
Introduction
Supervised classification is a fundamental machine learning task where a model learns from labeled data to classify new instances into predefined categories. Several classification algorithms exist, including Logistic Regression, Decision Trees, K-Nearest Neighbors, Naïve Bayes, and ensemble techniques like Random Forest and Boosting. Evaluating these models requires performance measures like accuracy, precision, recall, F1-score, and ROC-AUC.
This blog explores parameter tuning techniques to optimize the performance of Logistic Regression, Decision Tree, and Random Forest models. Additionally, we discuss handling imbalanced datasets and using advanced ensemble techniques to enhance predictive accuracy, along with code examples and real-time applications. Understanding these methods is essential for improving classification performance in real-world scenarios, such as financial risk assessment, fraud detection, and medical diagnosis.
Real-World Application: Predicting Loan Default
To better understand these models, let's consider a real-world problem: predicting whether a customer will default on a loan. This involves classifying customers as defaulters (1) or non-defaulters (0) based on features like income, credit score, loan amount, and payment history. Accurate predictions can help financial institutions mitigate risks and improve lending strategies.
Understanding Classification Models
Before delving into optimization techniques, it's essential to grasp the working mechanisms of key classification models:
- Logistic Regression: Uses a linear function and applies a sigmoid activation to classify outcomes probabilistically.
- Decision Trees: Splits data recursively based on feature importance to make classification decisions.
- Random Forest: An ensemble method that aggregates multiple decision trees for robust classification.
- Boosting Methods: Focus on iteratively improving weak models by prioritizing difficult-to-classify instances.
Logistic Regression and Odd's Probability with Performance Measures
Logistic Regression is a linear model used for binary classification. It predicts probabilities using the sigmoid function:
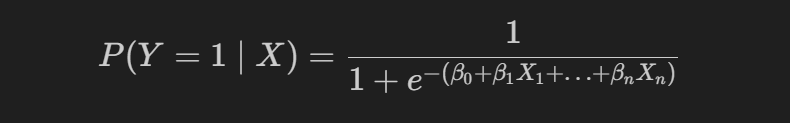
Performance Measures:
- Accuracy: Correct predictions over total predictions.
- Precision & Recall: Measures quality and sensitivity.
- F1-score: Harmonic mean of precision and recall.
- ROC-AUC: Evaluates discrimination ability between classes.
Parameter Tuning:
- Regularization (L1 & L2): Helps prevent overfitting.
- Solver selection (liblinear, saga, lbfgs): Impacts optimization convergence.
- C (Inverse Regularization Strength): Controls model complexity.
Effect of Hyperparameters
Regularization techniques, like L1 (Lasso) and L2 (Ridge), help in preventing overfitting and feature selection. Choosing an optimal regularization parameter (C) directly impacts model performance. A small C value forces stronger regularization, reducing model complexity but potentially underfitting the data. A large C value relaxes regularization, which may lead to overfitting.
Loan Default Prediction Example:
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
# Load dataset
loan_data = pd.read_csv('loan_default_data.csv')
X = loan_data[['income', 'credit_score', 'loan_amount', 'payment_history']]
y = loan_data['default']
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Hyperparameter tuning
param_grid = {
'C': [0.01, 0.1, 1, 10],
'penalty': ['l1', 'l2'],
'solver': ['liblinear', 'saga']
}
log_reg = LogisticRegression()
grid = GridSearchCV(log_reg, param_grid, cv=5, scoring='accuracy')
grid.fit(X_train, y_train)
# Model evaluation
best_model = grid.best_estimator_
y_pred = best_model.predict(X_test)
print(classification_report(y_test, y_pred))
Handling Imbalanced Datasets with SMOTE & Random Under Sampling
Many real-world datasets, such as fraud detection and medical diagnosis, are highly imbalanced. An imbalanced dataset can lead to biased predictions, where the model favors the majority class. To counteract this, we can use SMOTE (Synthetic Minority Over-sampling Technique) to generate synthetic samples for the minority class or use random under-sampling to reduce the number of majority class instances.
Implementation:
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import RandomUnderSampler
smote = SMOTE()
X_resampled, y_resampled = smote.fit_resample(X_train, y_train)
Importance of Handling Imbalanced Data
Failing to address imbalanced datasets can lead to misleading model evaluations. Metrics like accuracy can be deceptive when one class is predominant. Techniques such as Precision-Recall tradeoff and ROC-AUC analysis are crucial in such cases.
Bagging Classifier & Random Forest with Hyperparameter Tuning (Customer Loan Approval)
Bagging (Bootstrap Aggregating) reduces variance by training multiple base classifiers on bootstrapped data samples. Random Forest extends this by training multiple decision trees and averaging their predictions for better performance.
Random Forest Implementation:
from sklearn.ensemble import RandomForestClassifier
param_grid = {
'n_estimators': [50, 100, 200],
'max_features': ['sqrt', 'log2'],
'bootstrap': [True, False]
}
rf = RandomForestClassifier()
grid = GridSearchCV(rf, param_grid, cv=5, scoring='accuracy')
grid.fit(X_train, y_train)
Boosting, Stacking, and Voting in Ensemble Learning
Boosting techniques combine weak learners to build strong models by focusing more on misclassified instances in each iteration. Boosting methods include AdaBoost, Gradient Boosting, and XGBoost.
Stacking & Voting:
from sklearn.ensemble import StackingClassifier, VotingClassifier
from sklearn.svm import SVC
stack = StackingClassifier(
estimators=[('rf', RandomForestClassifier()), ('svm', SVC(probability=True))],
final_estimator=LogisticRegression()
)
stack.fit(X_train, y_train)
Conclusion
Fine-tuning classifiers is crucial for performance improvement. Using real-world examples like loan default prediction, fraud detection, and loan approval risk analysis, we demonstrated how parameter tuning can significantly improve model accuracy. Techniques like SMOTE for imbalanced data, Decision Trees for risk profiling, and ensemble methods like Boosting and Stacking provide robust solutions to real-world classification problems. By applying these methodologies, businesses can improve decision-making processes, reduce risks, and enhance predictive model accuracy in dynamic environments.

Top comments (0)