Take A Look At ML.NET

What is ML.NET?
ML.NET is a service from Microsoft that allows you to add machine learning to your existing applications. It requires very little setup and can use existing data in your database to start making predictions. If you've been curious about machine learning, but come from a .NET background then this might be a good starting point for you.
Machine learning has different types of predictions it can make based on the data you give it. Here is a list of what ML.NET can do out of the box along with a short description and an example or two.
| Prediction | Description | Example |
|---|---|---|
| Classification/Categorization | Divides records into categories or classifications. | Can determine if a message is mean or nice. |
| Regression/Predict continuous values | Predicts a value associated with some data. | Could count objects in an image. Could predict house prices based on size and location. |
| Anomaly Detection | Detects a piece of data that does not fit with the set. | Could determine if a collection of similar images has one that is very different. Could find a transaction that differs in a major way from the rest of a set. |
| Recommendations | Predicts a desired addition to a set based on the set contents. | Suggests additional products a shopper might want to buy. |
| Time series/sequential data | Makes predictions based on the order of previous data. | Weather forecasts, stock market predictions. |
| Image classification | Divides images into classifications | Can determine if an image is a hotdog 😂🌭 |
All of these seem to be tremendously useful and ML.NET makes it easy to start using them in your existing application using your existing data.
How Do I Get Started?
You've got to have the .NET Core 3.1 SDK installed on your computer (windows, linux or wsl or macOS)
It's super easy to start using ML.NET. You can set it up locally by running this command.
dotnet tool install -g mlnet
This worked really well in wsl bash, but I had some problems running it in Powershell. According to the docs, this will work in MacOS and Linux just fine though.
So for windows you may need to use the visual studio installer, where you select the .NET Core cross-platform development option and elect for ML.NET like so:
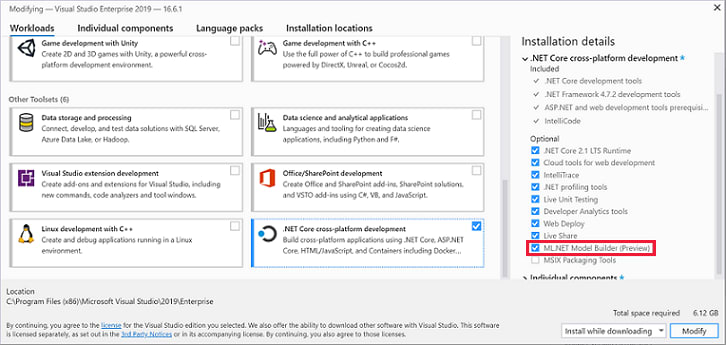
ML.NET Is Installed, Now What?
Now we can start thinking about how we want to use it.
Here is a snippet of code from the Microsoft Explanation.
static void Main(string[] args)
{
MLContext mlContext = new MLContext();
// 1. Import or create training data
HouseData[] houseData = {
new HouseData() { Size = 1.1F, Price = 1.2F },
new HouseData() { Size = 1.9F, Price = 2.3F },
new HouseData() { Size = 2.8F, Price = 3.0F },
new HouseData() { Size = 3.4F, Price = 3.7F } };
IDataView trainingData = mlContext.Data.LoadFromEnumerable(houseData);
// 2. Specify data preparation and model training pipeline
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
.Append(mlContext.Regression.Trainers.Sdca(labelColumnName: "Price", maximumNumberOfIterations: 100));
// 3. Train model
var model = pipeline.Fit(trainingData);
// 4. Make a prediction
var size = new HouseData() { Size = 2.5F };
var price = mlContext.Model.CreatePredictionEngine<HouseData, Prediction>(model).Predict(size);
Console.WriteLine($"Predicted price for size: {size.Size*1000} sq ft= {price.Price*100:C}k");
// Predicted price for size: 2500 sq ft= $261.98k
}
What Is This Code Doing?
- Here we cook up some training data about house sizes, providing a size and a price.
