
Neste post nós vamos explorar como as funções serverless da AWS, as Lambda Functions, podem simplificar, e muito, o nosso processo de desenvolvimento. Ao longo do post nós vamos conseguir entender como elas permitem que a gente se concentre no desenvolvimento da regra de negócio da nossa aplicação, sem se preocupar com a infraestrutura, servidor, memória ram...
Introdução à Arquitetura Serverless
Antes de tudo, quebrando a primeira ideia que você possa ter: não, arquitetura serverless não é uma arquitetura sem servidor. Diferente do que o nome nos faz imaginar, a arquitetura serverless tem sim um servidor. O que acontece é que ele não fica 100% do tempo pronto esperando uma requisição, na verdade, o servidor vai ao ar apenas quando essa requisição chega! E melhor, depois de executado o que for necessário, o servidor ja é desligado novamente automaticamente. Esse tempo de provisionar e começar a executar a maquina é chamado de Cold Start e pode ser um problema dependendo da nossa aplicação. Mas como veremos até o final desse post, existem maneiras de diminuir ele e manter bem alta a performance da nossa função. Além disso que eu comentei, como não precisamos hospedar um servidor, também não precisamos nos preocupar a infraestrutura dele. Quanto de RAM meu servidor precisa? Qual CPU devo utilizar? Um SSD de 1 TB basta? Essas são perguntas que não fazemos, pois quem cuida disso é a provedora desse serviço, no nosso caso, a AWS (Amazon Web Services). Essa arquitetura permite que a gente se concentre exclusivamente na regra de negócio da nossa aplicação, sem precisar gerenciar toda uma infraestrutura e sem se preocupar com código boilerplate para iniciar um servidor web (usando express.js por exemplo).
Claro, esse conceito se aplica não apenas às funções Lambda da AWS, mas também aos serviços serverless oferecidos por outras provedoras, como Google e Azure (da Microsoft). Sendo assim, as funções serverless acabam sendo ideais para tarefas esporádicas ou infrequentes, ou tarefas independentes que não precisam existir dentro de um servidor nosso, pois acabam ajudando a economizar custos e fazer a gente focar no valor que queremos entregar ao usuário, ao invés de gastar nosso tempo gerenciando servidores.
Nossa função serverless na AWS
No tutorial de hoje nós vamos criar uma função serverless na AWS (Lambda Function) que ficará disponível via uma URL para toda a internet. Para isso, precisaremos criar uma conta na AWS (https://aws.amazon.com/resources/create-account/) e depois logar no nosso Console (https://console.aws.amazon.com/). Então, na barra de pesquisa iremos buscar por “Lambda” e clicar na primeira opção, como na imagem:
Criando a nossa função
Agora, na aba “Functions”, vamos clicar no botão “Create Function” para… criar a nossa função.
Isso nos levará a uma outra pagina onde vamos definir algumas informações importantes.
A primeira é o nome da nossa função. Vou colocar KipperNodeFunction mas você pode colocar o que achar melhor.
Escolha da Linguagem e Ambiente de Execução
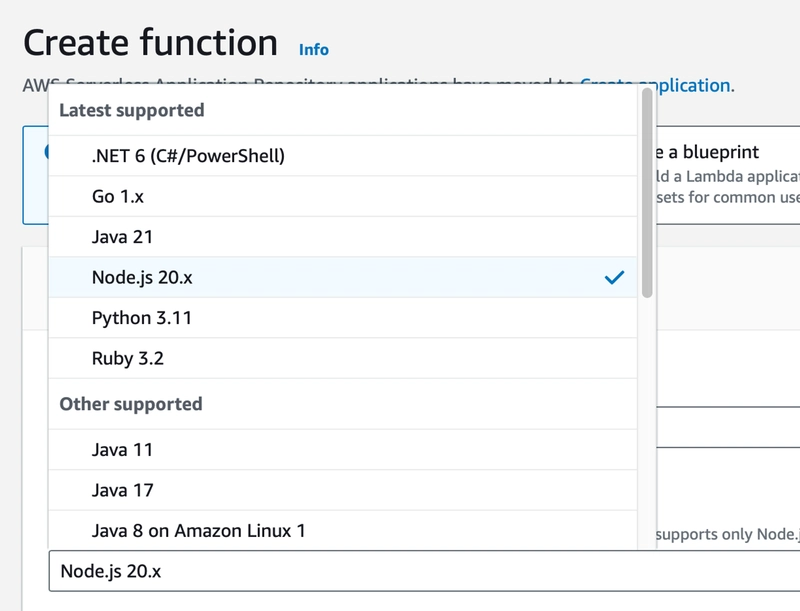
Na segunda opção definimos o ambiente de execução em que a nossa função será executada. A seleção do ambiente já determina qual a linguagem que usaremos (claro, até porque não tem como rodar JS em um ambiente .NET, por exemplo). Essa é uma das propriedade que a AWS usa para saber o que ela deve provisionar quando a nossa função for executada e nosso servidor precisar ser criado. Para o Node.js, o ambiente de execução que utilizaremos, a AWS oferece as versões 20, 18, 16 e 14. Mas também podemos utilizar um contêiner personalizado, se quisermos. A escolha do ambiente de execução correto é crucial para a execução eficiente da nossa função.
Ponto de Entrada
Para que a nossa função seja acessível pela internet, habilitar a URL é essencial. Isso nós podemos encontrar na seção de configurações avançadas. Ao habilitarmos essa opção, a nossa função será acionada quando a rota que nos será fornecida for acessada, servindo como o ponto inicial de execução. Quando uma função é acionada, ela recebe um objeto de evento e um objeto de contexto, fornecendo informações sobre o evento que chamou a função e todo o contexto envolvido. Eles acabam sendo dois parâmetros que são passados para a nossa função.
Aqui vai uma dica: é MUITO importante evitar código recursivo na nossa função, pois ele pode levar a chamadas infinitas e tempos de execução altíssimos, o que pode levar a contas extratosféricas. Além disso, o código recursivo acumula recursos de memória a cada chamada recursiva, aumentando ainda mais o uso de recursos e os nossos custos.
Na mesma seção também devemos habilitar o CORS para permitir que a nossa função seja executada a partir de qualquer origem.

