
If TDD is Zen, adding Serverless brings Nirvana
Today we are going to build the dream backend for your startup with TDD and Serverless.
Traditional API server have come a long way, but today’s fast moving projects need to kindly consider serverless, the sooner, the better.
Being requirement #1 to ship as soon as possible, the common side effect is that the codebase and infrastructure become harder to maintain once the product and the team grow.
Serverless architectures help mitigating this situation in many ways:
Lambda functions encourage to write granular, clean and specific API operations.
They also force to decouple code from the local architecture (url, ports, etc).
Combined with TDD, you can develop faster and leaner.
No server means no sysadmin. More time to spend on your project.
In short, what we are about to explore is:
A clean serverless API project
Ready for Test Driven Development
Connecting to a cloud database (MongoDB Atlas)
Using secret management
With automated deployment
Using staging environments
So let’s get right to it!
Start me up!
First, make sure that you have NodeJS on your system and install the Serverless framework:
npm i -g serverless (Windows)
sudo npm i -g serverless (Linux and MacOS)
Cloud accounts
Create an account on Amazon Web Services and open the IAM Management Console when you are done. You need to add a new user.

Give it a meaningful name and enable “Programmatic access” for it.

By now, we are are just developing, so we will attach the AdministratorAccess policy and keep working on the project.
IMPORTANT: When the project is ready for production, get back to the lambda IAM user and check this article on how to apply the Least Privilege Principle.

Our AWS user is now ready. Copy the keys shown on the screen and run in the console:
serverless config credentials --provider aws --key <the-access-key-id> --secret <the-secret-access-key>
Done! Your serverless environment is ready to connect to Amazon and do its magic. Now let’s a database to connect to.
The choice of a particular database is out of the scope of this article. Because MongoDB is one of the most popular NoSQL databases, we will open an account at MongoDB Atlas.
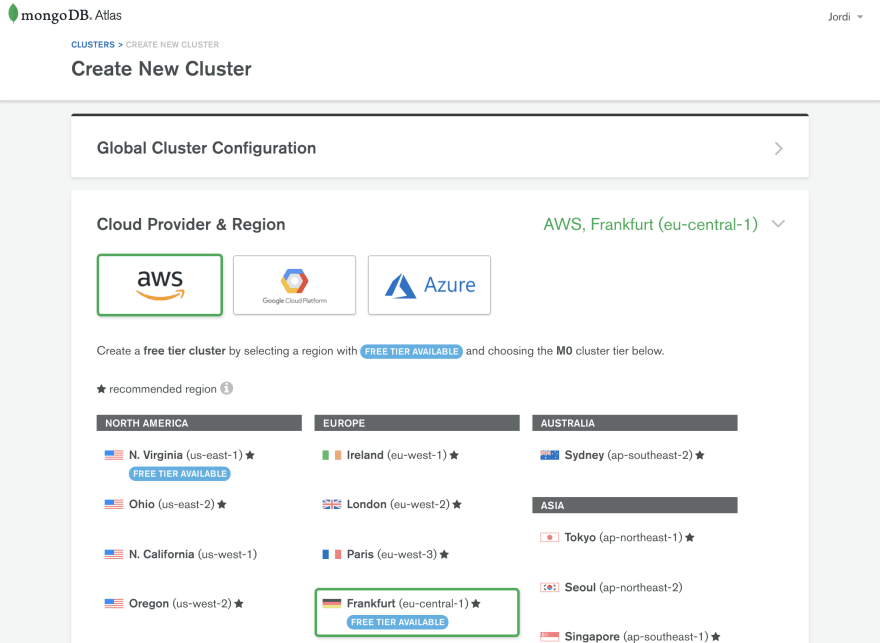
Select a provider and a region that suit your needs. Since our code will be running on AWS Lambda, it makes sense to select AWS as the provider, and the same region where we will deploy our lambdas.
Check any additional settings and choose a name for your cluster. Wait for a few minutes for it to provision.
When it is ready, open the Security tab of the cluster and add a new user.

