
Documentation remains a critical resource for developers, serving as the definitive guide and knowledge base for any software product or service. However, traditional keyword-based searches often fall short, delivering imprecise or irrelevant results. With the rise of Large Language Models (LLMs) and sophisticated AI solutions, semantic vector search has emerged as a powerful technology revolutionizing how developers interact with documentation.
In this deep, technical exploration, I will unravel how Docs AI search similar to Mintlify's feature works internally, emphasizing vector search powered by OpenAI's Agents SDK. I'll delve into the underlying mechanics, practical implementation, and specific developer-centric use cases.
Understanding Vector Search in Technical Context
Vector search represents textual data as numerical embeddings (vectors) capturing semantic meaning. Unlike conventional keyword-based search, vector search understands context and nuances, matching user queries to semantically similar documents rather than exact word matches.
Consider a developer query such as "How to deploy an app with Kubernetes?" Using vector embeddings, Docs AI returns relevant documents including terms like "app deployment," "Kubernetes orchestration," or even "containerized application launch."
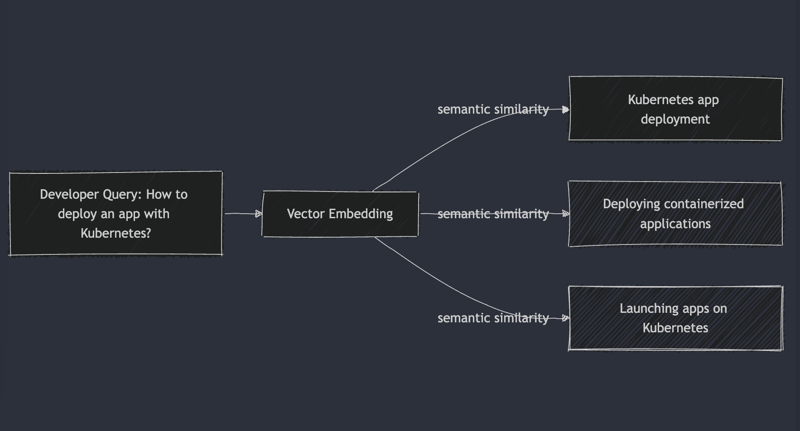
Why Docs AI Searches Exclusively Within Provided Documentation
Docs AI intentionally limits searches strictly to user-provided documentation, prioritizing the following principles:
- Precision: To provide highly accurate and contextually relevant answers directly from trusted sources.
- Data Privacy & Security: Protects sensitive data by avoiding reliance on external information.
