
MobiDev would like to acknowledge and give its warmest thanks to the DementiaBank which made this work possible by providing the data set.
Mental illnesses and diseases that cause mental symptoms are somewhat difficult to diagnose due to the uneven nature of such symptoms. One such condition is dementia. While it’s impossible to cure dementia caused by degenerative diseases, early diagnostics help reduce symptom severity with the proper treatment, or slow down illness progression. Moreover, about 23% of dementia causes are believed to be reversible when diagnosed early.
Communicative and reasoning problems are some of the earliest indicators used to identify patients at risk of developing dementia. Applying AI for audio and speech processing significantly improves diagnostic opportunity for dementia and helps to spot early signs years before significant symptoms develop.
In this study, we’ll describe our experience creating a speech processing model that predicts dementia risk, including the pitfalls and challenges in speech classification tasks.
AI Speech Processing Techniques
Artificial intelligence offers a range of techniques to classify raw audio information, which often passes through pre-processing and annotation. In audio classification tasks we generally strive to improve the sound quality and clean up any present anomalies before training the model.
If we speak about classification tasks involving human speech, generally, there are two major types of audio processing techniques used for extracting meaningful information:
Automatic speech recognition or ASR is used to recognize or transcribe spoken words into a written form for further processing, feature extraction, and analysis.
Natural language processing or NLP, is a technique for understanding human speech in context by a computer. NLP models generally apply complex linguistic rules to derive meaningful information from sentences, determining syntactic and grammatical relations between words.
Pauses in speech can also be meaningful to the results of a task, and audio processing models can also distinguish between different sound classes like:
- human voices
- animal sounds
- machine noises
- ambient sounds
All of the different sounds above may be removed from the target audio files because they can worsen overall audio quality or impact model prediction.
HOW DOES AI SPEECH PROCESSING APPLY TO DEMENTIA DIAGNOSIS?
People with Alzheimer’s disease and dementia specifically have a certain number of communication conditions such as reasoning struggles, focusing problems, and memory loss. Impairment in cognition can be spotted during the neuropsychological testing performed on individuals.
If recorded on audio, these defects can be used as features for training a classification model that will find a difference between a healthy person, and an ill one. Since an AI model can process enormous amounts of data and maintain accuracy of its classification, the integration of this method into dementia screening can improve overall diagnostic accuracy.
Dementia-detection systems based on neural networks have two potential applications in healthcare:
Early dementia diagnostics. Using recordings of neuropsychological tests, patients can learn about the early signs of dementia long before brain cell damage occurs. Applying even phone recordings with test results appears to be an accessible and fast way to screen population compared to conventional appointments.
Tracking dementia progression. Dementia is a progressive condition, which means its symptoms tend to progress and manifest differently over time. Classification models for dementia detection can also be used to track changes in a patient’s mental condition and learn how the symptoms develop, or how treatment affects manifestation.
So now, let’s discuss how we can train the actual model, and what approaches appear most effective in classifying dementia.
How do you train AI to analyze dementia patterns?
The goal of this experiment was to detect as many sick people as possible out of the available data. For this, we needed a classification model that was able to extract features and find the differences between healthy and ill people.