Since we are just testing, enter a username/password of your choice and select “Read and write to any database”.
IMPORTANT: When you are ready for production, you should apply again the Least Privilege Principle and restrict privileges to just your app’s database. You should also create different users for production and staging environments.

Keep the user and password and get back to the cluster overview. Click on the “Connect” button. Next we need to whitelist the IP addresses allowed to connect to the database. Unfortunately, on AWS Lambda we have no predictable way to determine the IP address that will connect to MongoDB Atlas. So the only choice is to go for “Allow access from anywhere”.

Finally, click on “Connect your application”, choose version 3.6 and copy the URL string for later.

Let’s code!
Enough accounts, now let’s get our hands dirty. Open the console and create a NodeJS project on folder my-api:
serverless create --template aws-nodejs --path my-api
cd my-api
Let’s invoke the default function:
serverless invoke local -f hello
(output)
{
"statusCode": 200,
"body": "{\"message\":\"Go Serverless v1.0! Your function executed successfully!\",\"input\":\"\"}"
}
Ok, running. Let’s create the package.json and add a few dependencies:
npm init -y
npm i mongodb
npm i -D serverless-offline serverless-mocha-plugin
Next, let’s define our environment. The serverless CLI just created the file serverless.yml for us. Clean it up and edit serverless.yml like this:
A few things to note here:
We are using NodeJS 8.10 in order to get the modern Javascript goodies.
We have defined the same region that we previously chose on MongoDB Atlas.
A hello function is added by default in
handlers.jsWe are adding two plugins at the bottom (from the dependencies we installed before). In a Daft Punk fashion, they will help us develop better, faster, stronger.
Now we can start listening for incoming HTTP requests on our local computer:
serverless offline start

So if we open our browser and visit http://localhost:3000, we will get the output of the hello function, which is attached to the / path by default. The output is a message, in addition to the HTTP headers and parameters that the function gets.

The cool thing is that if we edit handlers.js so that hello returns something different, you’ll notice that refreshing the browser will show the updated content. Live reload API out of the box!
Before we jump into our TDD environment, let’s tidy up a bit our project and arrange our files and routes.
mkdir handlers test
rm handler.js
touch handlers/users.js
The routes we will be supporting are:
GET /users
GET /users/<id>
POST /users
PUT /users/<id>
DELETE /users/<id>
So let’s edit serverless.yml and define them. Edit the functions: block to contain these lines:
As you can see, each key inside the functions block is the name of a Lambda function. Note that handler: handlers/users.list would translate into:
Use the list JS function inside handlers/user.js.
Time to TDD!
The serverless CLI provides a command to add new tests for each function. Let’s check it:
serverless create test -f listUsers
serverless create test -f getUser
serverless create test -f addUser
serverless create test -f updateUser
serverless create test -f removeUser
The test folder now contains a dummy spec file for each of our Lambda functions. As all our user-related functions are pointing to handlers/users.js maybe it’s better that the specs keep the same structure.
So let’s discard the isolated specs rm test/* , combine them into a single file and code the full user spec in test/users.spec.js.
As you can see, instead of importing just one function wrapper, we import them all and define test cases for the whole set.
You may also note that we are not performing HTTP requests. Rather we have to pass the parameters as they would be received by the function. If you are interested to spec like an HTTP client, check this library.
What happens now if we run the test suite?
serverless invoke test
You guessed it! Booom. And that’s because… we haven’t coded yet the handlers! But as you know: in TDD, specs are coded before the application logic.
So, as our runtime is NodeJS 8, we can take advantage of ES6/ES7 features to write cleaner code in our lambda functions. Let’s implement the (still undefined) functions in handlers/users.js:
Note that unlike a traditional NodeJS server, the connection to the database needs to be opened and closed at each execution. This is due to the nature of how serverless works: there is no process running all the time. Instead, instances are created and destroyed when external events occur.
Also note that all routes make sure to always close the DB connection. Otherwise, the internal NodeJS event loop would keep the process alive until the timeout was reached, and you might incur in higher charges.
And finally, note that thanks to using NodeJS v8, we can return our response instead of using callbacks with error-first parameter.
So now, our specs are ready, our implementation is there. The moment of truth:

