
What we left behind
In the previous post we've set up our development environment. We pulled the relevant crates and explained how to interact with the unofficial Azure SDK for Rust. In this post we will learn how to insert documents into Cosmos DB.
Cosmos DB hierarchy
In the previous post we called the list_databases function. This implied that we can have more than one database for each Cosmos DB account. It's not over though: the Cosmos DB hierarchy is quite complex.
Here is a super simplified view of Cosmos DB entities and their relationship:
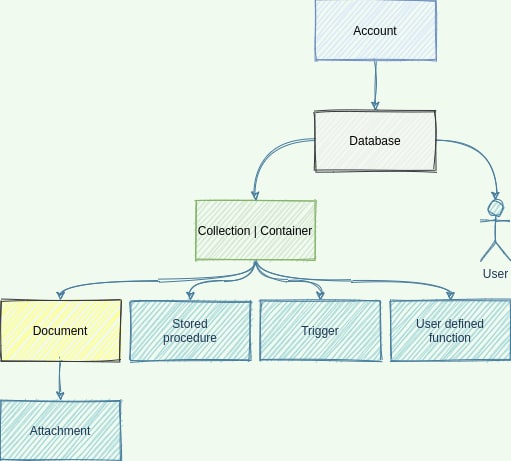
It reads from top to bottom. For example: "A Cosmos DB account can have zero or more databases. Each database can have zero or more collections. Each collection can have zero or more document". And so on.
In other words, before even starting to insert a document, we need at least:
- A Cosmos DB account
- A database
- A collection/container.
In this context Collection and Container are synonyms. They are inconsistently named in the official docs and in the Azure portal. Just remember that are the same thing. Here I will adhere to the official docs and call them collections.
What is a document, anyway?
In the true spirit of a NoSQL, Cosmos DB lets you store almost any JSON you want as document. I said almost because your document must:
- Include a unique field called
id. - Have a partition key (this is custom and decided upon collection creation).
- Must be at most 2 MB (as expressed in UTF-8).
There are other limits (you can check them here) but unless you do something weird (like creating an id of 1MB 💩) you are unlikely to hit them.
The 2 MB limitation, in practice, is not that bad. You can use the attachments feature of a document if you need to store blobs of data anyway.
Go ahead and create the Customers collection. We will use age as partition key. While you can use the SDK for this task, for the first tests I suggest you to use the Azure portal.
