
FLUURT is the codename for the new compiler/runtime being built for the Marko UI Framework. The introductory article already gives a high level of what key features it delivers and why this could be of interest to you.
In this article, we will explore in detail the decision process in the designing of the new tag primitive syntax, which powers FLUURT's highly flexible reactive compositions. Some of the syntax might seem unusual at first but as you will see is important. It has as much of a profound effect on the developer experience as the library's ability to optimize.
This is still in the early development stage and may not be the final version. We're still open to suggestions and feedback.
Foundations
Marko has always seen itself as a superset of HTML. It was developed as a templating language originally and had more advanced features built on as it grew. This has meant a lot of really powerful ideas expressible right in the markup, but it also has meant inconsistencies and special rules.
We realized pretty early on if we wanted end users to leverage the full power of the language for themselves we'd need to iron these things out. So the exploration started from foundational HTML semantics.
Tags
Most things in Marko are tags. We support native built-in tags like <div> and <form>. We also have some Marko specific tags like <for> for iteration, <if> for conditional rendering, or <await> for async rendering. In addition, we support custom tags, like <my-tag>, which load in custom components. These components are user-defined templates much like your top-level application template, but can be reused throughout your application and are managed through Marko's runtime.
Attributes
Attributes are modifiers on tags, that serve as a way to provide input configuration. In the same way, Marko extends HTML's concept of tags, it extends attributes. In addition to strings, Marko supports JavaScript expressions assigned to attributes.

Constructing a language
Now, this alone is a powerful way to template apps. We have the ability to reuse our code as components and pass dynamic data around. However, HTML is missing the capability of a few other things we need to build out our core language.
What we really need to be able to do is bring function call semantics to HTML tags. This is a direction Marko has been going for a long time but we are only now really achieving it. We have attributes to serve as input, but we need to streamline the rest of the experience.
Tag Variables (return values)
Tags in our templates create DOM nodes, but we are limited thus far to passing things in. How do we get values out of our tags?
We can bind events. We can pass something down that the child can call or augment with their value. However between references to DOM nodes, or really any sort of data you'd want to pass we feel it is important to have this built in. Here's some potential example usage:

Why slash? Marko uses a lot of symbols already as part of its shorthand syntax. We knew we wanted a single end terminating symbol. Colon : actually seemed like the obvious choice until you consider our upcoming TypeScript support.

Now we could have overloaded attributes to handle this like most libraries. However, we prefer the clear grammar here, as it is concise, and as you will see this will be used for a number of tags.
The final piece is understanding how scope works. We've decided to use tag scope on variables. As in they are visible for siblings and all descendants. In cases where variables need to be hoisted to a higher level, you will need a separate declaration tag (more on that later).
Tag Parameters (callback/render props)
While it is possible to pass a function to a tag we need a way to handle rendering children. Marko and most template DSLs make a clear distinction between data and rendering. Instead of introducing a special control flow, Marko has introduced a mechanism for a component to call its child templates with data.
You see it commonly in control flow components.

In this example, item and index are provided by the parent component and only available to descendants. In this way, they differ from Tag Variables which are exposed to their siblings. This is important as the children can be rendered multiple times with different values.
Default Attribute
The last piece we realized might seem more like a bit of a syntax sugar than anything. But for conciseness sometimes it's better to just pass a single unnamed argument. Sometimes you don't need a bunch of named attributes. We have proposed using an assignment to a tag does exactly that:

However, this small convenience opens up a world of possibilities.
If you are familiar with Marko you may have heard of Tag Arguments, which were represented by
( ). The problem was they created a weird riff with typical attributes and introduced a new syntax only usable in Marko's built-in flow tags. The default attribute is something any tag can leverage.
Building our Primitives
With these additions to our language we now have the basis to describe a number of concepts not possible with only simple HTML. The core of which is the ability to create primitives for our state management. While this might seem sort of like JSX in HTML we actually are still much more restrictive. We are only allowing declarative statements. Yet we still carry the required flexibility to accomplish our goals.
The <let> tag
We decided to model the core state atom in our library in a way that would be familiar to JavaScript developers. let is a way of defining a changeable value in JavaScript and represents our core reactive atom.

The astute will notice that these are actually Tag Variables using the Default Attribute. You are passing the initial value to the <let> tag and returning the named variable.
These variables then can be used as expected in event handlers or as parts of definitions in other primitives.
The <const> tag
The <const> tag similarly, like in JavaScript, represents things that cannot be re-bound. In our case, that is static values and dynamic expressions. These serve as the fixed truths in our templating environment. We can statically analyze the difference between these cases based on usage to ensure the end-user doesn't have to worry about what updates.

It might take a bit to get used to the fact doubleCount in this example updates. However, it is consistent in that its relationship to count never changes.
The <effect> tag
The last core tag primitive is the effect tag. This is the mechanism the library has for producing side effects. Again we make use of the default argument.

Marko's effect automatically tracks reactive dependencies to update only when the affected state is updated. For that reason we also are proposing a <mount> tag that does not track dependencies and only runs when the portion of the template is mounted, and cleaned up when it is removed.
Putting it Together
The big win of all this is how extensible the approach is. When you write your own behaviors it's the exact same API for your consumers.

