
If you have used any SPA framework like React or Vue, you might be familiar with the term "Virtual DOM." Whenever the route path or state changes in React, instead of rendering the whole page, React only renders the changes. To accomplish this, React uses a DOM diffing algorithm that compares the Virtual DOM to the actual DOM. In this article, I'm going to explain the Virtual DOM and show you how to implement the DOM diffing algorithm.
What is the DOM?
DOM stands for Document Object Model. It is a structured representation of HTML elements on a web page, where each element is a node object containing specific methods and properties.
You can inspect the properties and methods of nodes by running:
console.log(document.body.children);
What is the Virtual DOM?
The Virtual DOM is a virtual representation of the UI stored in JavaScript memory. It acts as a blueprint of the actual DOM. When changes are made to the Virtual DOM, they are compared to the actual DOM, and only the necessary updates are applied. This process prevents unnecessary re-rendering and improves performance.
Implementation
Before diving into the code, we need to understand nodes, node types, and child nodes.
A node is an object that represents an HTML element. To determine the node type of an element, run:
console.log(document.getElementById('node').nodeType);
For this project, we need to understand three main node types:
-
nodeType 1indicates an HTML tag. -
nodeType 3represents a text node. -
nodeType 8denotes a comment.
Child nodes are the children of a node. You can get the child nodes of an element using:
console.log(document.getElementById('node').childNodes);
However, using console.log(document.getElementById('node').children); will exclude text and comment nodes.
Let's create a function that returns the tag name if the node is an HTML element or the node type otherwise:
function getNodeType(node) {
if (node.nodeType === 1) return node.tagName.toLowerCase();
return node.nodeType;
}
Now, let's start by creating an HTML div with some child elements:
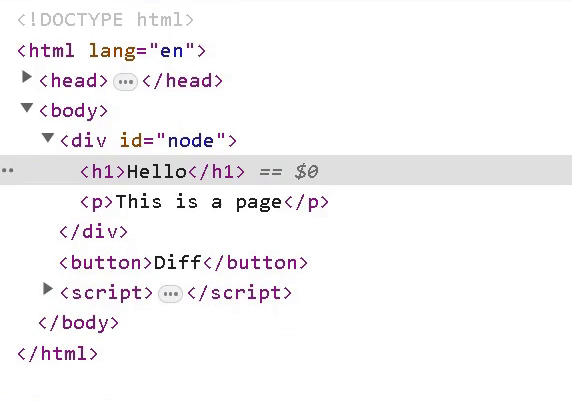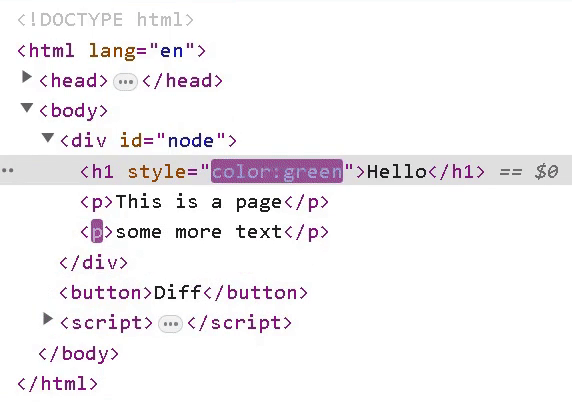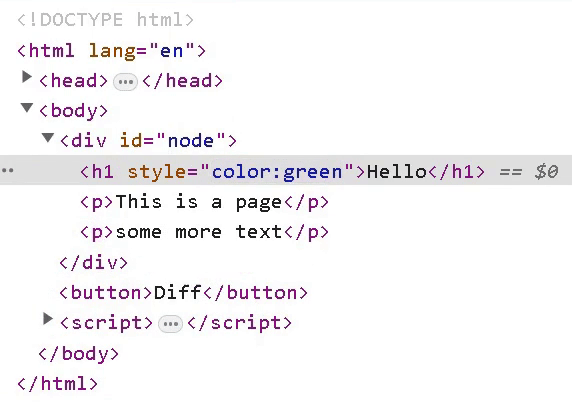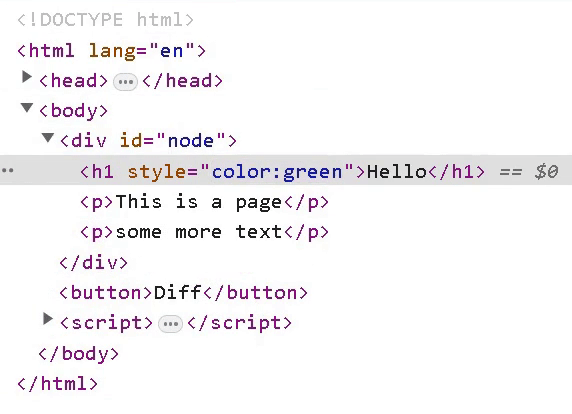
<div id="node">
<h1>Hello</h1>
<p>This is a page</p>
</div>
This div contains two child nodes (h1 and p), and each has a text node as a child.
