
Big data is a new age concept that has emerged as a result of the massive expansion in information collected over the past two decades due to the rapid advancements in information and communications technologies. According to estimates, sensors, mobile devices, online transactions, and social networks generate almost three billion bytes of data per day, with 90% of the world's data having been produced in the last three years alone.
As a result of the difficulties associated with storing, organizing, and comprehending such a vast amount of data, new technologies in the fields of statistics, machine learning, and data mining have been developed. These technologies also interact with fields of engineering and artificial intelligence (AI), among others.

This massive endeavor resulted in the development of the new multidisciplinary subject known as "Data Science," whose concepts and methods aim to automatically extract potentially usable knowledge and information from the data.
Now looking specifically towards it's applications in economics. It is crucial for all governments, international organizations, and central banks to keep an eye on the economy's present and future conditions. To create effective policies that can promote economic growth and protect societal well-being, policymakers need readily accessible macroeconomic information.
Key economic statistics, on which they base their decisions, are created seldom, released with long delays—the European Union's Gross Domestic Product (GDP) is released after about 45 days—and frequently undergo significant adjustments. Economic nowcasting and forecasting are in fact exceedingly difficult undertakings because economists can only roughly estimate the current, future, and even very recent past economic conditions with such a little amount of information.
In a global interconnected world, shocks and changes originating in one economy move quickly to other economies affecting productivity levels, job creation, and welfare in different geographic areas. In sum, policy-makers are confronted with a twofold problem: timeliness in the evaluation of the economy as well as prompt impact assessment of external shocks.
In this blog post let us explore a few ways we are able to apply these new age concepts in something so essential for our societies functioning.
Technical Challenges
The number of devices that provide information about human and economic activities has significantly expanded in recent years as a result of technology advancements (e.g., sensors, monitoring, IoT devices, social networks). These new data sources offer a vast, regular, and varied amount of data, allowing for precise and timely estimates of the economy's status. Such data are large and diverse, making it difficult to collect and analyze them. However, if correctly utilized, these new data sources might offer more predictive potential than the conventional regressors employed in economic and financial analysis in the past.
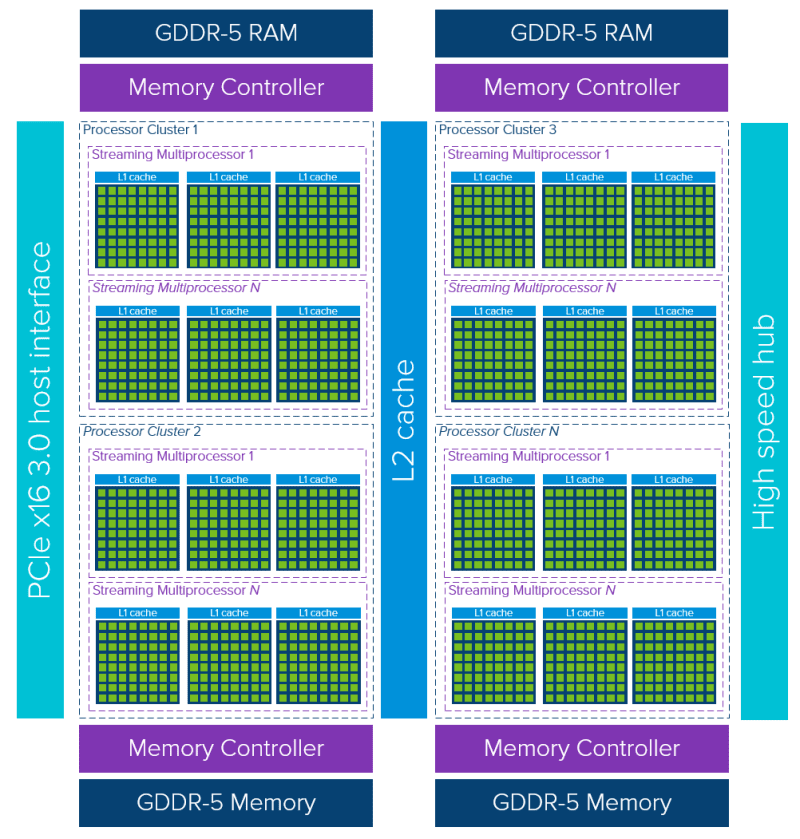
Since in this instant the sheer amount of data is large and varied, analysing them needs machines that have great computing power. In recent years we have seen unimaginable amount of increase in computing power.
