
Creating an HTTP web API endpoint by adding hardcoded SQL directly into your endpoint's method is the equivalent of cursing in church. I have worked with software developers who would become physically violent if I told them to do such a thing. However, let's stop and ask ourselves why this apparently is such a bad thing. I really can't see the problem here. Hence, put your SQL directly into your HTTP endpoint code.
There are tons of arguments against it, but once you really think about these, few of them makes much sense for most projects today. Once you've started implementing your project, it's highly unlikely you'll ever want to change database implementation from MySQL to PostgreSQL. So the argument of being able to exchange your database implementation is basically mute.
Using an ORM, especially in complex SQL, often results in sub optimal queries, so most of the time it's much better to manually construct your SQL than to use an ORM tool to abstract away your SQL. Sure, there exists valid arguments here related to caching, but caching is just as easily applied by leaning on functional constructs, and applying the SQL directly into the endpoint method.
Creating a database repository only results in that the code responsible for querying your database and the code responsible for returning the result to the client ends up in different places. This makes the code harder to navigate and maintain, and is quite frankly useless unless you need to reuse the same SQL code in multiple endpoints.
The more files you have to touch to maintain your code, the more difficult your code becomes to maintain
In fact, the idea that you need to create several abstractions between your endpoint and the database access layer is probably remnants of bad ideas originating from weaknesses in OOP. Once you're within a functional programming language, it's quite easy to put the actual SQL query directly inside the HTTP endpoint method, while still applying several layers of "abstractions" between your actual SQL code and the endpoint itself. This ensures that the code responsible for querying the database, and the code responsible for returning the result to the caller are in the same file, in the same method. This makes your project much easier to maintain and navigate. And if you need additional abstractions, you can use functional constructs to intercept the execution of your SQL, and the endpoint method itself.
Superstition
In Africa there's a migratory bird specie that will fly in a large circle every time they migrate. Zoologists couldn't figure out why, before they asked geologists for help. The behaviour originated from the fact that some 20 million years ago or something, there was a mountain there. The birds had to fly around the mountain to migrate, and this ended up becoming a part of their "survival of the fittest" strategy. Today the mountain has been gone for millions of years, but the birds still spends a lot of energy on taking huge detours. A lot of the things we do as software developers are similar types of remnants from a distant past, that made sense decades ago, but are no longer useful to us.
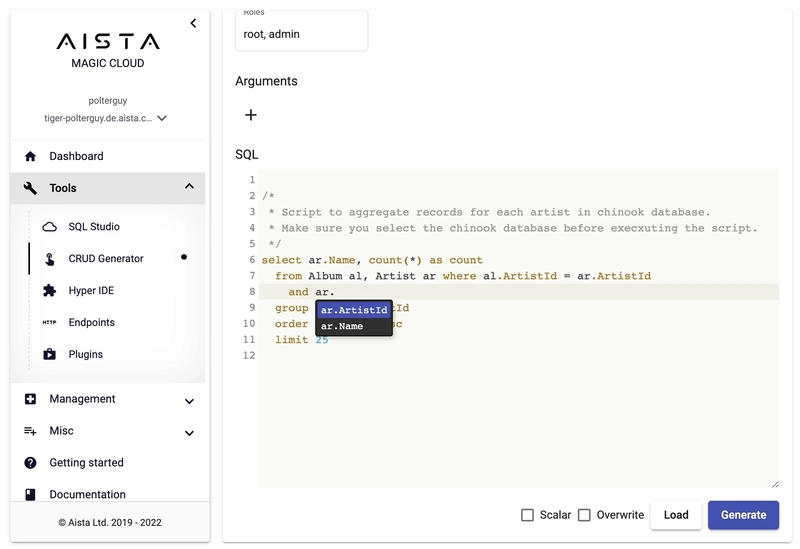
In Hyperlambda we even created GUI components to create SQL based HTTP web API endpoints. Above is a screenshot of the process. This allows any SQL guru to wrap his SQL inside an HTTP web API endpoint, without knowing any other languages but SQL. Below is a video where I walk you through the process.
Honestly, I cannot think of a single reason why the above is not a valid way to create at least some of your HTTP web API endpoints, interacting with your SQL database somehow. It takes care of SQL injections, it allows you to intercept the code and add additional layers of abstractions, it keeps the code clean and neat, it allows me to reuse the same Hyperlambda file in multiple projects if I want to, etc, etc, etc. If you want to reproduce what I'm doing in the above video, you can register a free trial cloudlet below.

Top comments (32)
Past week: You criticizing GraphQL for opening the entire model to an endpoint (which is wrong and falsy).
Today: Put your SQL into your HTTP endpoint code!
The next post I assume will one of those:
Assuming you're using authentication and authorisation, and you're using SQL parameters to avoid SQL injection attacks, what's wrong with this? Can you mention an example of where this might result in a a security breach?
The difference between GQL and what I propose, is that the query is created on the server. You not seeing the difference here is probably because you don't want to see the difference ...
i think it is for many, that they do not understand the article right. from the title, it seem you want to send sql with the request, like graphql. but query stay in backend 👍
That basically sums up the entirety of the difference yes ... ;)
Hi,
I changed my mind : I am allocating my time more on C# than Java now.
One subject that I immediately want to know in C# and .Net core is data access. The last time I worked with .Net using VB is via ADO.net. This time, the doc on both C# and .Net (Net Core) focus more on Entity Framework (EF) and LINQ that I am not familiar yet.
One thing that I want to know about these "new" tools is whether they provide Raw SQL. I am glad that they provide it : docs.microsoft.com/en-us/ef/core/q..., with explanation why they provide it.