If we want to replace the child nodes of <div id="node"></div> with:
<h1 style="color:green">Hello</h1>
<p>This is a page</p>
<p>Some more text</p>
We need to add a style attribute to the h1 tag and append <p>Some more text</p>.
To achieve this using a DOM diffing algorithm, we first need a function that converts an HTML string into actual elements. We can use the built-in DOMParser class:
function parseHTML(str) {
let parser = new DOMParser();
let doc = parser.parseFromString(str, 'text/html');
return doc.body;
}
var vdom = parseHTML(`
<h1 style="color:green">Hello</h1>
<p>This is a page</p>
<p>Some more text</p>
`);
Running console.log(vdom) returns a body element containing our template as HTML.
However, console.log(vdom.childNodes) includes unnecessary text nodes containing only new lines and spaces. These could cause problems during diffing, so we need to remove them. Here's how:
function clean(node) {
for (var n = 0; n < node.childNodes.length; n++) {
var child = node.childNodes[n];
if (
child.nodeType === 8 ||
(child.nodeType === 3 && !/\S/.test(child.nodeValue) && child.nodeValue.includes('\n'))
) {
node.removeChild(child);
n--;
} else if (child.nodeType === 1) {
clean(child);
}
}
}
Now, let's combine this with our parseHTML function:
function parseHTML(str) {
let parser = new DOMParser();
let doc = parser.parseFromString(str, 'text/html');
clean(doc.body);
return doc.body;
}
This gives us a clean Virtual DOM. Now, we define our actual diffing function:
function diff(vdom, dom) {
if (!dom.hasChildNodes() && vdom.hasChildNodes()) {
for (var i = 0; i < vdom.childNodes.length; i++) {
dom.append(vdom.childNodes[i].cloneNode(true));
}
} else {
if (vdom.isEqualNode(dom)) return;
if (dom.childNodes.length > vdom.childNodes.length) {
let count = dom.childNodes.length - vdom.childNodes.length;
for (; count > 0; count--) {
dom.childNodes[dom.childNodes.length - count].remove();
}
}
for (var i = 0; i < vdom.childNodes.length; i++) {
if (!dom.childNodes[i]) {
dom.append(vdom.childNodes[i].cloneNode(true));
} else if (getNodeType(vdom.childNodes[i]) !== getNodeType(dom.childNodes[i])) {
dom.childNodes[i].replaceWith(vdom.childNodes[i].cloneNode(true));
} else {
if (vdom.childNodes[i].nodeType === 3 && vdom.childNodes[i].textContent !== dom.childNodes[i].textContent) {
dom.childNodes[i].textContent = vdom.childNodes[i].textContent;
} else {
patchAttributes(vdom.childNodes[i], dom.childNodes[i]);
}
}
if (vdom.childNodes[i].nodeType !== 3) {
diff(vdom.childNodes[i], dom.childNodes[i]);
}
}
}
}
Patching Attributes
We need a function to compare and update attributes:
function patchAttributes(vdom, dom) {
let vdomAttributes = Object.fromEntries([...vdom.attributes].map(attr => [attr.name, attr.value]));
let domAttributes = Object.fromEntries([...dom.attributes].map(attr => [attr.name, attr.value]));
Object.keys(vdomAttributes).forEach(key => {
if (dom.getAttribute(key) !== vdomAttributes[key]) {
dom.setAttribute(key, vdomAttributes[key]);
}
});
Object.keys(domAttributes).forEach(key => {
if (!vdom.hasAttribute(key)) {
dom.removeAttribute(key);
}
});
}
Finally, let's trigger our diffing function:
let dom = document.getElementById('node');
clean(dom);
let vdom = parseHTML(`<h1 style="color:green">Hello</h1><p>This is a page</p><p>Some more text</p>`);
document.querySelector('button').addEventListener('click', function() {
diff(vdom, dom);
});
The Result
If you are interested in similar posts, check out my blog. Read next: Adding keys to our DOM diffing algorithm.

