This post explains why structured debugging is hard; and introduces a method to make this process more straightforward. However, before that, we first need to introduce a basic mental model about software development, which will serve us as an analogy for later.
A Mental Model: How We Develop Software
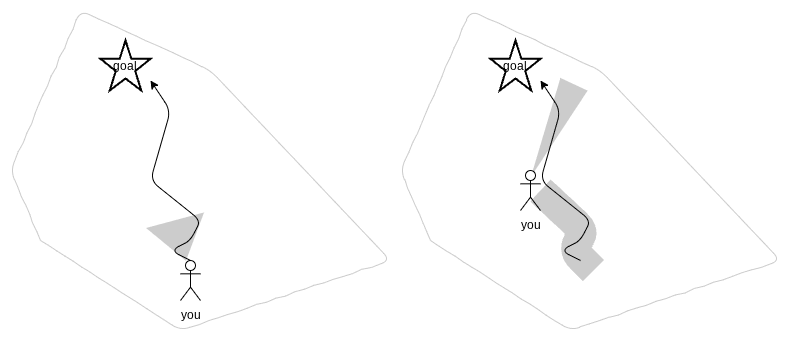
Usually, when we start developing inside an existing, bigger application, I feel this process resembles a lot exploring an unchartered island. At the beginning, we only roughly know what we want to archive, but we do not know yet how to reach that goal. We have to first explore our nearby environment.
Then, we go a few steps, and adjust our course as we go. At first, the steps we take are rather small; but then steps will become bigger as we know more and more about our island (depicted by the big gray area trailing behind you) and are thus able to make more correct assumptions about how the system behaves.
Thus, over time, we are improving our development speed because our assumptions are getting better and better; and thus we can go multiple steps at once, before validating them all together by trying out the application again. Turns out this will become a problem lateron when we start debugging.
Developing in big existing applications is like charting a previously unchartered island.
Debugging Unexpected Behavior
When an unexpected behavior happens, I often see people poking around; often changing various parameters at once before re-running the application. Basically, we this is what happens when we apply our thinking of efficient software development (see above) to debugging - but this leads us to a totally wrong path.

We basically think "we know how the system will behave" - and thus, we are going too far at once; hitting walls (depicted in orange) which do not lead us to our solution. When one of these routes does not work, we start again from scratch and retry a different direction - however again going too far into the other direction as well. The problem: By doing this, we do not learn anything new about our system anymore (we just become confused).
We need to apply another kind of thinking to solve this debugging challenge. Let's assume for a second we did not know anything about our software when we hit a behavior violating our assumptions. How could we progress then?
The Solution: Design Experiment; Run it; Analyze; Repeat
We could assume our system is a black, opaque box, which we do not understand. Now, let's apply what a scientist would do to understand it better:
- Design an experiment which divides the problem space at around 50%, to figure out whether our unexpected behavior resides in the left or the right half of the problem space. It is important that this experiment returns definitive answers (and no assumptions and no probabilities). This is depicted with the blue line and the A/B sections in the image above.
- Run the experiment.
- Analyze the experiment results. You should now know definitely at which part of the problem space your unexpected behavior occurs.
- Repeat with a new experiment, again bisecting the relevant part of the problem space again.
Of course, even when doing this,it can happen that an experiment fails without yielding good results. Then, you need to understand that this has happened and design a new experiment, basically discarding the old experiment.
Practical Hints
- Designing good experiments is the hardest part of the process above.
- Designing good experiments needs some experience; and you will see this gets easier over time.
- When you start with designing experiments, you should explicitely write down the experiment's assumption which should be validated or falsified. Furthermore, write down the experiment setup.
- For systems consisting of multiple coarse components, it is usually a good start to create an experiment to isolate which component is responsible for the unexpected behavior – so first bisecting at component boundaries is a good start. For client-server webapps, this means first figuring out whether the client-side portion of the application or the server-side portion of the application is responsible for the unexpected behavior.
Closing Thoughts
Basically, when developing, you want to understand as much as possible from the system; so I call this White-Box Thinking. On the other hand, when debugging, you often need Black-Box Thinking. Switching between the two is often difficult; I hope this essay can help to make this a little easier.
Looking forward to your feedback,
Sebastian
PS: This is quite similar to the behavior of git bisect: In case you need to figure out when a certain regression has entered your codebase, you can use this to identify the commit since when the problem existed.
PPS: This essay has been first published at our company blog.

Top comments (0)