- User Trust: Ensures consistent, reliable search outcomes without ambiguity from external sources.
Technical Implementation of Docs AI Using OpenAI's Agents SDK
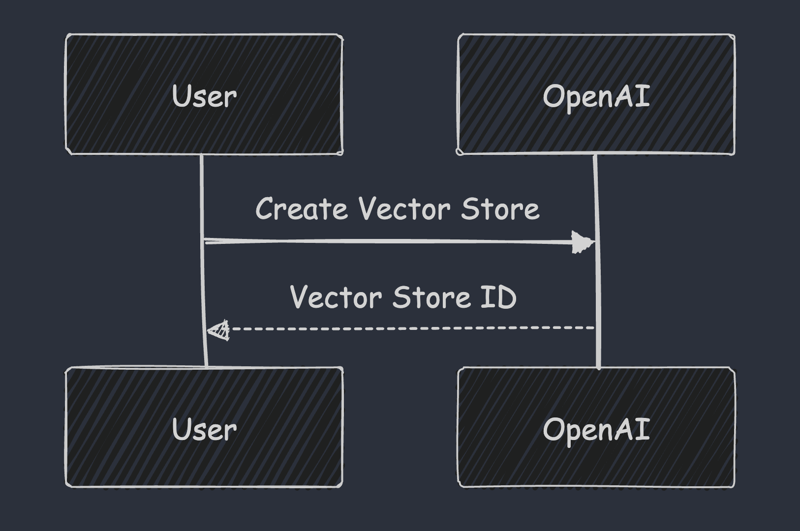
Step 1: Initializing a Vector Store
The first step involves creating a dedicated vector store, acting as your semantic search knowledge base:
from openai import OpenAI
client = OpenAI()
vector_store = client.vector_stores.create(name="devops_docs")
print(f'Vector Store ID: {vector_store.id}')
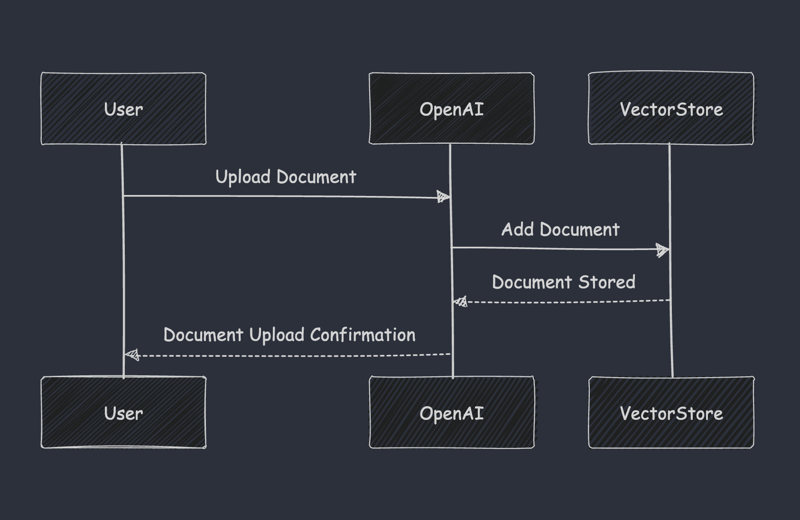
Step 2: Adding Documents to the Vector Store
Upload developer-focused documentation such as Kubernetes configuration guides, Docker best practices, or CI/CD pipeline examples:
import requests
from io import BytesIO
def upload_document(client, vector_store_id, target):
if target.startswith(("http://", "https://")):
response = requests.get(target)
file_content = BytesIO(response.content)
file_tuple = (target.split("/")[-1], file_content)
else:
file_tuple = open(target, "rb")
file_id = client.files.create(file=file_tuple, purpose="assistants").id
client.vector_stores.files.create(vector_store_id=vector_store_id, file_id=file_id)
return file_id
file_id = upload_document(client, vector_store.id, "https://example.com/k8s-deployment.pdf")
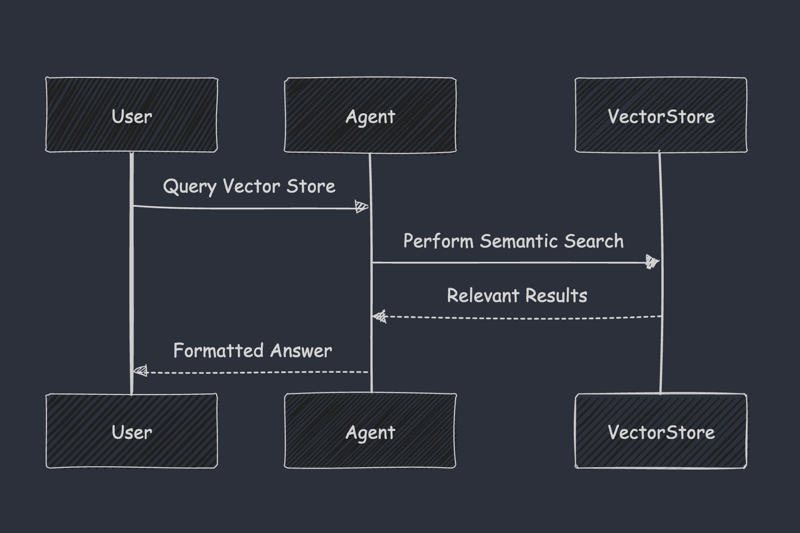
Step 3: Semantic Search with OpenAI's Agents SDK
Querying the vector store to retrieve precise, relevant results based on semantic understanding:
from agents import Agent, Runner, FileSearchTool
agent = Agent(
name="DevOpsAgent",
tools=[
FileSearchTool(max_num_results=3, vector_store_ids=[vector_store.id]),
],
)
result = Runner.run_sync(agent, "How to configure autoscaling in Kubernetes?")