Top comments (12)
Removing text nodes containing all spaces means that the following markup:
will resolve to
this will lookwrong. There are a few edge cases around space in JSX.
Thank you for pointing out. I will condition this to not remove those spaces, as soon as I'm free I'm going to fix this . I will let you know. As for a quick solution html space character will do the thing for now
A JSX compiler is more difficult than it should be, given the specs. Good luck to you.
I have fixed this by conditioning it to remove only textNode that contains just newlines and spaces. Thank you very much for noticing the issue.
hey Joy, great article so just what was this issue and how you fixed it like is the blog updated with the fix of this issue and if yes can you please explain what the issue was and how it was solved coz i am also confused with extra text nodes added by Element.childNodes and it may break the code if not handled
Thank you for your comment Rishabh.
The issue was that the code was unintentionally removing text nodes that contained only spaces. The goal was to remove unnecessary new lines from the parsed HTML while keeping important space intact.
and this was the solution that was added .
Let's break down the condition step by step:
child.nodeType === 3: nodeType is a property of a DOM node that represents the type of the node. The value 3 corresponds to a text node. So, this part of the condition checks if the child node is a text node.
!/\S/.test(child.nodeValue): \S is a regular expression pattern that matches any non-whitespace character. The test() method checks if the child.nodeValue (the text content of the node) does not contain any non-whitespace characters. In other words, it checks if the text node is empty or contains only whitespace characters.
child.nodeValue.includes('\n'): This part checks if the child.nodeValue (the text content of the node) includes a newline character ('\n'). It checks if the text node contains a line break.
Putting it all together, the condition checks if the child node is a text node, is empty or contains only whitespace characters, and includes a line break. This condition is typically used to identify and handle empty text nodes that might contain only whitespace or line breaks, ensuring they are not treated as significant content in the dom.
Great thank you
Thank you for your feedback ☺️
10/10 post, kudos! 😁
Thanks 😊
This is a great explanation. My main question remains, will adding this virtual dom diffing code to my project actually make the DOM update faster? How can we measure this?
Thanks for your comment.
DOM diffing is not faster than simply getting one element via getElementById and changing it. But If you think of large number of elements or a complex tree then changing some part of that tree rather than recreating the whole tree is definitely faster. Think of a clock application, for everytime the clock updates instead of changing the whole body we can just change a small textNode(representing the time).The less we change the real DOM, the better . But for small changes the innerHTML can be faster .
However the virtual DOM may not be perfect for your project . You can look into this (by svelte ) article to know why.
For the second question though it's not the ideal solution but you can try this to measure performance of your JavaScript code
I recommend you to try svelte for your project . it complies everything down to pure minified JS and doesn't require any virtual DOM, doesn't get faster than this