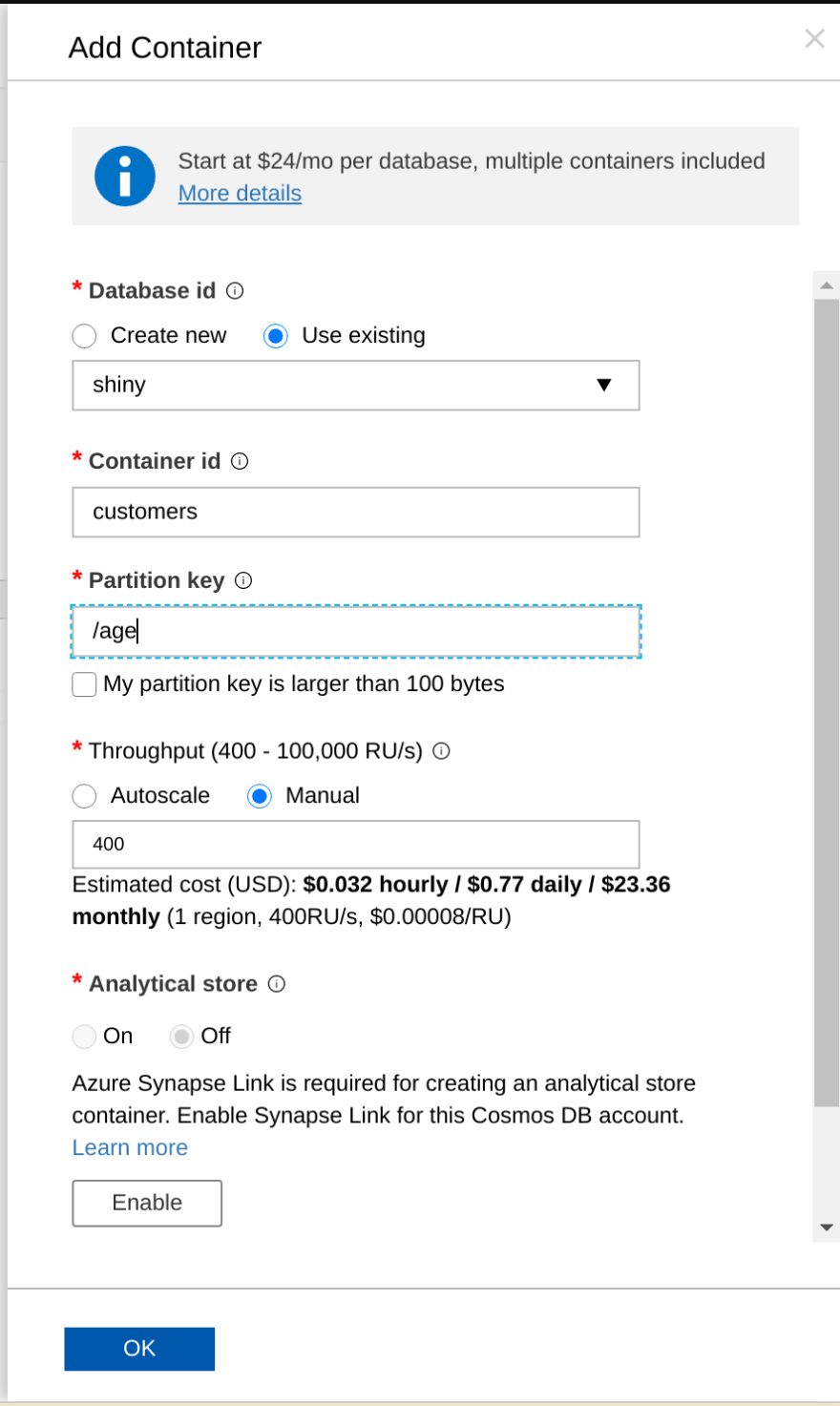
Be warned: Azure Portal is continuously changing for the better. The above screenshot can be outdated while you read this!
Down to the code
Now that we have the collection we need to specify it in our code. If you remember from the Cosmos DB hierarchy, a collection needs a database and a Cosmos DB account.
So the code is pretty straightforward:
let cosmos_client = ClientBuilder::new(&account, authorization_token)?;
// create a database client for our shiny database
let database_client = cosmos_client.into_database_client("shiny");
// create a collection client for our customers database
let collection_client = database_client.into_collection_client("customers");
Now we can call its functions! Let's start easy:
use azure_sdk_cosmos::responses::ListDocumentsResponse;
let response: ListDocumentsResponse<serde_json::Value> =
collection_client.list_documents().execute().await?;
println!("{:#?}", response);
Of course there are no documents yet but our first call succeeded (you will need to import serde_json in your Cargo.toml file for this to work).

Notice that Cosmos DB returned us a plethora of info. Most of this stuff we can safely ignore. The only important bit is the session token. In the previous post we talked about session consistency. This is how we achieve that in Cosmos DB.
Turbofish
The above call was cumbersome. We specified the return type by hand. It's something we do not usually do in Rust; generally the compiler is smart enough to figure out the correct type by itself.
In this case, though, we need to help it: the list_documents function can return any serializable type so the compiler does not know which one we want. In the example we asked for the plain JSON document list (notice the serde_json::Value type).
We can avoid specifying the return type (the ListDocumentsResponse part) if we use the turbofish syntax:
let response = collection_client
.list_documents()
.execute::<serde_json::Value>() // we passed the type here!
