
This section is all about understanding the Big O and Time complexity of algorithms in 7 minutes (or less). It is a beginner-level section, so it should not be too difficult to understand.
Big O
Big O notation measures an algorithm's execution efficiency and how much memory it consumes. It can be thought of as either its time complexity or space complexity.
Whenever we talk about Big O and its efficiency measure, we are interested in how well an algorithm performs when the size of our input increases.
Big O helps to distinguish good from bad code and also bad from great code
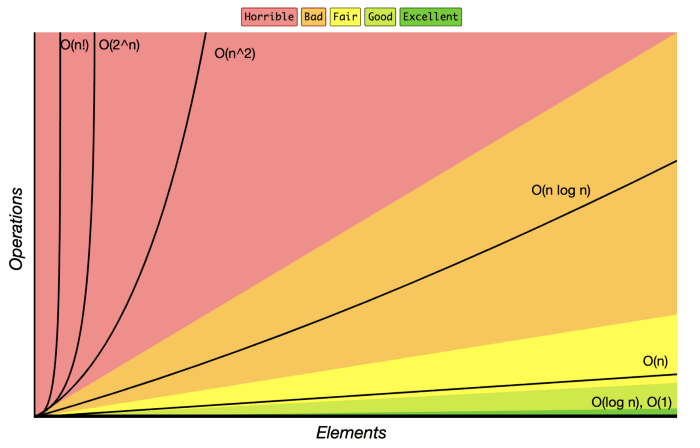
The most common time complexity you may have heard of or come across is O(n), O(n^2), O(log-n), and O(n log-n). I will talk about each of these, in detail, in a little bit.
O(1) - Constant Time
An algorithm is said to run in constant time if it requires the same amount of time, regardless of the input size.
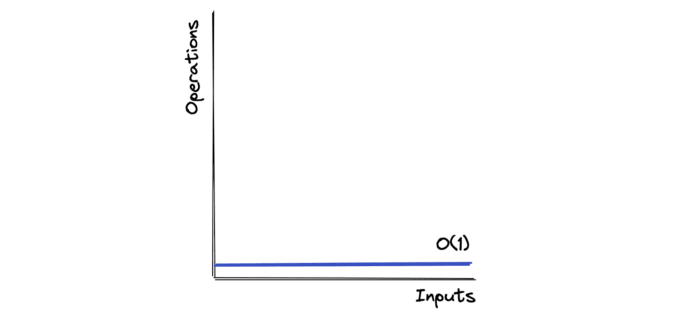
This algorithm has a time complexity of O(1).
O(n) - Linear Time
Algorithms with a time complexity O(n) are programmed to have an execution time directly proportional to the input size. This notation is also referred to as "Linear time."
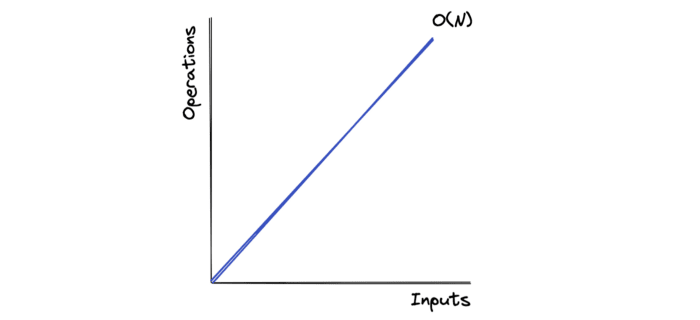
The following algorithm has a time complexity of O(n), where n is the length of the input array.
Big O Analysis - Best, Average & Worst cases
Before we continue to the more basic Big Os, it's worth knowing the different cases.
Best Case Analysis - Here, we calculate the best or minimum time an algorithm takes to finish.
Average Case Analysis - To calculate the average case of our algorithm, we need to be aware of all possible inputs it will receive. We then take the time for each use of this input and divide it by the number of inputs.
Worst Case Analysis - Here, we calculate the maximum time taken by the algorithm to finish.
Look at this example. Here we have a function that searches for a player named Kane from a list of players. It returns true if the player is found; else returns false.
The best case here is that Kane is at the beginning (the first element), and we need to loop the player list only once.
The worst case is that Kane, instead of being the 3rd element, is now present at the very end or, worse, not in the list for which our program needs to iterate through every element in the list.
We only care about worst-case scenarios when we're talking about time complexity. Maybe you are wondering why.
Let's say your code performs well on an average input, but it takes an unacceptable amount of time for specific inputs.
As a programmer, it is crucial to be aware of such scenarios and work out ways to optimize them or amend the algorithm. This is why people only discuss or care about the worst-case complexity of your program during interviews.
O(n²)
The time taken by the algorithm increases exponentially as the number of elements being iterated on (n) increases. So, for example, if you increase the input by 10x, you might need to wait 17 times as long for your desired output.
To understand this better, consider the following examples. As you can see, the computation time increases at an exponential pace of n²:
- 1 item = 1 second
- 10 items = 100 seconds
- 100 items = 10,000 seconds