As described in the doc, it provides a way for executing stored procedure that I still rely on for complex computation.
I hope my journey with EF and LINQ as well as with C# and .Net (including ASP.net Core) will be exciting, with additional motivation by the new tech called .Net MAUI that enables us to develop apps on different platforms : Windows, Mac, Android, iOS from a single code base : docs.microsoft.com/en-us/dotnet/ma...
Unfortunately, though, it requires at least Windows 10 release ?? (I don't remember the exact number) that I cannot try it soon.
Hi Alexander, that's correct every single PRM that I used in my life adds a way to execute raw queries. It can become convenient in critical building blocks.
If I may, why can't you install win 10?
My laptop spec is not adequate to install Win 10 or 11. Currently, I can even run in mode-safe with networking due to problems in normal mode. With all this restriction, I am thankful, at least, I can read docs from certain official docs, practice development using tools of interest.
Of course, I need an upgrade so that I can install Win 10. You know that Linux subsystem can only be installed in Win 10 or higher.
But it seems that I need to be patient until I can afford getting a new PC/laptop.
You can also install dotnet SDK and RE in Linux, I don't know if anything else is required for that specific framework but sure you can code C# .Net in Linux
Ah sorry... I mean, it's the .Net MAUI tech that requires Win 10/11.
As for .Net SDK (Net 5), it has been installed in my Win 7 (64 bit) about one year ago. So I have tried some code from the official textual tutorial, including how to build REST backend that serves React in frontend.
Other thing that motivated me more to use these Microsoft tech is : Internet of Things (IoT). I read, dotnet has library for IoT.
I haven't used anything but Mac for half a decade now, and I'm compiling C# every single day.
No offence, but you need to learn the basics first ...
Forget about Linux sub-system, install it natively ... ;)
Suggestion; Ubuntu ...
If I have another PC/Laptop, I will probably install CentOS.
Unless you want to "return to VB" - Hyperlambda is arguably "VB for the web" according to some of our users, which is a good thing for the record - You might want to check out Dapper. It's first of all up to 7 times faster on some things than EF, and it's also much "closer" to the way you used to do things with ADO.
Thank for your reply.
I think I can keep up with the new techs, so EF and LINQ are welcome. Only after grasping fundamentals, maybe I will take a look on Dapper.
The problem is that once you've taught yourself EF, you will (falsely) believe Dapper is inferior, and stick to EF, believing it's "better tech", while really it's worse tech ...
But go for it, just come back and read this comment 6 months down the road ... ;)
Where would you put the SQL other than in the end point? The function needs to talk to the database and it can only do this via a secure connection and using a language the database understands
HOWEVER....
Don't write raw SQL in your end points, use SELECT * FROM View, or EXECUTE sp_StoredProcedure @variable = 'value'
Why? Well a few reasons. The first is that the specialised code editor for your database is probably much better at intellisense and syntax highlighting for the database than the ide configured for c#, node python etc
Secondly your database IDE and tooling will likely come with dependency analysis and query optimization plans for that are more effective with code stored in the database. Dependency analysis cannot be done again code 'hidden' inside middleware (the same applies to reports and ETL solutions)
Thirdly your database is likely to be able to return data in JSON or XML so you may just be able to pass it through to the response
Fourth. The data extraction is an implementation detail and you should not need to be a database domain expert to manage it. If the database structure changes, this should not necessarily change the data returned to the API so you should not need to modify it
Finally the code can get really complex and a massive block of SQL will detract from the functional purpose and process of the API end point
In the same way as we break up components into separate files in the front end, the query to be executed is a stand alone component of the API so there is a good case to abstract it away to a separate file (or environment)
All your points are valid. However, I don't like adding too much business logic into the database besides basic referential integrity and similar stuff. As to point on, watch the YouTube video. SQL Studio and Hyper IDE pretty much completely invalidates this issue ...
depends on how you define business logic. If a customer can have a preferred contact address amongst many addresses and addresses are held in a table common to customers, suppliers and staff then I would argue that this is not business logic but is an implementation detail of the database structure and strategy. If a customer is on a credit stop and that is one of a number of pieces of data to be returned, that is business logic but the API should not be concerned about how that is calculated, that is the job of something else and it might as well be the database as it is 'closest to the metal' and can probably do it faster and with less bandwidth.
Very good points 😊
Actually a endpoint is not only about SQL Query. It can rely on some others microservice, it can validate stuff, send mail / notification / publish an event in a Kafka topic (😅😛). And those actions can be factorized on many endpoints so it's not that dumb to separate concerns.
All of the above can be easily implemented after the endpoint has been generated the way I do it in the video. As to Kafka ==> Here is my thought about Kafka ...
But yes, if you add too much BL in the endpoint, there are valid reasons to separate your concerns. However, if you don't need BL, there are no reasons to apply SoC, and adding it ads nothing but confusion ...
Indeed, no need to overengineer simple CRUD endpoints.
As to Kafka, I was teasing you 😁
:D
The superstition paragraph goes into my quote book :)
Thank you, I wish it was my discovery, unfortunately it was something I read somewhere - Can't remember where ...
Ok, I had to do a research because I was curious, could it be that you read about monarch butterflies? :)
It might be.
This reminds me that when you're using spring, you can enable the rest repositories from spring-data, so you have rest endpoints that are a direct "translation" from database
We built our entire CRUD API generator around that idea :)
I like to share where this concept is already teached to developers:
the fastify documentation
Interesting projects. Cute :)
Personally, I'd rather put brain cancer into my backend before I start typing it out in JavaScript, but I realise most disagree with me here. Ignoring the JS parts, it looks like a cute project ...