Basically, your imagination is the limit.
Marko has other syntaxes that I haven't gone over. Most importantly its mechanism for dynamic components and rendering child templates. These are important for authoring your own custom tags, but beyond the scope of what I'm covering here.
Instead, I want to focus on from a consumer standpoint what this means for development. What we end up with is the WYSIWYG of web authoring. In Marko, component imports are automatically detected. By co-locating our state at a template level, the composition is a hierarchical consideration.
So how about a comparison. I will use FLUURT's new syntax and compare it to Svelte, React Hooks, and React Classes. Consider a component that wraps a 3rd party chart that loads from a CDN on the page (1):
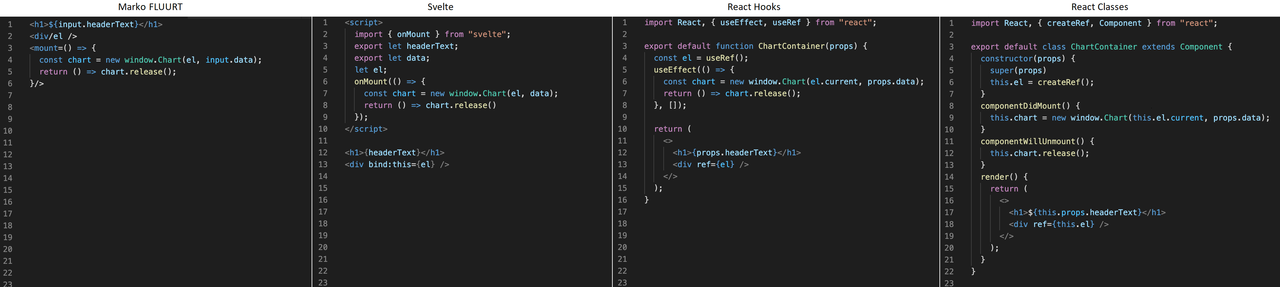
And now we are asked to add a new input to show and hide this chart. We can simply wrap it in an <if> tag, and lifecycles including disposal are automatically handled properly (2):
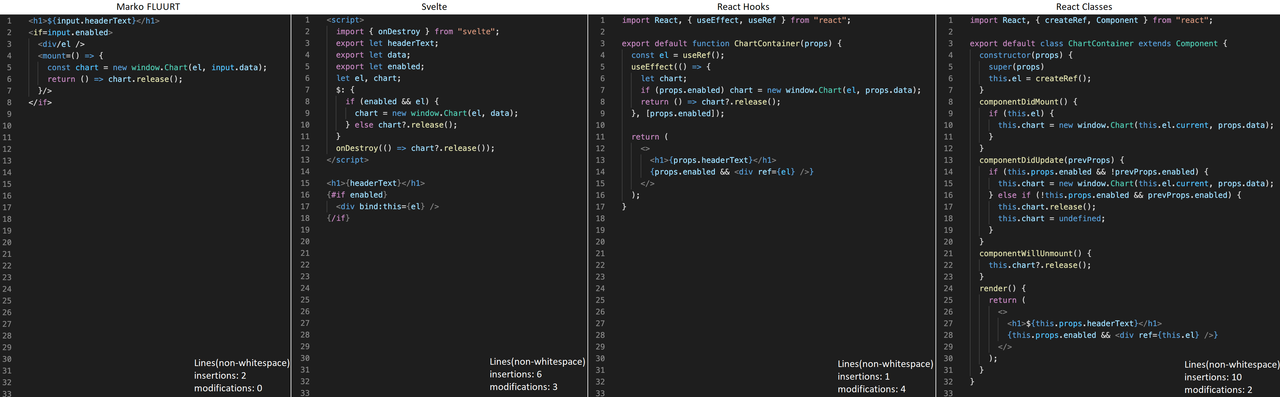
If we later wanted to break it apart into separate components we could just cut and paste our code into a new file, pass our input to our tag, and it would immediately work (3):

This is a trivial example, but that is all the code. I didn't need to even change anything when I moved it. Most importantly it scales the same way as your components get more complicated as this pattern of co-location extends throughout.
Conclusion
As you can see a lot goes into designing a language. It might start with identifying the right syntax but extends to understanding the implication of grammar and semantics. Our aim is to provide consistency in our extensibility. Not to have to say use $ in one place and function call somewhere else.
We believe this is essential to the powerful productive environment we wish to build. Writing less code isn't just about counting the lines of code in your git commit, but actually writing less code. Not only do these patterns lead to less initial code, but less refactoring overhead.
I encourage you to try the 3 step example from the previous section in the library of choice. You will need to apply the conditional in step 2 in multiple places. You will need to restructure your code to move it to a different file. Not to mention additional block wrappers and import statements.
These are the type of things you consider when designing a language. It goes beyond technical implementation or character count. It boils down to how effectively we can organize our thoughts and communicate our intent. And more so, with programming, recognize that it represents a living document, a continuing conversation, carried on by one or by many.
Overview of the Tags API:

Check out Marko on Github, Follow us on Twitter, or Join us on Discord to keep apprised of the latest updates.

Top comments (1)
This looks really exciting. I can't wait to try it once version 6 comes out!
It would be cool to see it work automatically with indexed db. But I guess I could write that myself pretty easily.
I think the most exciting thing for me - without having used it before - is that it is a template first approach and the amount of code that needs to be written is pretty small compared to the other frameworks (one thing that Svelte is proud of).