Today I came across this Article which talks about, how it is difficult(computationally) to remove duplicate objects from array. The algorithm used is standard and still not very performant on scale, so I thought "can we do better, can we come up with a faster algorithm".
Before our further discussion, let me summarize the original article real quick. Looking at the code sample below, what do you think will be the output of the last line.
let people = [{name: 'vipul', age: 20}, {name: 'vipul', age: 20}];
console.log(people[0] === people[1]);
The answer is false, because objects in JavaScript are reference types, meaning when you compare two objects instead of comparing there keys, there references are compared. Since we are creating new objects inline, we get new references each time, and thus the answer is false.
Introducing Symbols
ES6 added bunch of new features to the JavaScript language which gave us some new cool features to play with. One of those is Symbols, which are really cool and can help us solve out problem better.
Our Faster Algorithm
let arr = [
{
firstName: "Jon",
lastName: "Doe"
},
{
firstName: "example",
lastName: "example"
},
{
firstName: "Jon",
lastName: "Doe"
}
];
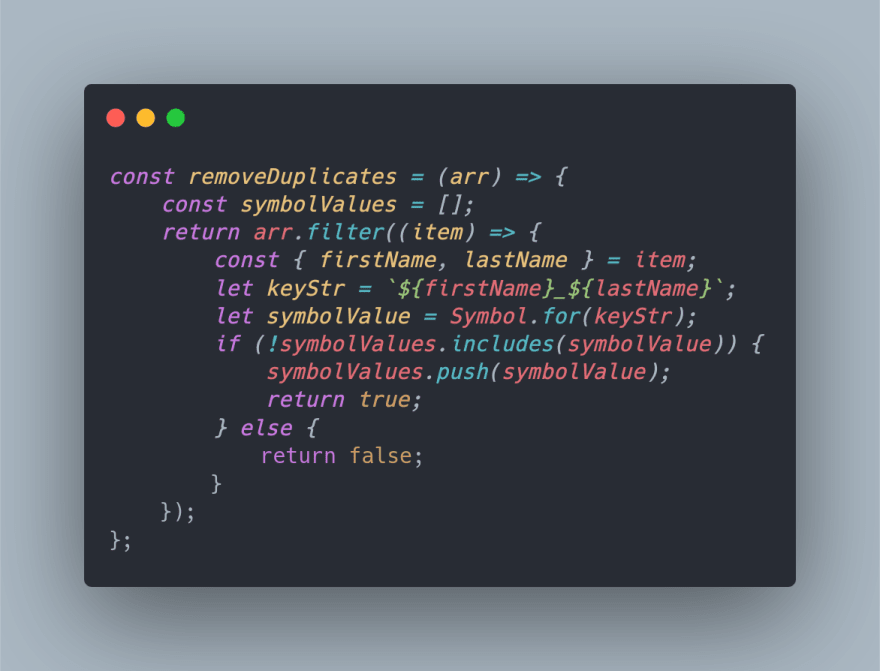
const removeDuplicates = (arr) => {
const symbolValues = [];
return arr.filter((item) => {
const { firstName, lastName } = item;
let keyStr = `${firstName}_${lastName}`;
let symbolValue = Symbol.for(keyStr);
if (!symbolValues.includes(symbolValue)) {
symbolValues.push(symbolValue);
return true;
} else {
return false;
}
});
};
Explanation
In out algorithm, we are using two core features of Symbols
-
Symbol.for(key)returns the same value, for the same key throughout the program. - Symbols can be compared with other Symbols.
First we iterate over the array and create equivalent Symbol values using Symbol.for where the key is a combination of the keys of the object. Then we simply just filter the original array based on conditions of not finding any existing Symbol with the same values.
Benchmarks
I did some tests, just for fun and turns out this solution is pretty scale able too. Here are some of the results
- For 100 elements or so, it takes about 5.5ms where as the approach used in the original article takes 2.2ms.
- For 500 elements or so, it takes 5.7ms whereas the other algorithm takes 11.7ms.
- For 1500 elements or so, it takes 3.886ms whereas the other algorithm takes 32.82ms.
- For 8000 elements or so, it takes 5.57ms whereas the other algorithm takes 60.71ms.
And after that I was obviously bored, so If someone finds this useful and does some testing on a bigger and may be more real world data, I would love to know stats.
If you want to talk more about the implementation or anything else, you can find me on Instagram or Twitter as @vipulbhj
Thank you so much for reading, don’t forget to share If you find the information useful.

Top comments (2)
I found this algorithm helpful.
Thank you.
Glad to hear that ❤️