
Recursos
Esta implementación fue realizada gracias al trabajo colaborativo. El código fuente y los aportes de cada persona se encuentran en Github.
Introducción
Uno de los métodos más conocidos para la obtención de información desde sitios públicos en internet es el web scraping, que, a partir de diversos métodos como el uso de selectores css o expresiones regulares permite obtener los textos presentes en el HTML del sitio web.
En este caso, el objetivo de la implementación del web scraping es la obtención de títulos, descripciones, etiquetas, enlaces y "miniaturas" de vídeos publicados en la plataforma YouTube con fines netamente de aprendizaje.
Inicialmente, se realizaron 3 implementaciones en los lenguajes de programación Ruby (ver más información), JavaScript (ver más información) y Python (ver más información). A pesar de que las tres implementaciones requerían tiempos relativamente bajos para completar la recolección, se identificó una posible oportunidad de mejora utilizando el lenguaje Go, esto debido a su soporte para la concurrencia.
Implementación y resultados
Para la obtención de los datos requeridos se escogieron diferentes búsquedas (Ejm. How to create websites, Colombian music) y se obtuvieron, al menos, 140 enlaces de los vídeos resultantes de cada búsqueda empleando el paquete go-rod para inicializar un navegador sin interfaz gráfica (headless) y realizar de manera automática el scroll hasta tener el número mínimo de vídeos y obtener los enlaces.
El siguiente paso fue iterar los enlaces obtenidos y, con ayuda del paquete SizedWaitGroup, iniciar de manera concurrente la ejecución de funciones para obtener los datos de cada enlace. A pesar de que Go ofrece de manera estándar el paquete sync con el que se pueden crear WaitGroups, se optó por el paquete SizedWaitGroup para evitar el consumo excesivo de recursos al limitar el número de GoRoutines concurrentes.
Al modificar el límite de GoRoutines concurrentes, se obtuvieron los siguientes resultados:
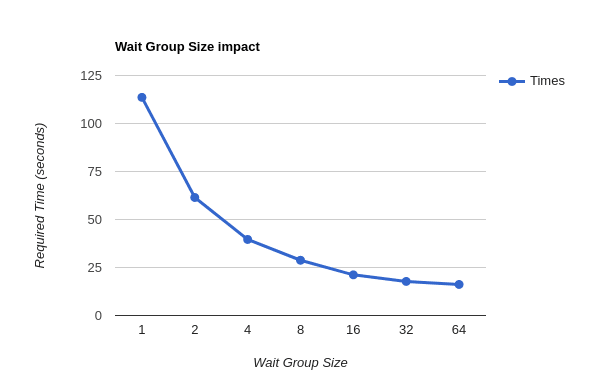
Como se observa en el gráfico, con tan solo pasar de una GoRoutine concurrente (Ejecución secuencial) a dos, el tiempo de ejecución se reduce de 113.6039s a 61.4714s, es decir, un 45.8897% apróximadamente, y al utilizar ocho GoRoutines, se reduce a 28.7748s, lo cual es 74.6709% menos en comparación al tiempo inicial.
Para finalizar, así se ven en la consola las ejecuciones con un límite de 1 y 8 GoRoutines respectivamente (Los primeros 20 segundos corresponden al tiempo para hacer el scroll con el web-driver`):


Referencias
- Google (2022) Sync, sync package - sync - Go Packages. pkg.go.dev. Available at: https://pkg.go.dev/sync (Accessed: October 28, 2022).
- Ionos (2020) ¿Qué es el web scraping?, IONOS Digital Guide. Ionos. Available at: https://www.ionos.es/digitalguide/paginas-web/desarrollo-web/que-es-el-web-scraping/ (Accessed: October 28, 2022).
- Manqueros, R. (2021) How to properly handle concurrency and parallelism with Golang. Medium. Available at: https://medium.com/analytics-vidhya/how-to-properly-handle-concurrency-and-parallelism-with-golang-89dd054b739f (Accessed: October 28, 2022).
- Nikolov, M.A. (2015) Concurrent map and slice types in go, Concurrent map and slice types in Go – Marin Atanasov Nikolov – A place about Open Source Software, Operating Systems and some random thoughts. Marin Atanasov Nikolov . Available at: https://dnaeon.github.io/concurrent-maps-and-slices-in-go/ (Accessed: October 28, 2022).
- Remeh (2019) Sizedwaitgroup, sizedwaitgroup package - github.com/remeh/sizedwaitgroup - Go Packages. pkg.go.dev. Available at: https://pkg.go.dev/github.com/remeh/sizedwaitgroup (Accessed: October 28, 2022).
- Skakun, V. (2022) The Best Programming Languages for Web Scraping. scrape-it. Available at: https://scrape-it.cloud/blog/web-scraping-languages (Accessed: October 28, 2022).

Top comments (0)