print(result.final_output)
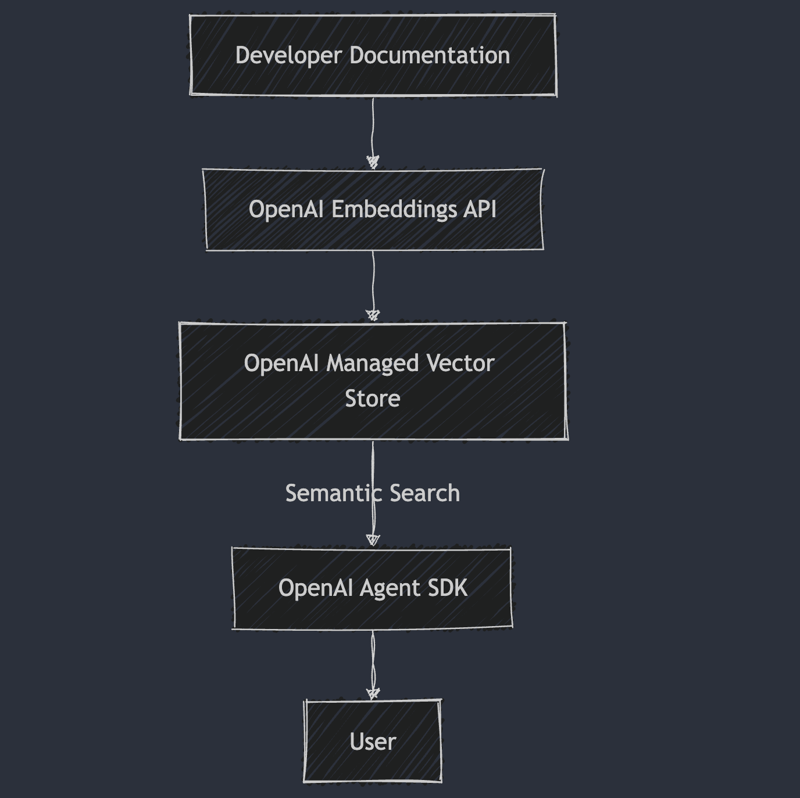
Technical Architecture of Docs AI Search
- Embeddings via OpenAI: Documents are transformed into vector embeddings capturing rich semantic context.
- Managed Vector Store: Efficient storage and retrieval of document embeddings, facilitating fast semantic search.
- Agents SDK: Intelligent semantic search interactions to provide developers quick and contextually accurate answers.
Empathy in Engineering Docs AI Search
Empathy-driven engineering ensures Docs AI addresses genuine developer pain points:
- Context-Aware Responses: Strictly rely on provided documentation to avoid misleading information.
- Transparency: Clearly communicate the bounds of searchable data, enhancing developer trust.
- Clear Communication of Limitations: Explicitly indicate when information is unavailable, enabling developers to take alternative actions confidently.
Maintaining Search Integrity
Effective maintenance of document repositories, including removing outdated or incorrect documentation, preserves the reliability of search outcomes:
client.vector_stores.files.delete(vector_store_id=vector_store.id, file_id=file_id)
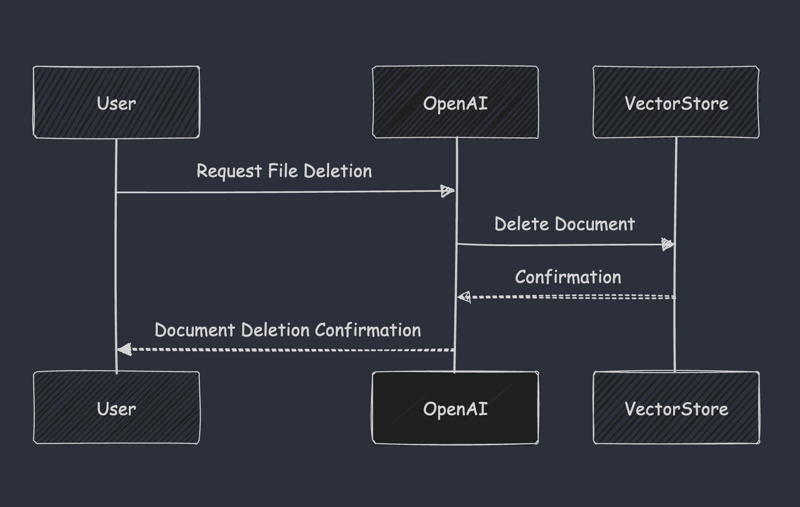
After removal, searches transparently communicate the updated knowledge base status.
Potential Extensions for Enhanced Developer Experience
Future enhancements can include integration with real-time CI/CD logs, automatic documentation synchronization via APIs, and multi-modal embedding searches (combining text with visual content such as architecture diagrams).
For more tips and insights, follow me on Twitter @Siddhant_K_code and stay updated with the latest & detailed tech content like this.

Top comments (0)