Someone on reddit requested this and it turned out to be a very fun project. Web scraping data from nba stats is like the dream scenario for a web scraper. It’s just pulling a bunch of data in a simple place.
For this project, we rely on two main packages, axios to handle our promise based http requests and json2csv to convert our json to csv. This is a pretty simple starter project for anyone looking to get into web scraping. If you are looking to start from the beginning, feel free to check out the Learn to Web Scrape series.
Investigation and a gift

Our target is NBA stats. Going there shows a big table of data with ~1250 rows through which you can paginate.
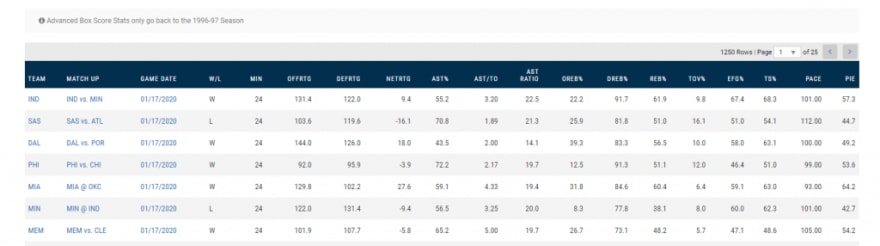
At first I thought that I would have to use puppeteer to extend how many are displayed at once. I noticed there isn’t any kind of results query parameter in the url so it doesn’t look like I can just navigate right to a page with all of the results. This probably means that if I go the puppeteer route I’ll have to hit the right arrow button 25 (dynamically calculated) times.
I decided to dig a bit deeper and check out if by chance all of this was being returned in a nice format in json. This answered my dreams and this project becomes more of a data formatting project than a web scraping one.

Go time

I started off just calling to the url I found in the network tab, https://stats.nba.com/stats/teamgamelogs?DateFrom=&DateTo=&GameSegment=First+Half&LastNGames=0&LeagueID=00&Location=&MeasureType=Advanced&Month=0&OpponentTeamID=0&Outcome=&PORound=0&PaceAdjust=N&PerMode=Totals&Period=0&PlusMinus=N&Rank=N&Season=2019-20&SeasonSegment=&SeasonType=Regular+Season&ShotClockRange=&VsConference=&VsDivision=. I was pretty disappointed when the call just hung, thinking that maybe this wouldn’t be as easy as I expected.
Before I turned to puppeteer, I tried to see what happened if I added a spoofed referer and user-agent.
const url = `https://stats.nba.com/stats/teamgamelogs?DateFrom=&DateTo=&GameSegment=${halves[halfIndex]}&LastNGames=0&LeagueID=00&Location=&MeasureType=Advanced&Month=0&OpponentTeamID=0&Outcome=&PORound=0&PaceAdjust=N&PerMode=Totals&Period=0&PlusMinus=N&Rank=N&Season=2019-20&SeasonSegment=&SeasonType=Regular+Season&ShotClockRange=&VsConference=&VsDivision=`;
const axiosResponse = await axios.get(url, {
headers:
{
'Referer': 'https://stats.nba.com/teams/boxscores-advanced/?Season=2019-20&SeasonType=Regular%20Season&GameSegment=Second%20Half',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36'
}
});
And…voilá. Worked like a charm. It was interesting to me that they made a decision to not handle http requests from someone without the proper referer but didn’t return any kind of error. The request really just hung there. I know backend stuff pretty okay and I feel like that would be a lot of worse on your system than just returning a 403. /shrug.
From here on out it was pretty easy. The request returned two sets of data that I needed, the headers for everything in just an array of strings and then the actual data in an array of arrays.

The code I used looks something like this:
const headers = axiosResponse.data.resultSets[0].headers;
const results = axiosResponse.data.resultSets[0].rowSet;
const games: any[] = [];
for (let i = 0; i < results.length; i++) {
const game: any = {};
const desiredIndice: number[] = [0, 3, 5, 6, 10, 12, 18, 21, 22, 23, 24];
for (let resultsIndex = 0; resultsIndex < results[i].length; resultsIndex++) {
// Use this to get the index for the data you are looking for
// console.log('list of indice', resultsIndex, headers[resultsIndex]);
if (desiredIndice.includes(resultsIndex)) {
game[headers[resultsIndex]] = results[i][resultsIndex];
}
}
games.push(game);
}
const csv = json2csv.parse(games);
fs.writeFile(`nba-stats-${halves[halfIndex]}.csv`, csv, async (err) => {
if (err) {
console.log('err while saving file', err);
}
});
The request from reddit wanted specific fields so I just got the index from the headers section of the fields I wanted them and put them in the desiredIndice array. Then I just loop through all of the fields and if the index was in my array of desiredIndice, I knew that was a field I wanted and I added it: game[headers[resultsIndex]] = results[i][resultsIndex];.
Conclusion
I really enjoyed this project. This was an easy way to get quite a bit of data into some spreadsheets quickly.
If someone was looking to modify the data to get some additional or different fields, they could just get the index of the data and then add it to the desiredIndice array.
Looking for business leads?
Using the techniques talked about here at javascriptwebscrapingguy.com, we’ve been able to launch a way to access awesome business leads. Learn more at Cobalt Intelligence!
The post Jordan Scrapes NBA Stats appeared first on JavaScript Web Scraping Guy.

Top comments (0)