- We create a machine learning pipeline and tell it what to expect from the training data and how many times to go over it (This time it's a regression).
- We take our training data and throw it into the pipeline using the
Fitcommand. - We make up a new house size and feed it to the machine learning model and it spits out a price.
How Can We Use This?
Now, like most starting out examples, this is pretty trivial. In fact, as you read this you might be thinking "Why do I need machine learning for this? This is a very simple algorithm."
Ha, yeah, it is. However, we can continue to add additional properties to correlate, such as location. Also, real life data may not be so linear.
For me, when I saw this example I immediately started thinking about data I have worked with in various databases and how I could use that to start making predictions that would be useful for the business.
For example, I worked with a company that processed OARRS data in order to track prescription compliance for a patient. OARRS data is kept for patients who are prescribed controlled substances. Using ML.NET we could classify a patient into high or low risk categories based on prescription history. We could aggregate the prescription history for patients like so:
| List of current prescriptions | Span of time for continuous prescriptions in days | Number of unique prescription fill locations |
|---|
From there, we would need to pull from existing data whether or not a patient was compliant with their prescription instructions. This is something that the medical staff tracks as part of their counseling tasks. We can make a value judgement based on that data. A result of non-compliant would mean that "High Risk" and compliant would be "Low Risk". Using this, we can create a set of training data that more or less looks like this:
| Current prescriptions | Continuous prescriptions in days | Unique fill locations | Risk |
|---|---|---|---|
| methadone | 30 | 1 | Low |
| oxycontin | 100 | 5 | High |
| adderall | 1000 | 10 | Low |
| percocet | 200 | 2 | Low |
Lets say we save this aggregated anonymous data into a csv or tsv file.
Now, we can use the ML.NET command line tool to generate the code for us so we can adapt it into our application.
mlnet classification --dataset "anonymous-aggregate-prescription-data.tsv" --label-col "Risk" --train-time 60
The ML.NET tool will take the data saved in our file and attempt to predict the Risk column. We've specified that it should train on the data for 60 seconds, but really that time should be modified based on how big the dataset is. The bigger the data, the more time it should take.
Using the command line tool will also show the best machine learning algorithm to use, which is interesting and potentially helpful.
The tool will generate two projects, one will be a library that has a MLModel.zip file attached - the SampleClassification.Model project, and the other will be a console app where the model is consumed. The SampleClassification.ConsoleApp project.
Lets take a look at some code that would be spit out in the Model project. The tool will have generated two classes here, ModelInput class and a ModelOutput class. The ModelInput will be a representation of the above information sans the field to be predicted. The ModelOutput class has the field to be predicted and a float type value showing the percent certainty the algorthm made the prediction.
public class ConsumeModel
{
private static Lazy<PredictionEngine<ModelInput, ModelOutput>> PredictionEngine = new Lazy<PredictionEngine<ModelInput, ModelOutput>>(CreatePredictionEngine);
public static string MLNetModelPath = Directory.GetFiles(Directory.GetCurrentDirectory(), "MLModel.zip", SearchOption.AllDirectories).FirstOrDefault();
// For more info on consuming ML.NET models, visit https://aka.ms/mlnet-consume
// Method for consuming model in your app
public static ModelOutput Predict(ModelInput input)
{
ModelOutput result = PredictionEngine.Value.Predict(input);
return result;
}
public static PredictionEngine<ModelInput, ModelOutput> CreatePredictionEngine()
{
// Create new MLContext
MLContext mlContext = new MLContext();
// Load model & create prediction engine
ITransformer mlModel = mlContext.Model.Load(MLNetModelPath, out var modelInputSchema);
var predEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(mlModel);
return predEngine;
}
}
This is then consumed by the example console application like so:
class Program
{
static void Main(string[] args)
{
// Create single instance of sample data from first line of dataset for model input
ModelInput sampleData = new ModelInput()
{
Prescriptions: "methadone",
Days: 300,
Locations: 3
};
// Make a single prediction on the sample data and print results
var predictionResult = ConsumeModel.Predict(sampleData);
//predictionResult.Risk == "Low"
}
}
Moreover, as we continue to explore the SampleClassification.ConsoleApp we will also see it generate a ModelBuilder.cs using the algorithm that it had selected. We can adopt this code into our application to continuously refresh the model.