Typically (but not always), nested for loops have a time complexity of O(n²).
Interviews often consider the O(n²) solution as a brute-force approach. So, it usually means finding much better approaches such as O(n log n) or even O(n) is possible.
O(log n)
To understand this, we will first look into the mathematics behind logarithms and then at how they relate to complexity analysis.
Wikipedia has the following definition for logarithm:
In mathematics, the logarithm is the inverse function of exponentiation.
That means the logarithm of a given number x is the exponent to which another fixed number, the base b, must be raised to produce that number x.

The binary logarithm uses base 2 (b = 2) and is frequently used in computer science. (Why base of 2? explained here).

Now, this might be a little hard to understand at first glance, so let's try to understand these equations with some examples:

Now that we've learned how to calculate log(n), let's keep increasing N and observe the increase in time complexity:
log(8) = 3
log(16) = 4
log(32) = 5
log(64) = 6
log(128) = 7
log(256) = 8
…
log(1024) = 10
log(~1M) = 20
log(~4B) = 32
Straightforward enough, one can see that when input N doubles, the time complexity log(N) increases only by 1. And in comparison to O(N), you can see how much better O(log(N)) performs.
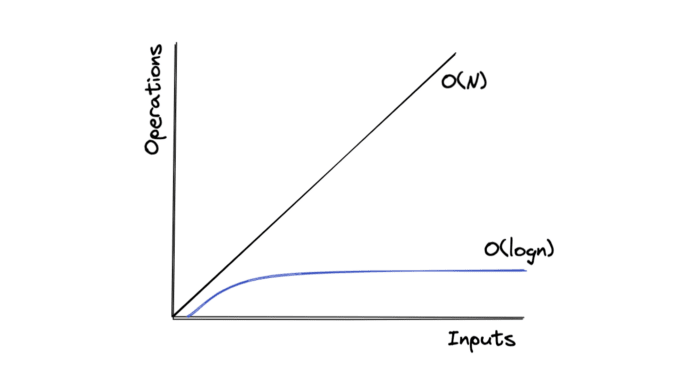
This time complexity is often found in divide-and-conquer algorithms, which divide the problem into sub-problems recursively before merging them again. For example, Binary Search, Merge Sort (O(N log N)), etc.
Some final thoughts
Once you get a firm grasp on the essential time complexities O(n), O(n²), and O(log n), it is easy to understand other types of complexity like O(n³), O(n log n), O(n!)… and how they work.
I want to return to the time complexity graph I shared at the beginning of this article.

Before you leave!
Understanding Big O is key to progress as a developer since it will help you to understand how to optimize your code since you will be able to calculate its complexity.
But, if you liked the post, I post more exciting content in my newsletter; you can check it for free here: Check Coderpreneurs now!
Also, I like to post engaging content and threads on Twitter, so I would recommend following me there too! This is my Twitter: @thenaubit.

Top comments (0)