For instance, cloud computing systems and Graphical Processing Units (GPUs) have recently grown more accessible and popular. It is possible to program GPUs' highly data-parallel design utilizing frameworks like CUDA and OpenCL.
They are made up of several cores, each of which has several functional components. Each thread of execution is processed by one or more of these functional units, also referred to as thread processors. As they share a common control unit, all thread processors in a GPU core execute the same instructions.
Another key requirement for the successful utilization of new data sources for economic and financial analysis is accessibility. To protect sensitive information, it is frequently restricted in practice.
Data stewardship, a concept that includes properly gathering, annotating, and archiving information as well as providing "long-term care" for data that may be used in future applications and combined with new data, is frequently used to describe striking a balance between accessibility and protection.
Individual-level credit performance data is an obvious example of sensitive information that might be highly helpful in economic and financial analysis but whose access is frequently limited for data protection reasons.
Financial institutions could gain from improved credit risk models that more accurately identify risky borrowers and reduce the potential losses associated with a default.
Consumers could have easier access to credit thanks to the effective allocation of resources to dependable borrowers and governments and central banks could monitor the state of their economies by check in real-time. Online data sets containing individual-level data that has been anonymised abound.
Data Analytics Methods
In order to manage and maintain massive data structures, such as raw logs of user actions, natural language from conversations, photos, videos, and sensor data, traditional nowcasting and forecasting economic models are not dynamically scalable. New tool sets are needed in order to handle this large volume of data in its naturally complex high-dimensional formats for economic analysis. In actuality, when data dimensions are large or expanding quickly, traditional methodologies do not scale effectively.
Simple activities like data visualization, model fitting, and performance evaluation become challenging. In a big data context, traditional hypothesis testing that sought to determine the significance of a variable in a model (T-test) or to choose one model over several alternatives (F-test) must be utilized with care.
Social scientists can use data science approaches in these situations, and in recent years, efforts to have those applications acknowledged in the economic modeling community have expanded tremendously. The development of interpretable models and the opening up of black-box machine learning solutions constitute a focal point.
In fact, when data science algorithms prove to be rarely understandable despite being easily scalable and extremely performant, they are useless for policy-making. To achieve the level of model performance, interpretability, and automation required by the stakeholders, good data science applied to economics and finance requires a balance across these dimensions and often entails a combination of domain expertise and analysis tools. So now let us take a look at methods that help us achieve these feats.
Deep Learning Machine
While Support Vector Machines, Decision Trees, Random Forests, and Gradient Boosting have been around for a while, they have shown a great potential to tackle a variety of data mining (e.g., classification, regression) problems involving businesses, governments, and people.
Deep learning is currently the technology that has had the most success with both researchers and practitioners. A set of machine learning techniques based on learning data representations (capturing highly nonlinear correlations of low level unstructured input data to construct high level concepts) are known as deep learning, which is a general-purpose machine learning technology.
Deep learning approaches made a real breakthrough in the performance of several tasks in the various domains in which traditional machine learning methods were struggling, such as speech recognition, machine translation, and computer vision (object recognition).
The advantage of deep learning algorithms is their capability to analyze very complex data, such as images, videos, text, and other unstructured data.

- Artificial neural networks (ANNs) with deep structures, such as Deep Restricted Boltzmann Machines, Deep Belief Networks, and Deep Convolutional Neural Networks, are examples of deep hierarchical models. ANN are computational tools that can be seen as applying the framework of how the brain works to build mathematical models.
Using input data, neural networks estimate functions of any complexity. An input vector to output vector mapping is represented using supervised neural networks. Instead, unsupervised neural networks are utilized to categorize the input without already knowing which classes are involved.
Deep learning has already been used in the field of finance, for example, to predict and analyze the stock market. The Dilated Convolutional Neural Network, whose core architecture derives from DeepMind's WaveNet project, is another successful ANN method for financial time-series forecasting. the work on time series-to-image encoding and deep learning for financial forecasting utilizes a group of convolutional neural networks that have been trained on pictures of Gramian Angular Fields made from time series related to the Standard & Poor's 500 Future index with the goal of predicting the direction of the US market in the future.
- Reinforcement learning, which is based on a paradigm of learning via trial and error, purely from rewards or penalties, has gained prominence in recent years alongside deep learning.