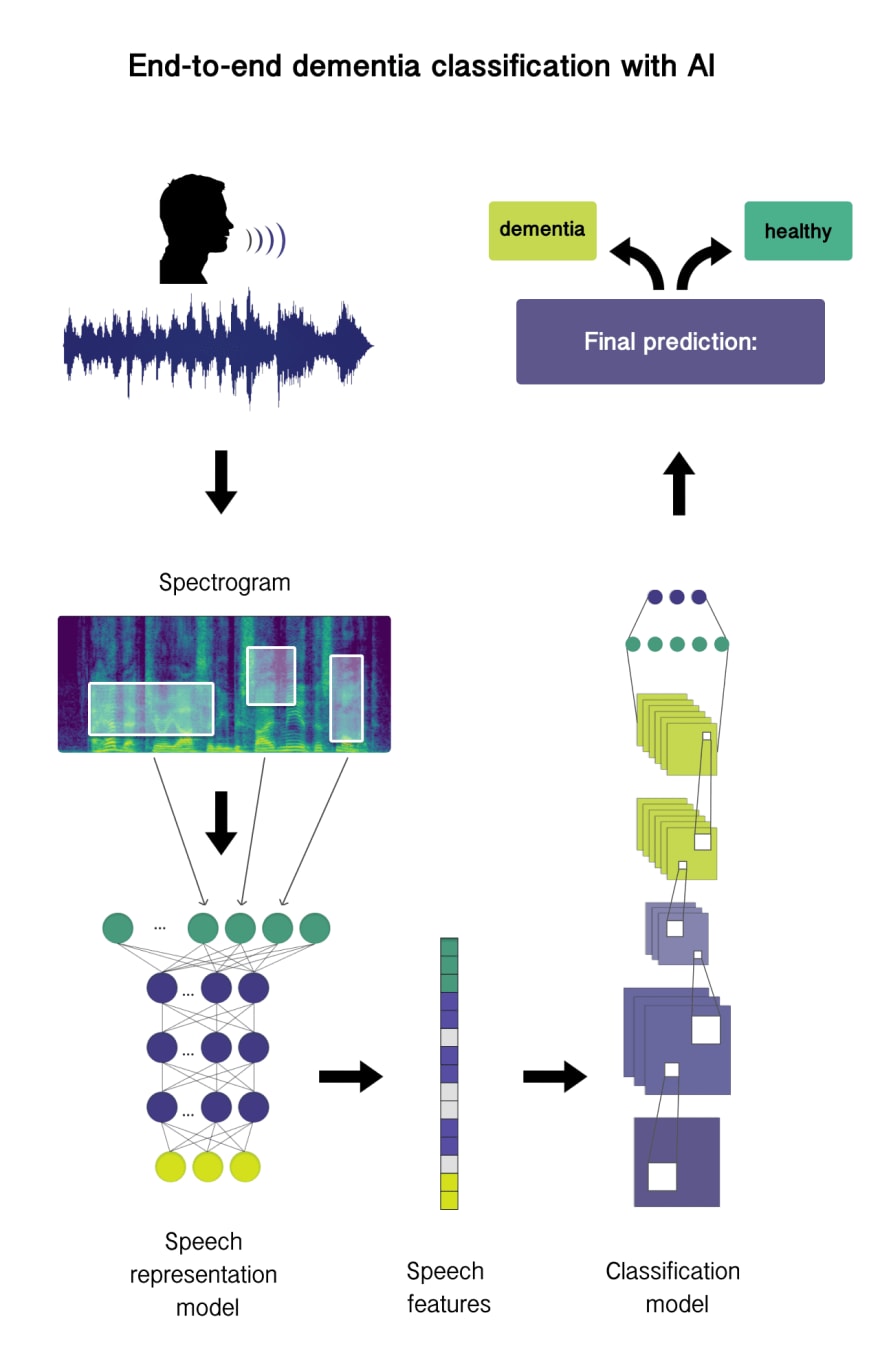
The method used for dementia detection applies neural networks both for feature extraction and classification. Since audio data has a complex and continuous nature with multiple sonic layers, neural networks appear superior to traditional machine learning for feature extraction. In this research 2 types of models were used:
Speech-representation neural network which accounts for extracting speech features (embeddings), and
Classification model which learns patterns from feature-extractor output
In terms of data, recordings of Cookie Theft neuropsychological examination are used to train the model.

Image source: researchgate.net
In a nutshell, Cookie Theft is a graphic task that requires patients to describe the events happening in the picture. Since people suffering from early symptoms of dementia experience cognitive problems, they often fail to explain the scene in words, repeat thoughts, or lose the narrative chain. All of the mentioned symptoms can be spotted in recorded audio, and used as features for training classification models.
ANALYZING DATA
For the model training and evaluation we used a DementiaBank dataset consisting of 552 Cookie Theft recordings. The data represents people of different ages split into two groups: healthy, and those diagnosed with Alzheimer diseases — the most common cause of dementia. The DementiaBank dataset shows a balanced distribution of healthy and ill people, which means neural networks will consider both classes during the training procedure, without skewing to only one class.
The dataset contains samples with different length, loudness and noise level. The total length of the whole dataset equals 10 hours 42 min with an average audio length of 70 seconds. In the preparation phase, it was noted that the duration of the recordings of healthy people is overall shorter, which is logicall, since ill people struggle with completing the task.

However, relying just on the speech length doesn’t guarantee meaningful classification results. Since there can be people suffering from mild symptoms, or we can become biased for quick descriptors.
DATA PREPROCESSING
Before actual training, the obtained data has to go through a number of preparation procedures. Audio processing models are sensitive to the quality of recording, as well as omission of words in sentences. Poor quality data may worsen the prediction result, since a model may struggle to find a relationship between the information where a part of recording is corrupted.
Preprocessing sound entails cleaning any unnecessary noises, improving general audio quality, and annotating the required parts of an audio recording. The Dementia dataset initially has approximately 60% poor quality data included in it. We have tested both AI and non-AI approaches to normalize loudness level and reduce noises in recordings.
Huggingface MetricGan model was used to automatically improve audio quality, although the majority of the samples weren’t improved enough. Additionally, Python audio processing libraries and Audacity were used to further improve data quality.
For very poor quality audio, additional cycles of preprocessing may be required using different Python libraries, or audio mastering tools like Izotope RX. But, in our case, the aforementioned preprocessing steps dramatically increased data quality. During the preprocessing, samples with the poorest quality were deleted, accounting for 29 samples (29 min 50 sec length) which is only 4% of total dataset length.
APPROACHES TO SPEECH CLASSIFICATION
As you might remember, neural network models are used in conjunction to extract features and classify recordings. In speech classification tasks, there are generally two approaches:
- Converting speech to text, and using text as an input for the classification model training.
- Extracting high-level speech representations to conduct classification on them. This approach is an end-to-end solution, since audio data doesn’t require conversion into other formats.