Com a função criada, caímos no dashboard da nossa função e já temos um URL disponível para acessar, mas que por enquanto não faz nada…

Configuração de Gatilhos e Ações
O AWS Lambda pode ser configurado para acionar outros serviços da AWS ou serviços de terceiros. Além disso, também podemos fazer o inverso. Fazer com que outros serviços da AWS acionem a nossa função. Um uso interessante é na limpeza de Cache de CDN’s. Podemos configurar para que um outro serviço da AWS, chamado EventBridge Scheduler, execute a nossa Lambda uma vez ao dia e essa nossa Lambda estar configurada para invalidar o cache da nossa CDN. Assim, podemos ter uma limpeza de cache automatizada e sem provisionar um servidor pra isso.
Nosso código
Jogando a página um pouco mais para baixo, nós chegamos em uma seção onde conseguimos programar! É aqui que a mágica acontece, é essa função que é executada quando alguma requisição bate na URL que nós recebemos.
Boas práticas
-
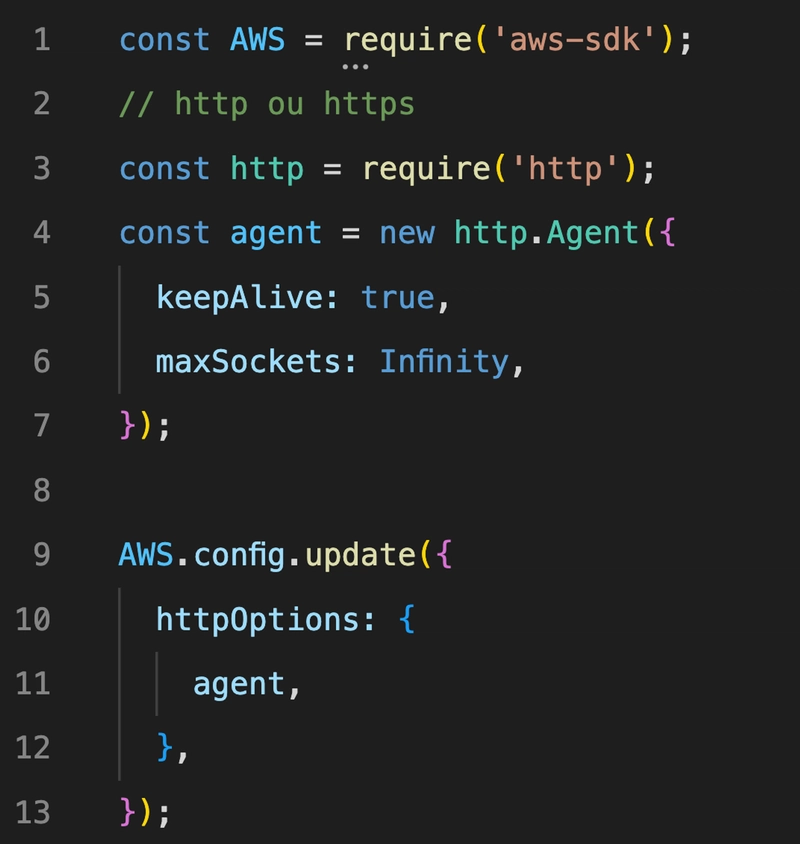
Criar um agente HTTP
Por padrão, a cada requisição o Node.js cria uma nova conexão TCP. Para evitarmos que isso aconteça sempre, podemos criar um agente HTTP customizado e definir o parâmetro
keepAlivecomo true. (Para saber mais, clique aqui)
-
Separar a lógica da função do handler principal
Outra dica muito importante é a separação da lógica da função e do handler da nossa função. Como podemos ver na imagem abaixo, ao separar as duas funções (poderíamos até separar em arquivos diferentes), temos o nosso código com uma uma função que pode ser testada de maneira unitária (testes unitários), o que faz aumentar a sua confiabilidade e nos garante o Separation of Concerns, um design pattern que diz que devemos separar a responsabilidade de cada função. Quase como o “S” de “SOLID” (link para algum outro post do NodeBR?).