It was effectively used in ground-breaking inventions like Deep Mind's AlphaGo system, which defeated the best human player to win the Go game. It can also be used in the economics field, for example, to trade financial futures or to dynamically optimize portfolios.
These cutting-edge machine learning methods can be used to understand and relate data from several economic sources and find undiscovered correlations that would go undetected if only one source of data were taken into account. For instance, merging information from text and visual sources, such as satellite imagery and social media, can enhance economic forecasts.
Semenatic Web Technologies
Textual data is considered to be part of the so-called unstructured data from the perspectives of data content processing and mining.
Learning from this kind of complicated data can provide descriptive patterns in the data that are more succinct, semantically rich (Semantic: refers to the study of the meaning of data and how it can be processed, analyzed, or understood by machines or algorithms), and better reflect their underlying characteristics. Natural Language Processing (NLP) and information retrieval technologies from the Semantic Web have been developed to make it simple to retrieve a plethora of textual data.
A system called the Semantic Web, sometimes known as "Web 3.0," enables robots to "understand" and reply to complicated human requests based on their meaning. Such a "understanding" necessitates semantically structured knowledge sources.
By providing a formal description of concepts, terms, and relationships within a given knowledge domain and by using Uniform Resource Identifiers (URIs), Resource Description Framework (RDF), and Web Ontology Language (OWL), whose standards are maintained by the W3C. Linked Open Data (LOD) has gained significant momentum over the past years as a best practice for promoting the sharing and publication of structured data on the Semantic Web.
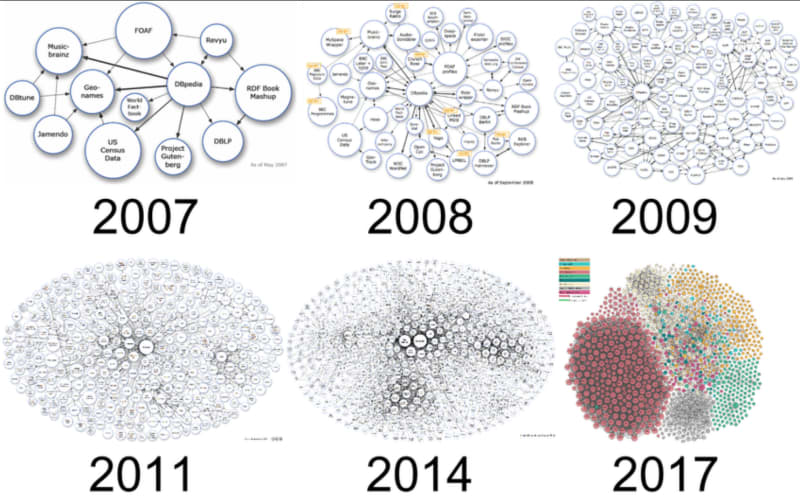
LOD makes it possible to use data from several areas for publications, statistics, analysis, and mapping. By connecting this knowledge, associations and interrelations can be deduced, and fresh conclusions can be reached.
Since more and more data sources are being published as semantic data, RDF/OWL enables the production of triples about anything on the Semantic Web.
The decentralized data space of all the triples is expanding at an astounding rate. However, the Semantic Web's growing complexity is not solely a function of its size. The Semantic Web has become a complicated, large system due to its distributed and dynamic nature, coherence problems across data sources, and reasoning-based interaction across the data sources.
Conclusion
The application of data science to economic and financial modeling has been covered in this blog post. The main big data management infrastructures and data analytics methods for prediction, interpretation, mining, and knowledge discovery activities have been discussed, along with challenges including economic data handling, amount, and protection. We outlined a few typical big data issues with economic modeling and pertinent data science techniques.
The development of data science methodologies that enable closer collaboration between humans and machines in order to produce better economic and financial models has an obvious need and great potential. In order to improve models and forecasting quality, these technologies can handle, analyze, and exploit the collection of extremely varied, interconnected, and complex data that already exists in the economic universe with a guarantee on the veracity of information, a focus on producing actionable advice, and an improvement in the interactivity of data processing and analytics.
If you came this far, Thanks for reading the whole blog through, hopefully you have employed this time in learning newer concepts. I would love to read further and post about topics in detail if you people would like to read my interpretations of them. Thank you again and this is me Arjun Ramaswamy sigining out.

Top comments (0)