
Last week, I wrote about the importance of properly handling user input in our websites and applications. I alluded to an overarching security lesson that I hope to make explicit today: the security of our software, application, and customer data is built from the ground up, long before the product goes live.

The OWASP Top 10 is a comprehensive guide to web application security risks. It is relied upon by technology professionals, corporations, and those interested in cybersecurity or information security. The most recent publication lists Sensitive Data Exposure as the third most critical web application security risk. Here’s how the risk is described:
Many web applications and APIs do not properly protect sensitive data, such as financial, healthcare, and PII. Attackers may steal or modify such weakly protected data to conduct credit card fraud, identity theft, or other crimes. Sensitive data may be compromised without extra protection, such as encryption at rest or in transit, and requires special precautions when exchanged with the browser.
“Sensitive Data Exposure” is a sort of catch-all category for leaked data resulting from many sources, ranging from weak cryptographic algorithms to unenforced encryption. The simplest source of this security risk, however, takes far fewer syllables to describe: people.
The phrase “an ounce of prevention is worth a pound of cure,” applies to medicine as well as secure software development. In the world of the latter, this is referred to as “pushing left,” a rather unintuitive term for establishing security best practices earlier, rather than later, in the software development life cycle (SDLC). Establishing procedures “to the left” of the SDLC can help ensure that the people involved in creating a software product are properly taking care of sensitive data from day one.
Unfortunately, a good amount of security testing often seems to occur much farther to the right side of the SDLC; too late for some security issues, such as sensitive data leakage, to be prevented.
I’m one of the authors contributing to the upcoming OWASP Testing Guide and recently expanded a section on search engine discovery reconnaissance, or what the kids these days call “Google dorking.” This is one method, and arguably the most accessible method, by which a security tester (or black hat hacker) could find exposed sensitive data on the Internet. Here’s an excerpt from that section (currently a work in progress on GitHub, to be released in v5):
Search Operators
A search operator is a special keyword that extends the capabilities of regular search queries, and can help obtain more specific results. They generally take the form of
operator:query. Here are some commonly supported search operators:
site:will limit the search to the provided URL.inurl:will only return results that include the keyword in the URL.intitle:will only return results that have the keyword in the page title.intext:orinbody:will only search for the keyword in the body of pages.filetype:will match only a specific filetype, i.e. png, or php.For example, to find the web content of owasp.org as indexed by a typical search engine, the syntax required is:
site:owasp.org…
Google Hacking, or Dorking
Searching with operators can be a very effective discovery reconnaissance technique when combined with the creativity of the tester. Operators can be chained to effectively discover specific kinds of sensitive files and information. This technique, called Google hacking or Google dorking, is also possible using other search engines, as long as the search operators are supported.
A database of dorks, such as Google Hacking Database, is a useful resource that can help uncover specific information.
Regularly reviewing search engine results can be a fruitful task for security testers. However, when a search for site:myapp.com passwords turns up no results, it may still be a little too early to break for lunch. Here are a couple other places a security tester might like to look for sensitive data exposed in the wild.
Pastebin
The self-declared “#1 paste tool since 2002,” Pastebin allows users to temporarily store any kind of text. It’s mostly used for sharing information with others, or retrieving your own “paste” on another machine, perhaps in another location. Pastebin makes it easy to share large amounts of complicated text, like error logs, source code, configuration files, tokens, api keys… what’s that? Oh, yes, it’s public by default.
Here are some screenshots of a little dorking I did for a public bug bounty program.
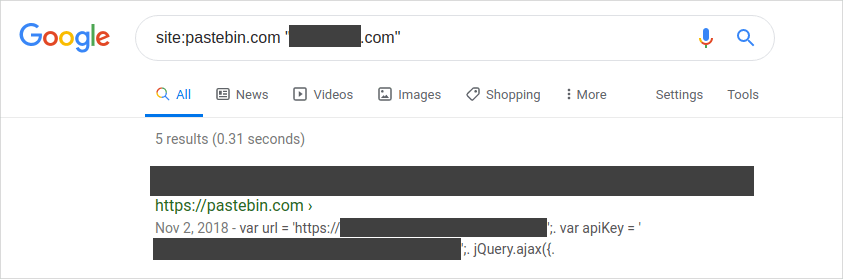
API keys in plain view.