In our research, we use both approaches to see how they differ in terms of classification accuracy.
Another important point is that all feature extractors were trained in two steps. On the first iteration, the model is pre-trained in a self-supervised way on pretext tasks such as language modeling (auxiliary task). In the second step, the model is fine-tuned on downstream tasks in a standard supervised way using human-labeled data.
The pretext task should force the model to encode the data to a meaningful representation that can be reused for fine-tuning later. For example, a speech model trained in a self-supervised way needs to learn about sound structure and characteristics to effectively predict the next audio unit. This speech knowledge can be re-used in a downstream task like converting speech into text.
Modeling
To evaluate the results of model classification, we’ll use a set of metrics that will help us determine the accuracy of the model output.
- Recall evaluates the fraction of correctly classified audio records of all audio records in the dataset. In other words, recall shows the number of records our model classified as dementia.
- Precision metric indicates how many of those records classified with dementia are actually true.
F1 Score was used as a metric to calculate harmonic mean out of recall and precision. The formula of metric calculation looks like this: F1 = 2*Recall*Precision / (Recall + Precision).
Additionally, as in the first approach when we converted audio to text, Word Error Rate is also used to calculate the number of substitutions, deletions, and insertions between the extracted text, and the target one.
APPROACH 1: TEXT-TO-SPEECH IN DEMENTIA CLASSIFICATION
For the first approach, two models were used as feature extractors: wav2vec 2.0 base and NEMO QuartzNet. While these models convert speech into text, and extract features from it, the HuggingFace BERT model performs the role of a classifier.
Extracted by wav2vec text appeared to be more accurate compared to QuartzNet output. But on the flipside, it took significantly longer for wav2vec 2.0 to process audio, which makes it less preferable for real-time tasks. In contrast, QuartzNet shows faster performance due to a lower number of parameters.
The next step was feeding the extracted text of both models into the BERT classifier for training. Eventually, the training logs showed that BERT wasn’t trained at all. This could possibly happen due to the following factors:
- Converting audio speech into text basically means losing information about the pitch, pauses, and loudness. Once we extract the text, there is no way feature extractors can convey this information, while it’s meaningful to consider pauses during the dementia classification.
- The second reason is that the BERT model uses predefined vocabulary to convert word sequences into tokens. Depending on the quality of recording, the model can lose the information it’s unable to recognize. This leads to omission of, for example, incorrect words that still make sense to the prediction results.
As long as this approach doesn’t seem to bring meaningful results, let’s proceed to the end-to-end processing approach and discuss the training results.
APPROACH 2: END-TO-END PROCESSING
Neural networks represent a stack of layers, where each of the layers is responsible for catching some information. In the early layers, models learn the information about raw sound units also called low-level audio features. These have no human-interpretable meaning. Deep layers represent more human-understandable features like words and phonemes.
End-to-end approach entails the use of speech features from intermediate layers. In this case, speech representation models (ALBERT or HuBERT) were used as feature extractors. Both feature extractors were used as a Transfer learning while classification models were fine-tuned. For these classification tasks we used two custom s3prl downstream models: an attention-based classifier that was trained on SNIPS dataset and a linear classifier that is trained on Fluent commands dataset, but eventually both models were fine-tuned using Dementia dataset.

Looking at inference results of the end-to-end solution, it’s claimed that using speech features, instead of text, with fine-tuned downsample models led to more meaningful results. Namely, the combination of HuBERT and an attention-based model shows the most concise result among all approaches. In this case, classifiers learned to catch relevant information that could help differentiate between healthy people and those with Dementia.
For the explicit description of what models and methods for fine-tuning were used, you can download the PDF of this article.
How to improve the results?
Given the two different approaches to dementia classification with AI, we can derive a couple of recommendations to improve the model output:
Use more data. Dementia can have different manifestations depending on the cause and patient age, as symptoms will basically vary from person to person. Obtaining more data samples with dementia speech representations allows us to train models on more diverse data, which can possibly result in more accurate classifications.
Improve preprocessing procedure. Besides the number of samples, data quality also matters. While we can’t correct the initial defects in speech or actual recording, using preprocessing can significantly improve audio quality. This will result in less meaningful information lost during the feature extraction and have a positive impact on the training.
Alter models. As an example of end-to-end processing, different upstream and downstream models show different accuracy. Trying different models in speech classification may result in improvement of classification accuracy.
As the test results show, applying neural networks to analyzing dementia audio recordings can generate accurate suggestions. Training neural networks for speech classification tasks is a complex exercise that requires data science expertise as well as audio processing knowledge.

Top comments (3)
Glad there are more articles on this topic! Maybe they will find the cure soon__
Glad there is more and more research in this area. Both my grandparents had severe cases of dementia, and we were not able to help them in any way except by caring about them.
But I hope that by the time I age and develop similar issues, there will be a better cure for them. I have taken a brain test, which shows I am in danger. I really don’t want to get dementia or Alzheimer’s when I am old. I do some mental gymnastics every day, which seems to help, but I am still afraid that all the progress I made will disappear once I become an old man.