MySQL both serve in different niches.
We have published an updated version of this post here MongoDB vs MySQL: A Comparative Study on Databases. If you've more suggestions up your sleeve, kindly comment.

Top comments (18)
Can we have your queries, not just a invalid bench without data ?
Also note, not tuning a SQL engine and comparing with MongoDB which doesn't require real tuning is not valid, you need to tune the MySQL/PostgreSQL buffer for reading & writing performance, especially on a such AWS instance which has many RAM.
PostgreSQL isn't benched and is far far more better than MySQL & PostgreSQL in terms of features, robustness and security (yes PostgreSQL has IPv6, enabled SSL by default without being crazy & CRAM authentication).
PostgreSQL json backend is faster than MongoDB for unrelational data, see enterprisedb.com/node/3441
Another point, there is no transactions with NoSQL, especially mongodb, your data can be totally broken, and the upgrade scheme after using a NoSQL during years, which moving data scheme can make your apps crazy, because you have to handle all cases, or suffer from crazy bugs.
We also compared PostgreSQL 9.6 with MongoDB 3.2 to bench new huge application we developped for production (~15 SQL hard relational tables with big constraints) and the performance/CPU cost is 1.5 lower using PostgreSQL mixed relational & JSON backend than MongoDB.
Last, a reality we see in our production, MongoDB is not safe, it doesn't ensure data is correctly written, and some data can be lost on huge workload whereas relational data really ensure data is here. The mongodb replication is not really safe, it's the major risk factor.
That is an interesting comparison of NoSQL databases.
I don't understand though, both of them have quite flaky but existing nonetheless JOIN implementations. MySQL has SQL-inspired
JOINclauses while MongoDB has$lookup, right?Yes, Mongodb has a join since 3.2, but do not take it lightly, it's not a 1:1 replacement. The feature is part of the aggregation framework, you will not want to aggregate data for each user request, it's not meant to be used like this because it needs more resources to return the result.
To avoid these you usually make subdocuments and keep the data in a single big object so you do not require a join.
If your data can be easily put in an excel like table then you shortly use a relationship DB.
My motto is: if you can put it in a table then put it in PostgreSQL. If you can't, then put it in PostgreSQL anyways, it has indexed JSON fields after all.
I guess my line would be to 'if you can put it in NoSQL then do that' and I come from SQL and Oracle.
Interesting to know that
$lookupis heavy though, I did use it without noticing performance issues but that's still something to consider.The lookup alone I don't think adds roo much, but usually you need other ops.
And try the test on a large db, eventually with sharding then you'll see the out of memory issue 😀
largeremains to be defined but yup I see the idea"To avoid these you usually make subdocuments and keep the data in a single big object so you do not require a join. "
That's a sure-fire way to make your database unusable down the road.
A nice article as an intro but ...
Readers, keep in mind you should ignore the VS compares,they are not 2 excluding or replacing technologies, they are usually used in the same project for different data types. Other storages are keyvalue like redis, object storage like Amazon S3, file storage and Graph databases. Other times you'll need the entire history and use an event sourcing DB.
Do not try to squeeze all your requirement into a single bucket, use them all if needed,based on each system module needs.
As for large databases I suggest to read about the new cloud dbs like
They're very different kinds of storage system -- I think the bottom line on these things is that if you're relying on simple X vs Y guidance to choose your storage layer then you're honestly not competent to make the choice.
Almost 47 seconds in query sounds pretty much for me in comparation with 4 secs from MySql. In a operational system maybe it worths a try Mongo but for informational systems, when you have much more than 1MM of registers it really is a bad idea to choose MongoDB.
Nice post, I recently hosted a meetup on SpringBoot and MongoDB where I discussed similar arguments.
In it I touch topics like Comparison with SQL, Schema Design, Performance improvements & GeoSpatial indexes/queries. It is based on M101J from MongoDB University.
Give it a look here: slides.com/tonnoz/bloggo
It includes exercises on Github too. It may be a good start point for who used Mongo superficially or only with ODM.
When choosing from MongoDB vs MySQL, it ultimately depends on your project's needs:
MySQL is ideal for structured data, where schema consistency and relationships are critical. It's reliable, with robust performance, and is great for complex queries and transactions.
MongoDB excels with unstructured or semi-structured data, offering flexibility in schema design. It's better suited for handling large volumes of data and allows for faster development when the data structure isn't rigid.
Both have their strengths, so your choice should align with your data's structure and your scalability requirements.
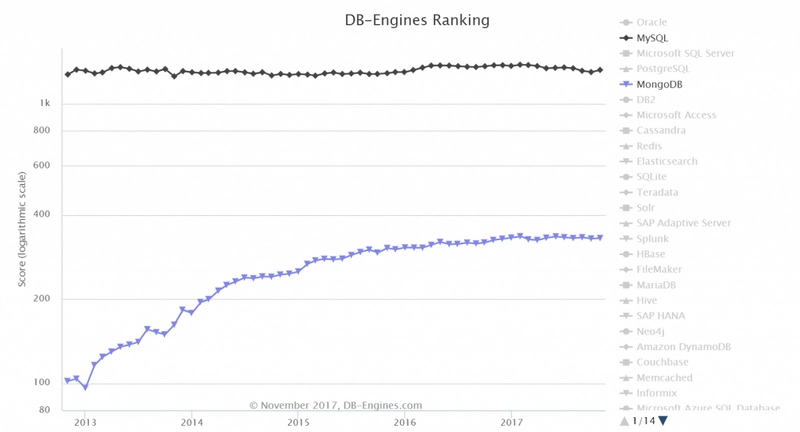
I'm concerned by the misleading chart used in the header. The rankings are given in logarithmic scale, for some reason, making Mongo's adoption seem closer to MySQL's than it really is.
MySql query is still much faster than MongoDB
Not even close. Lots of benchmarks on google show Mongo hugely faster than MySql in both queries and inserts, unless you're using simplistic myisam. Here's one:
github.com/webcaetano/mongo-mysql
Thx !