
Part #2 of a small series
Brazilian "Rinha de Backend" challenge. Click here to part 1
15th of August, 7AM.
I woke up, took a long breakfast, sitting at my office and started tackling the ghost that spent the night before haunting me. (In this case, my brain + overthinking)
Some of his tips, thou, did really help!
- Fixing these two queries(1,2) business rules
- Adding more replicas into NGINX and DockerCompose
- Fine tuning resources on DockerCompose
- Fixing PINO async logging
- Configuring NGINX worker connections
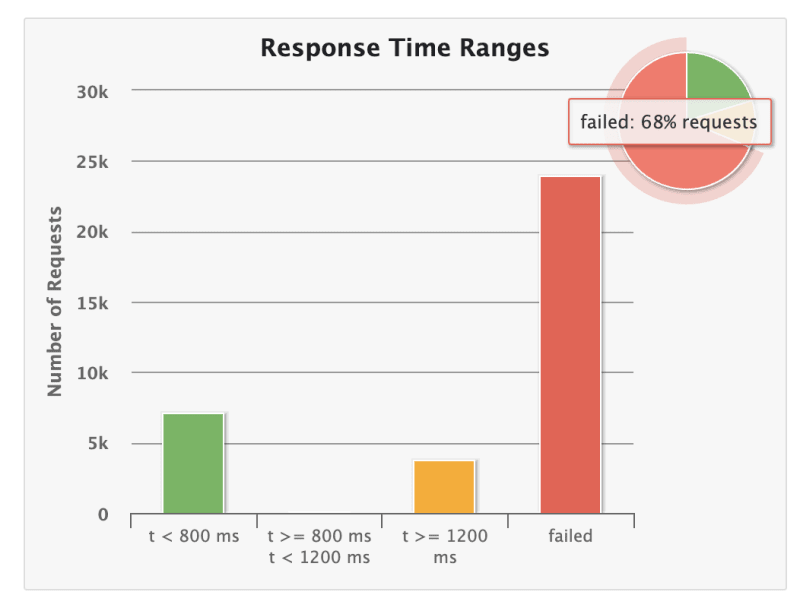
I was able to get some good improvements reaching ~31% of success which really sounded way better than 10%. But man, something was really off.
Why did my application performed so bad?
Well. I had forgotten to address yesterday's finding. The database bottleneck.
First thing I did was to copy the database query and ran it against at least 40K patients. Surprisingly, it took 50 seconds even thou I was certain I had indexes setup.
But before I explain the database optimization I did I need to explain the structure I had before the improvement.
CREATE TABLE IF NOT EXISTS pessoas (
id SERIAL PRIMARY KEY,
apelido VARCHAR(32) UNIQUE NOT NULL,
nome VARCHAR(100) NOT NULL,
nascimento DATE NOT NULL,
stack VARCHAR(32)[]
);
CREATE INDEX IF NOT EXISTS term_search_index_apelido ON pessoas USING gin(to_tsvector('english', apelido));
CREATE INDEX IF NOT EXISTS term_search_index_nome ON pessoas USING gin(to_tsvector('english', nome));
The best tool to analyze what steps the database took to run the query (and much more) is the EXPLAIN.
And of course I had forgotten a index. But how I would index a ARRAY field for FTS? That was a bad design choice. Arrays can't be text indexed, the performance is kinda bad for this use-case.
Well, let's ship this responsibility to the client. The stack field became a JSON field which the client deserializes and serializes. The JSON field is text-indexed and voilá, we now have a index for stack field.
Run the query again: Less than 20ms. Cool. That's what's expected.