-
NÃO USAR código recursivo!!!
Vou ressaltar a importância disso porque basta um simples bug que a nossa conta vais às alturas! Então, tomem MUITO cuidado com isso!
Vamos testar?
Abrindo o Postman, uma aplicação que basicamente executa requisições, podemos fazer uma chamada GET para o URL que nos foi fornecido e veremos que ele está retornando o resultado como esperado!

Permissões e Considerações de Segurança
Por fim, vale ressaltar que, ao configurar funções serverless na AWS, é crucial garantir que elas tenham apenas as permissões necessárias e restrições de acesso. Tipicamente, as funções serverless têm permissões limitadas e não têm acesso a outros serviços da AWS, como por exemplo nossas instâncias do EC2 ou arquivos no S3, a menos que sejam explicitamente concedidas.
Também é importante observar que a URL da função é pública e pode ser acessada sem autenticação nesse nosso caso, mas que também podemos configurá-la para que fique mais segura. Para isso, devemos habilitar a autenticação da nossa função, e dessa forma a AWS passará a controlar quem faz as chamadas da função, validando o token de autenticação enviado no header.
Conclusão
Neste artigo, destacamos como a integração das Lambda Functions da AWS com Node.js transforma o desenvolvimento de software. Esta combinação nos permite focar na lógica de negócios, eliminando a complexidade do gerenciamento de infraestrutura. Com Node.js, aproveitamos sua eficiência e flexibilidade, enquanto a AWS oferece uma infraestrutura gerenciada e escalável. Isso resulta em um processo de desenvolvimento mais ágil, eficiente e menos oneroso.
A sinergia entre Node.js e as funcionalidades serverless da AWS representa uma estratégia moderna de desenvolvimento. Essa abordagem não só agiliza a criação de software robusto e seguro, mas também atende às exigências de um mercado que demanda inovação rápida e soluções eficazes. Assim, desenvolvedores podem se dedicar inteiramente à entrega de valor, impulsionando o avanço tecnológico e a satisfação do usuário.

Top comments (3)
Show demais!
Parabéns pelo artigo .
👏🏻👏🏻👏🏻👏🏻🔥🔥🔥
Parabéns, ficou ótimo! Pensava que servless era um bicho de 7 cabeças, mas ta bem longe disso.
Oxe, é tão simples assim implementar funções servless na aws ? Que legal, ótimo artigo!