.await?;
I generally prefer the turbofish syntax - if only because of its cool name - but some people find it hard to grasp so you can choose whichever you like. Makes no difference whatsoever!
Insert a document already!
Yes, you are right, we are not doing our job! Let's start by defining a customer to add. We will once more ask for serde_json help:
let customer = serde_json::from_str::<serde_json::Value>(
r#"
{
"id": "e543ae93-27e2-45d6-b26d-eb83eb1a7762",
"name": "Plo Koon",
"homeworld": "Korin",
"age": 43,
"phones": [
"+4123454 1234567",
"+4123454 2345678"
]
}"#,
)?;
println!("{:#?}", customer);
As you can see we are hardcoding the JSON. This is not necessary of course, we will see how to use Rust structs in a future blog post.
Now that we have the customer, let's call the create_document function! We need to pass the partition key and of course the document itself:
let response = collection_client
.create_document()
.with_partition_keys(PartitionKeys::new().push(43)?) // let's pass the partition key
.execute_with_document(&customer) // pass the document itself!
.await?;
println!("{:?}", response);
Couple of things to note:
- The SDK supports multiple
PartitionKeys, as per API specification. This is not yet supported in Cosmos DB so for the time being stick with one key only. - Instead of the classic
executewe haveexecute_with_document. This is due to a nasty Rust bug: as soon as it's fixed the SDK will revert to the standard function name.
By the way, you can create the PartitionKeys struct with the into() function, like this:
// cut
.with_partition_keys(&(43i64.into()))
// cut
Let's run this code:
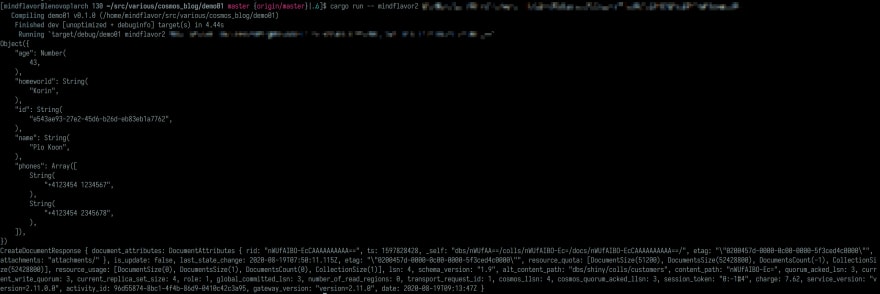
The addition went successfully. We also got back some info of our collection. For the curious, charge is the operation cost in terms of Cosmos DB units. The various LSN indicate the last sequence number of our database and is very important for data consistency. The quotas indicate how close to the limits we are.
Closing words
Now let's check in the portal if our late general has been added to our collection:
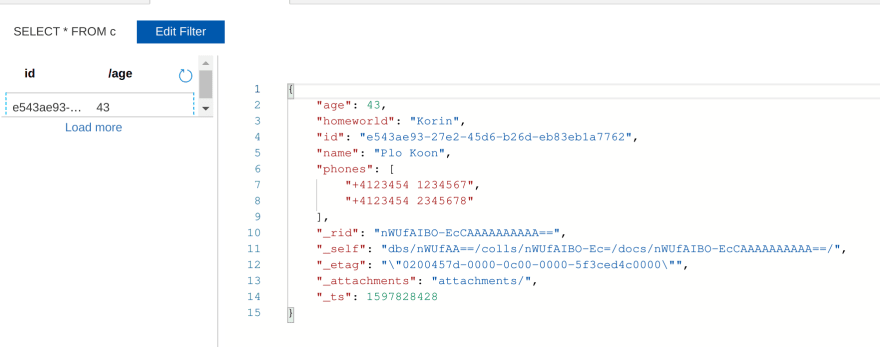
Notice how helpfully the data explorer shows you the id and our partition key.
You can also call the list_documents function again. This time it will not be empty!

In the next post we will use serde to work directly with the structs instead of using the JSON.
Happy coding,
Francesco Cogno

Top comments (0)