Not surprisingly I reached 45% of success and 27% of >1200ms requests. My database lowered CPU usage and errors like premature connection, timeouts and connection losses only appeared by the middle-to-end of the stress test.
Database-wise I thought that It was as far as I could get.
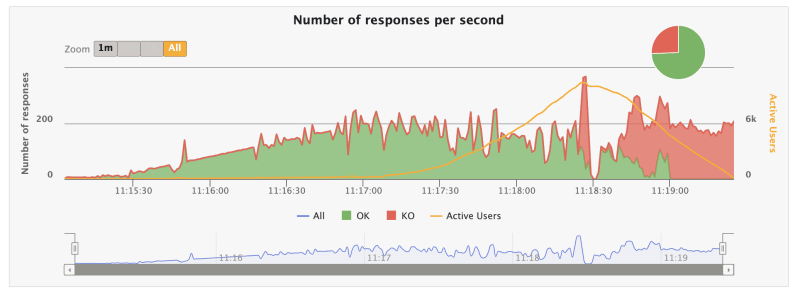
It's time for cache.
I decided to use Redis instead of LRU memory caches since I had distributed applications and I was aiming to have at least 4-5 replicas which would make the same resource not to frequently requested on the same pod/container.
The caching strategy
- /pessoas?t
- Cached the response.
- POST: /pessoas
- Cached the the entire resource by ID after creation
- Cached the
apelidofield since it had a unique constraint on the database.
- GET: /pessoas/:id
- Checked cache before hitting database.
- On the validation middleware I had setup(middleware.js)
- Checked if person already existed on Redis SET and if not checked database. If it did exists, we updated the cache and returned the response back to the client
That is a rather simple Redis caching setup.
(Which I would never ship to production environments at least)

Finally an acceptable success rate! 92% of success being 4% of requests above 1200ms.
But still...That database CPU usage too high even with caching and the connection closes was still a thing.
Back Into DB Optimizations
I figured I had a way over the top PG connection pool configured.
And it was kinda reasonable given that we were running 3-4 replicas, each one with 8 connection on a database that had less than 1 CPU allocated.
(I've also reduce to 3 replicas of the application)
With this small improvement I was able to reach 100% of success rate
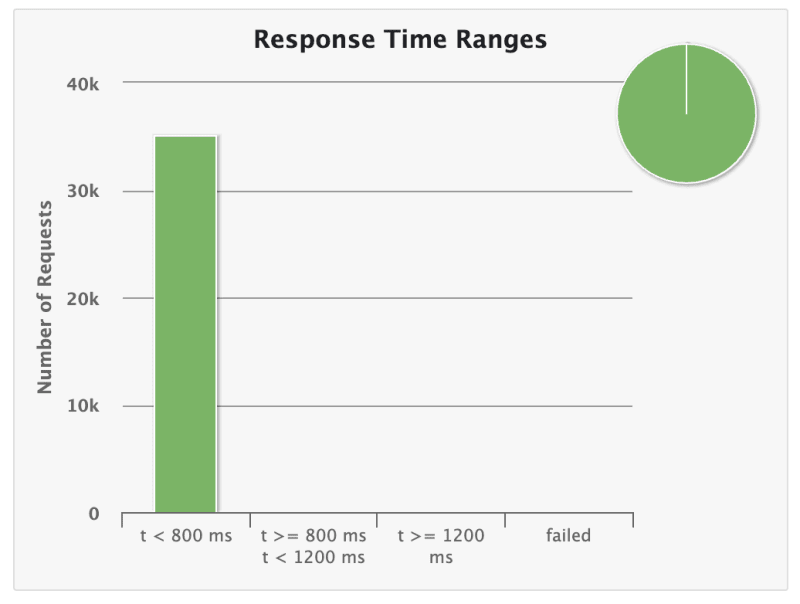

Finally I had the same benchmarks from my fellow colleagues but more than so I realized how much the attention to detail needs to be taken seriously when dealing with scale. This was a sandbox experiment and I had a lot of small issues, small legacy-type code (1 day legacy. I'll call it), small premature optimizations and some over the top gimmicks trying to figure out simple stuff.
I had accomplished what I proposed to myself. Although I knew It had way more possible optimization to be done but I decided to step-way from competition.
But this is for the next talk...

Top comments (2)
Awesome article!
Do you plan to continue improving this project even though the "Rinha" has ended?
Would be nice to see more improvements and articles about the maximum of performance you can have on this challenge!
Yeah man! Great read this morning.