Yay! Here is our first serverless API. As you may see, local execution times are not particularly impressive, but keep the following in mind:
Our goal is not about single request speed. Rather, we aim for concurrent massive scalability, easy maintainability and future-proof code.
Latencies are mainly due to the time spent by our local computer connecting to the remote database. Tests with 3~4 DB requests will experience much higher latencies than when code is running within the datacenter.
We are using the lightest implementation possible (
mongodbinstead ofmongoose, and plain JS instead of Express/Connect on top of Serverless).If you switch to a local MongoDB server, running the tests will take around 80ms.
We’ll check performance back when our code is deployed.
Secret management
We are almost ready to deploy, but before we need to deal with an important aspect: keeping credentials out of the codebase.
Luckily for us, Serverless suports Simple Systems Manager (SSM) since version 1.22. This means that we can store key/value data to our IAM user and have it automatically retrieved whenever Serverless needs to resolve a secret.
So, first of all let’s get back to our handlers/users.js file, copy the current URL string and replace:
const uri = "mongodb+srv://lambda:lambda@myapp...."
with:
const uri = process.env.MONGODB_URL
Next, let’s add an environment block to provider in serverless.yml :
provider:
name: aws
runtime: nodejs8.10
stage: prod
region: eu-central-1
environment:
MONGODB_URL: ${ssm:MY_API_MONGODB_URL~true}
This will bind the MONGODB_URL environment variable to the MY_API_MONGODB_URL SSM key at deploy time and ~true will decrypt the contents with the default IAM user's key.
Finally, let’s grab the string we just copied and store the credential in our SSM:
pip install awscli # install the AWS CLI if necessary
aws configure # confirm the key/secret, define your region
aws ssm put-parameter --name MY_API_MONGODB_URL --type SecureString --value "mongodb+srv://lambda:xxxxxx@myapp-.....mongodb.net/my-app?retryWrites=true"
If you are part of a bigger team, read here.
Deploying
Stay with me, we are almost done! Let’s deploy our code to the cloud. We will update serverless.yml before. Then:
serverless deploy

Ready! You can also manage them here (select the appropriate region).
If you call the URL corresponding to the listUsers function you will see that the latency takes under one third of what it was taking from out computer.

This happens because now, the lambda function and the DB server are in the same region (i.e. datacenter), so connection latencies between them are considerably lower. Our round trip to Amazon will always be there, but now DB connections will not.
Production
As already commented during the article, when your API is ready to ship:
Remove the administrative permissions from your IAM user and refer to this page for insights on how to grant fine grained privileges.
Restrict the privileges of the DB user to only the database of your application, and not just any.
Deployments should only be made by project maintainers. The rest of developers shouldn’t need to configure any IAM Lambda credentials.
Cleaning
Deploying a Lambda function will involve (at least) three different services from Amazon. If you intend to wipe an existing Lambda function you need to:
Delete the function from AWS Lambda
Delete the corresponding bucket from S3
Delete the corresponding stack from CloudFormation
Wrap up
I hope you enjoyed reading the article as much as I enjoyed writing it. If you want more, heart, unicorn, comment, share and smile 🙂!
If you want to experiment with the code of the article, feel free to clone the starter repo from GitHub: https://github.com/ledfusion/serverless-tdd-starter/tree/part-1
BTW: I am available to help you grow your projects.
Feel free to find me on https://jordi-moraleda.github.io/
Bonus track #1: Staging
If you are like most of us, you will need at least 3 environments for your project: development, staging and production.
For the database, developers could use a local instance of MongoDB to speed connections up, but for staging and production, we need to provide completely independent database environments.
Head back to MongoDB Atlas and create two different user accounts (my-app-prod and my-app-staging ) with access to two different databases (my-app-prod and my-app-staging respectively).
Let’s remove the key we created before:
aws ssm delete-parameter --name MY_API_MONGODB_URL
And create two, for production and staging:
# PROD
aws ssm put-parameter --name MY_API_MONGODB_URL_prod --type SecureString --value "mongodb+srv://my-app-prod:xxxxxx@myapp-.....mongodb.net/my-app-prod?retryWrites=true"
# STAGING
aws ssm put-parameter --name MY_API_MONGODB_URL_staging --type SecureString --value "mongodb+srv://my-app-staging:xxxxxx@myapp-.....mongodb.net/my-app-staging?retryWrites=true"