public static class ModelBuilder
{
private static string TRAIN_DATA_FILEPATH = @"/path-origina-training-data.tsv";
private static string MODEL_FILE = ConsumeModel.MLNetModelPath;
// Create MLContext to be shared across the model creation workflow objects
// Set a random seed for repeatable/deterministic results across multiple trainings.
private static MLContext mlContext = new MLContext(seed: 1);
public static void CreateModel()
{
// Load Data
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<ModelInput>(
path: TRAIN_DATA_FILEPATH,
hasHeader: true,
separatorChar: '\t',
allowQuoting: true,
allowSparse: false);
// Build training pipeline
IEstimator<ITransformer> trainingPipeline = BuildTrainingPipeline(mlContext);
// Train Model
ITransformer mlModel = TrainModel(mlContext, trainingDataView, trainingPipeline);
// Evaluate quality of Model
Evaluate(mlContext, trainingDataView, trainingPipeline);
// Save model
SaveModel(mlContext, mlModel, MODEL_FILE, trainingDataView.Schema);
}
public static IEstimator<ITransformer> BuildTrainingPipeline(MLContext mlContext)
{
// Data process configuration with pipeline data transformations
var dataProcessPipeline = mlContext.Transforms.Conversion.MapValueToKey("Risk", "Risk")
.Append(mlContext.Transforms.Text.FeaturizeText("Prescriptions", "Prescriptions") }))
.Append(mlContext.Transforms.Text.FeaturizeText("Days", "Days"))
.Append(mlContext.Transforms.Text.FeaturizeText("Locations", "Locations"))
.Append(mlContext.Transforms.Concatenate("Features", new[] { "Prescriptions", "Days", "Locations" }))
.Append(mlContext.Transforms.NormalizeMinMax("Features", "Features"))
.AppendCacheCheckpoint(mlContext);
// Set the training algorithm
var trainer = mlContext.MulticlassClassification.Trainers.OneVersusAll(mlContext.BinaryClassification.Trainers.AveragedPerceptron(labelColumnName: "Sentiment", numberOfIterations: 10, featureColumnName: "Features"), labelColumnName: "Risk")
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel", "PredictedLabel"));
var trainingPipeline = dataProcessPipeline.Append(trainer);
return trainingPipeline;
}
We can see where we could start pulling data from a database at the Load Data step, and start thinking about how frequently we might want to refresh this data.
And now, using this anonymous training data, the machine learning model can start making predictions about risk category for a patient based on their existing prescription history. All of this could be incorporated into an existing application by creating a machine learning service within it without any need to share potentially sensitive information with a cloud service.
For this example, I did not move forward with generating this service. While I think that making risk determinations from OARRS data could be interesting, and it's certainly possible, there are ethical concerns that would need to be considered before proceeding, such as: Do I need consent from patients to aggregate this data, even though it's anonymous? So this is all purely hypothetical based on applications I have worked on in the past.
Always be careful to consider the ethical ramifications of a machine learning project before diving into it.

Cool! How Do I Start With This?
I recommend doing the ML.NET tutorial from Microsoft. It will hit on some of the stuff covered here and will get you spun up with your own training data from wikipedia. The code examples in this blog are adapted from that tutorial.
Good luck and have fun!

Top comments (1)
Amazing article, well written. I am motivated to dive into ML.Net. Hope you don't mind me asking few questions in the next couple of days or weeks.
I have zero knowledge in ML but a strong background in C# DotNet so I just want to explore all that you've written here so as to get started with ML. Net