Log-in details out in the open.
Thanks in part to the convenience of using Pastebin and similar websites, it would appear that some people fail to think twice before making sensitive data publicly available.
But why?
Granted, non-technical employees with access to the application may not have an understanding of which items should or should not be freely shared. Someone unfamiliar with what encrypted data is or what it looks like may not realize the difference between an encrypted string and an unencrypted token made up of many random letters and numbers. Even technical staff can miss things, make mistakes, or act carelessly after a hard day at work. It may be easy to call this a training problem and move on; however, none of these rationalizations address the root cause of the issue.
When people turn to outside solutions for an issue they face, it’s usually because they haven’t been provided with an equally-appealing internal solution, or are unaware that one exists. Employees using pastes to share or move sensitive data do so because they don’t have an easier, more convenient, and secure internal solution to use instead.
Mitigation
Everyone involved in the creation and maintenance of a web application should be briefed on a few basic things in regards to sensitive data protection:
- what constitutes sensitive data,
- the difference between plain text and encrypted data, and
- how to properly transmit and store sensitive data.
When it comes to third-party services, ensure people are aware that some transmission may not be encrypted, or may be publicly searchable. If there is no system currently in place for safely sharing and storing sensitive data internally, this is a good place to start. The security of application data is in the hands of everyone on the team, from administrative staff to C-level executives. Ensure people have the tools they need to work securely.
Public repositories
Developers are notorious for leaving sensitive information hanging out where it doesn’t belong (yes, I’ve done it too!). Without a strong push-left approach in place for handling tokens, secrets, and keys, these little gems can end up in full public view on sites like GitHub, GitLab, and Bitbucket (to name a few). A 2019 study found that thousands of new, unique secrets are leaked every day on GitHub alone.
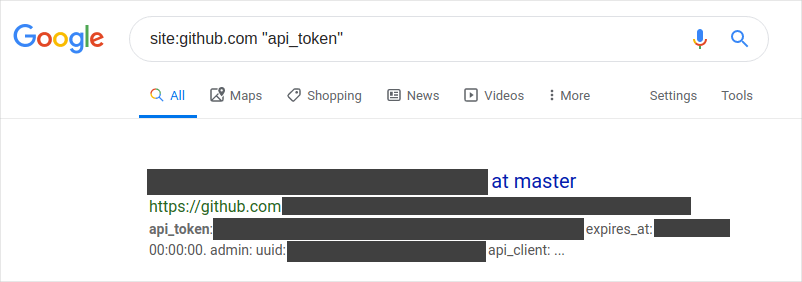
GitHub has implemented measures like token scanning, and GitLab 11.9 introduced secret detection. While these tools aim to reduce the chances that a secret might accidentally be committed, to put it bluntly, it’s really not their job. Secret scanning won’t stop developers from committing the data in the first place.
But why?
Without an obvious process in place for managing secrets, developers may tend too much towards their innate sense of just-get-it-done-ness. Sometimes this leads to the expedient but irresponsible practice of storing keys as unencrypted variables within the program, perhaps with the intention of it being temporary. Nonetheless, these variables inevitably fall from front of mind and end up in a commit.
Mitigation
Having a strong push-left culture means ensuring that sensitive data is properly stored and can be securely retrieved long before anyone is ready to make a commit. Tools and strategies for doing so are readily available for those who seek them. Here are some examples of tools that can support a push-left approach:
- Use a management tool to store and control access to keys and secrets, such as Amazon Key Management Service or Microsoft’s Azure Key Vault.
- Make use of encrypted environment variables in CI tools, such as Netlify’s environment variables or virtual environments in GitHub Actions.
- Craft a robust
.gitignorefile that everyone on the team can contribute to and use.
We also need not rely entirely on the public repository to catch those mistakes that may still slip through. It’s possible to set up Git pre-commit hooks that scan for committed secrets using regular expressions. There are some open-source programs available for this, such as Talisman from ThoughtWorks and git-secrets from AWS Labs.
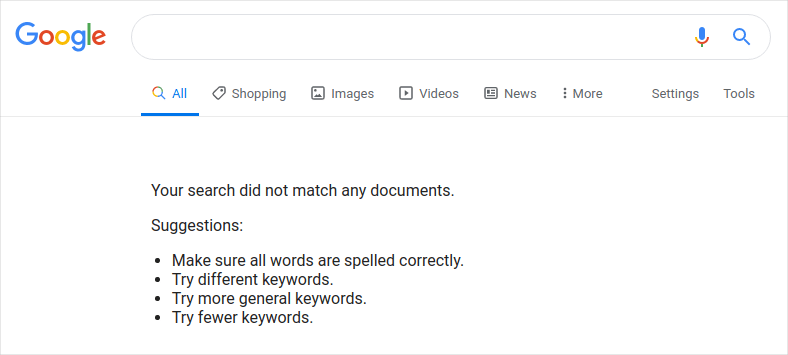
Pushing left to prevent sensitive data exposure
A little perspective can go a long way in demonstrating why it’s important to begin managing sensitive data even before any sensitive data exists. By establishing security best practices on the left of the SDLC, we give our people the best chance to increase the odds that any future dorking on our software product looks more like this.
Another great resource for checking up on the security of our data is Troy Hunt’s Have I Been Pwned, a service that compares your data (such as your email) to data that has been leaked in previous data breaches.
To learn about more ways we can be proactive with our application security, the OWASP Proactive Controls publication is a great resource. There’s also more about creating a push-left approach to security in the upcoming OWASP Testing Guide. If these topics interest you, I encourage you to read, learn, and contribute so more people will make it harder for sensitive data to be found.

Top comments (2)
This is a great article. Very informative and complete. I am learning a lot from your posts on security, so a big thanks!
You’re very welcome! I’m so glad they’re helpful.