Now let’s edit serverless.yml > provider and let’s do some magic:
First of all, the stage field tells Serverless where to deploy the lambdas. If you deploy like below:
serverless deploy --stage prod
Then, provider.stage would be "prod" . If we just ran serverless deploy then provider.stage would default to "dev".
Second, the value of MONGODB_URL is evaluated in 2 steps, depending on the environment. If we are on "prod" or "staging", Serverless will fetch MY_API_MONGODB_URL_prod or MY_API_MONGODB_URL_staging respectively from SSM and use the value. If our IAM user does not have that key, MONGODB_URL will default to "mongodb://localhost:27017".
Ta da! This allows our development team to code and test from their local database, while code running on AWS will get the remote URL connection string.

Here they are, so staging and prod are ready to go!

Bonus track #2: Automated tasks
As the title suggests, we are aiming for nirvana, not just zen. Having to type repetitive commands may be a bit of overhead, so let’s finish our show with a clean set of commands to work with the project.
As a recap, the actions we may perform during the lifecycle of the project are:
Run the app locally
Run the test suite
Run the test suite and deploy to staging if successful
Run the test suite and deploy to production if successful
So let’s define these actions on our package.json :
...
"scripts": {
"deploy": "npm test && sls deploy --stage staging",
"deploy:prod": "npm test && sls deploy --stage prod",
"start": "serverless offline start",
"test": "serverless invoke test"
},
Now the team can run the API with npm start and test with npm test, while the project maintainer can deploy to staging with npm run deploy and to production with npm run deploy:prod. Nobody will interfere with unintended settings, data or environments.
After this whole exercise of integrations, you should have an easy to code, test, upgrade and maintain backend. It should work well with agile teams and fast moving companies and I hope that it does for you!
Thanks for your read.
If you liked it, do not miss the part #2 of this article.
This post was originally posted on medium.com.
Photo by Marion Michele on Unsplash

Top comments (6)
Awesome write-up! I'll be using your TDD approach from now on for sure.
What about connection pooling, have you thought about ways it can be done? Opening and closing connections to the database all the time can easily overload the server it is running on.
From what I've hacked so far, caching the connection with mongoose seems to be the way to go.
Anyhow, great walkthrough! Happy to see more people experimenting with serverless architectures. 😁
Hi again Adnan, here you have part #2: dev.to/ledfusion/if-tdd-is-zen-add.... I hope you like it!
BTW, I just saw your articles on Serverless as well, very nice work!
I will have a look on your article about migrating Rest API's ;)
Hey Jordi! Thank you, I've poured a lot of R&D into serverless POC apps. Have fun reading my stuff. I'll check out your next article right away. 😁
Thank you for your kind feedback, Adnan :)
I will be talking about connection pooling, mongoose, webpack and maybe end-to-end testing in episode 2, so stay tuned :)
Sweet! Will be looking forward to it.
Jordi this is a great write up. I am curious why you generate keys for serverless instead of just using your aws profile configured locally?